本讲义出自Bikas Saha在Hadoop Summit Tokyo 2016上的演讲,主要分享了如何使得数据科学在企业中变得容易实现以及目前企业中实现数据科学所面临的的挑战,并分享了在企业中如何使用Apache Zeppelin以及企业中数据科学的未来的发展规划。


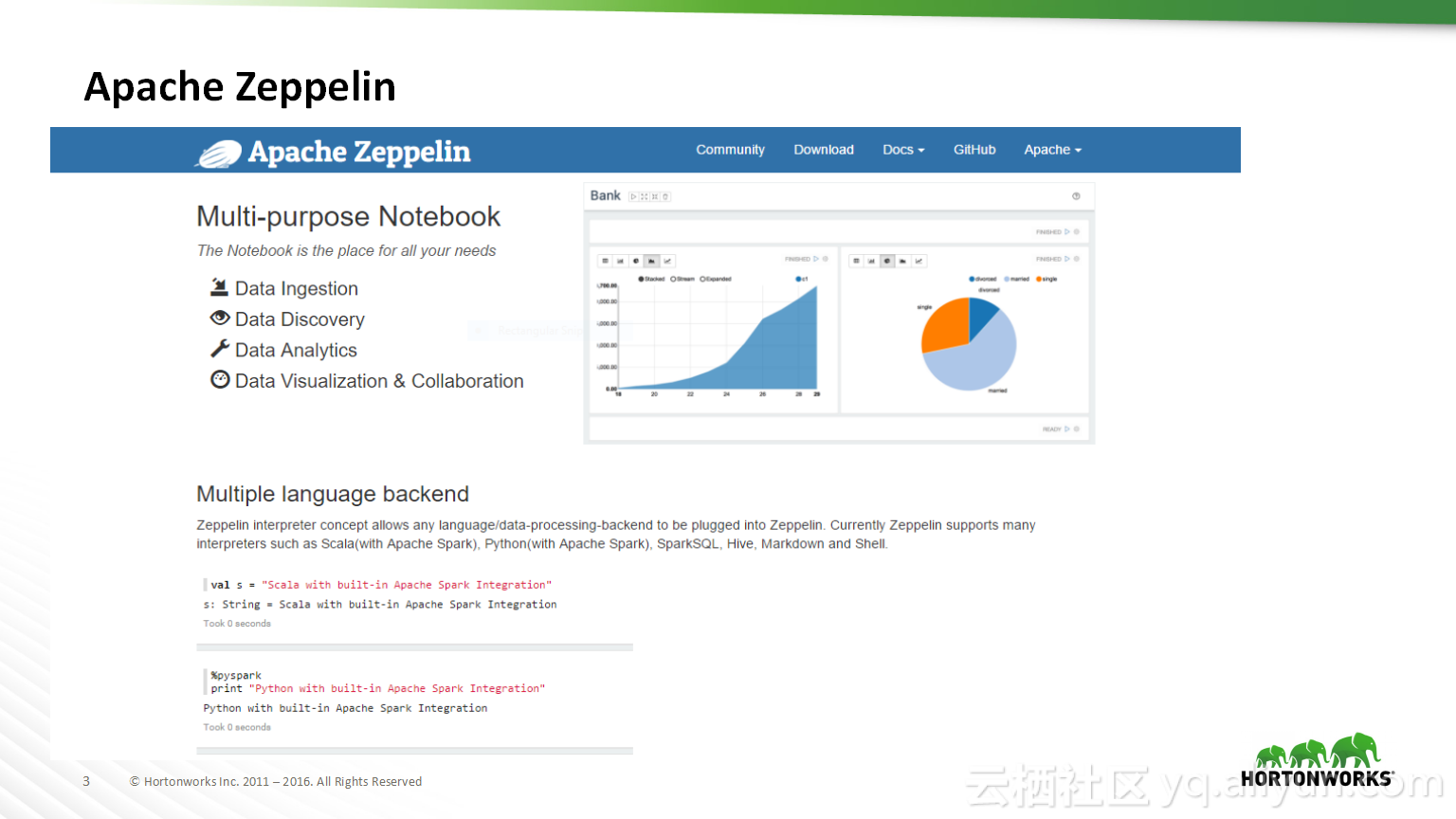

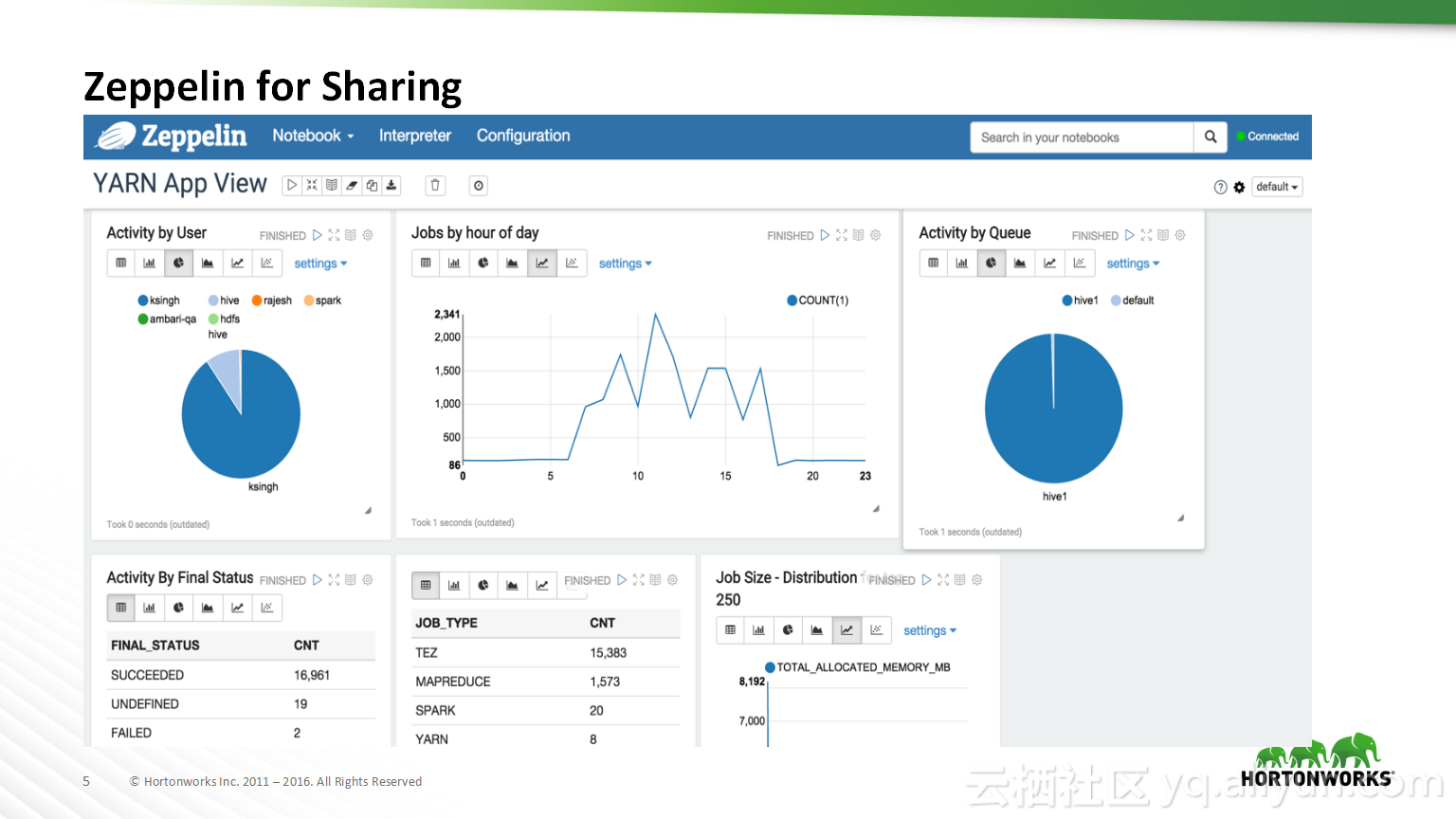

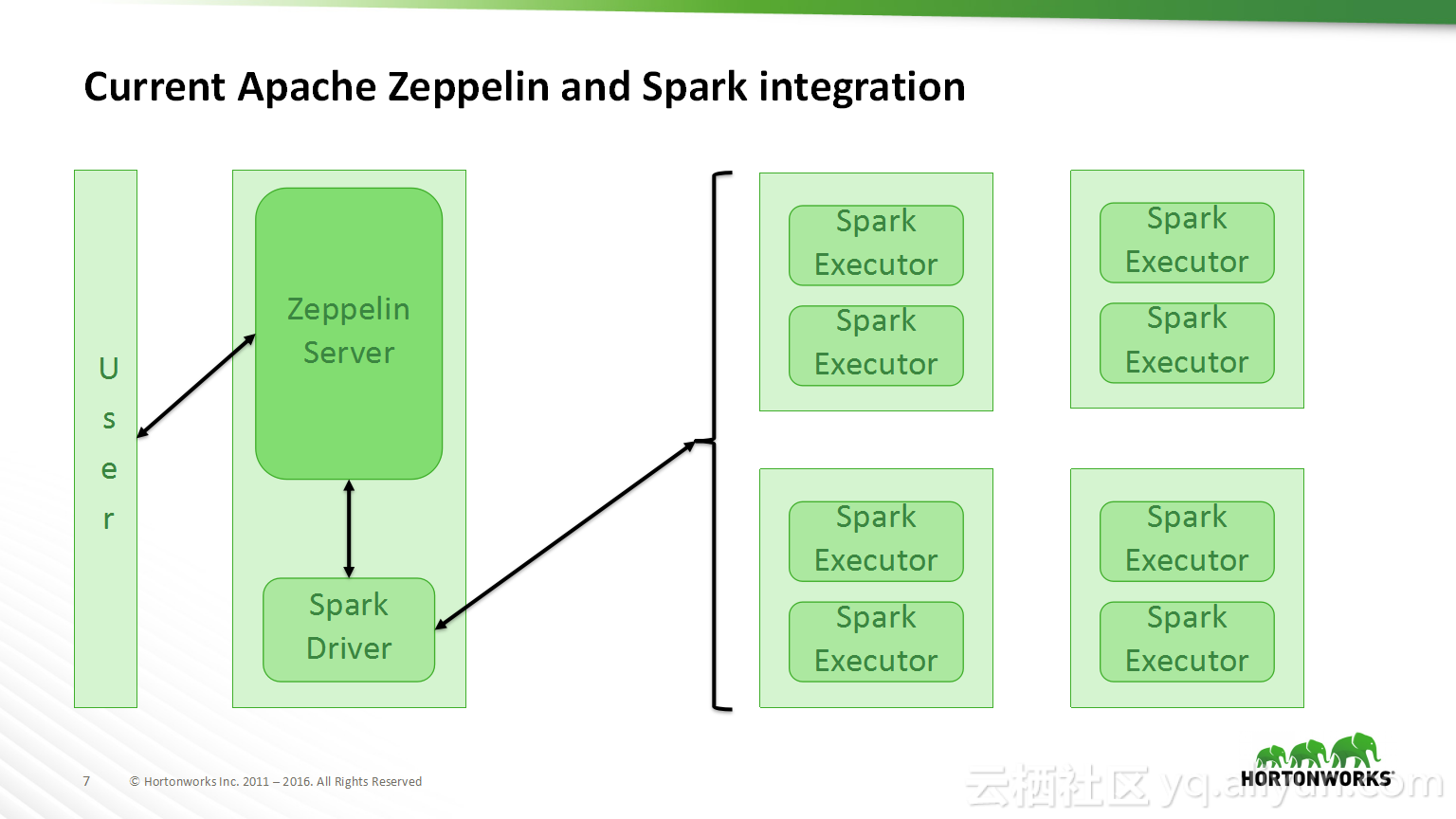
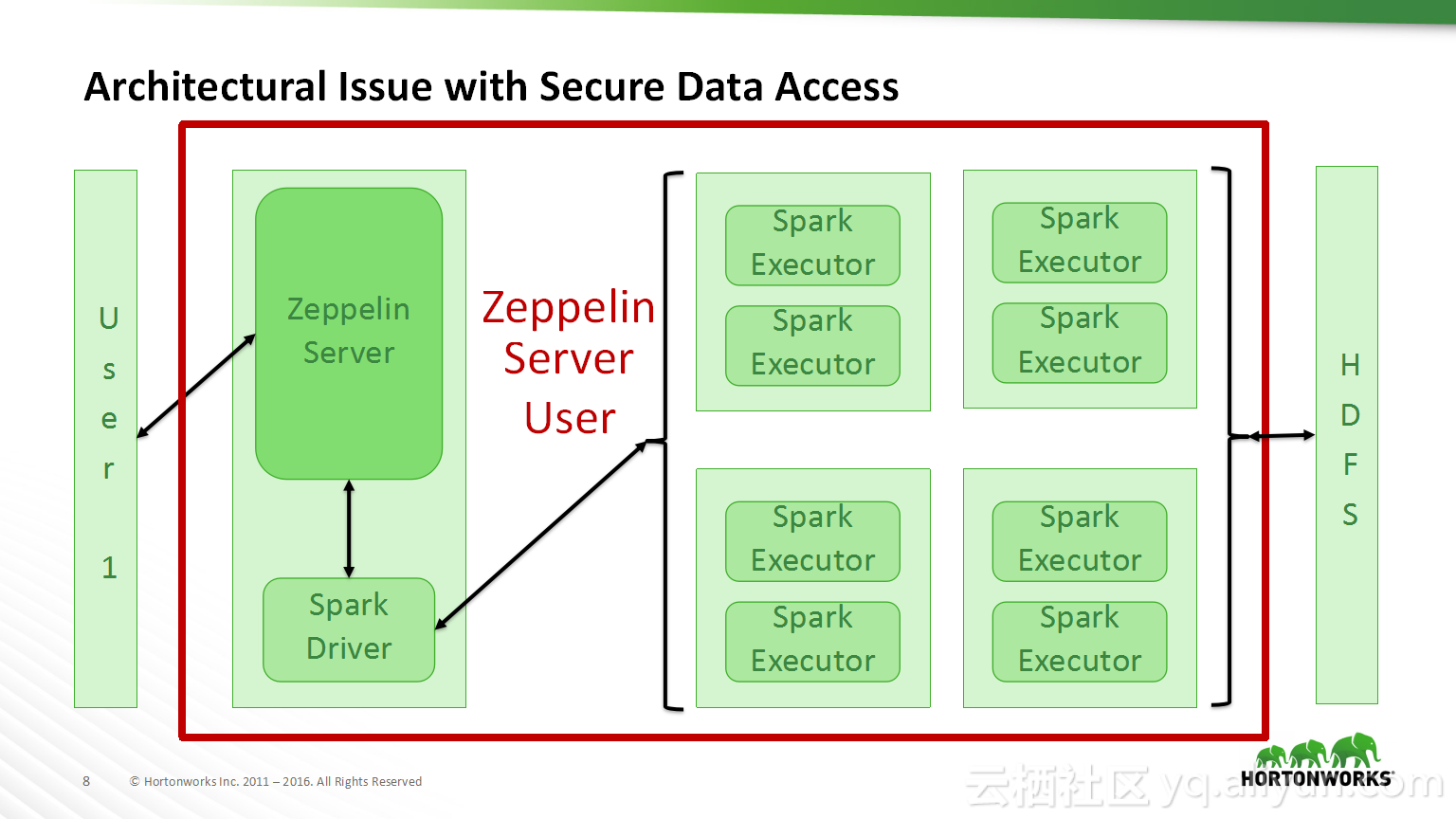
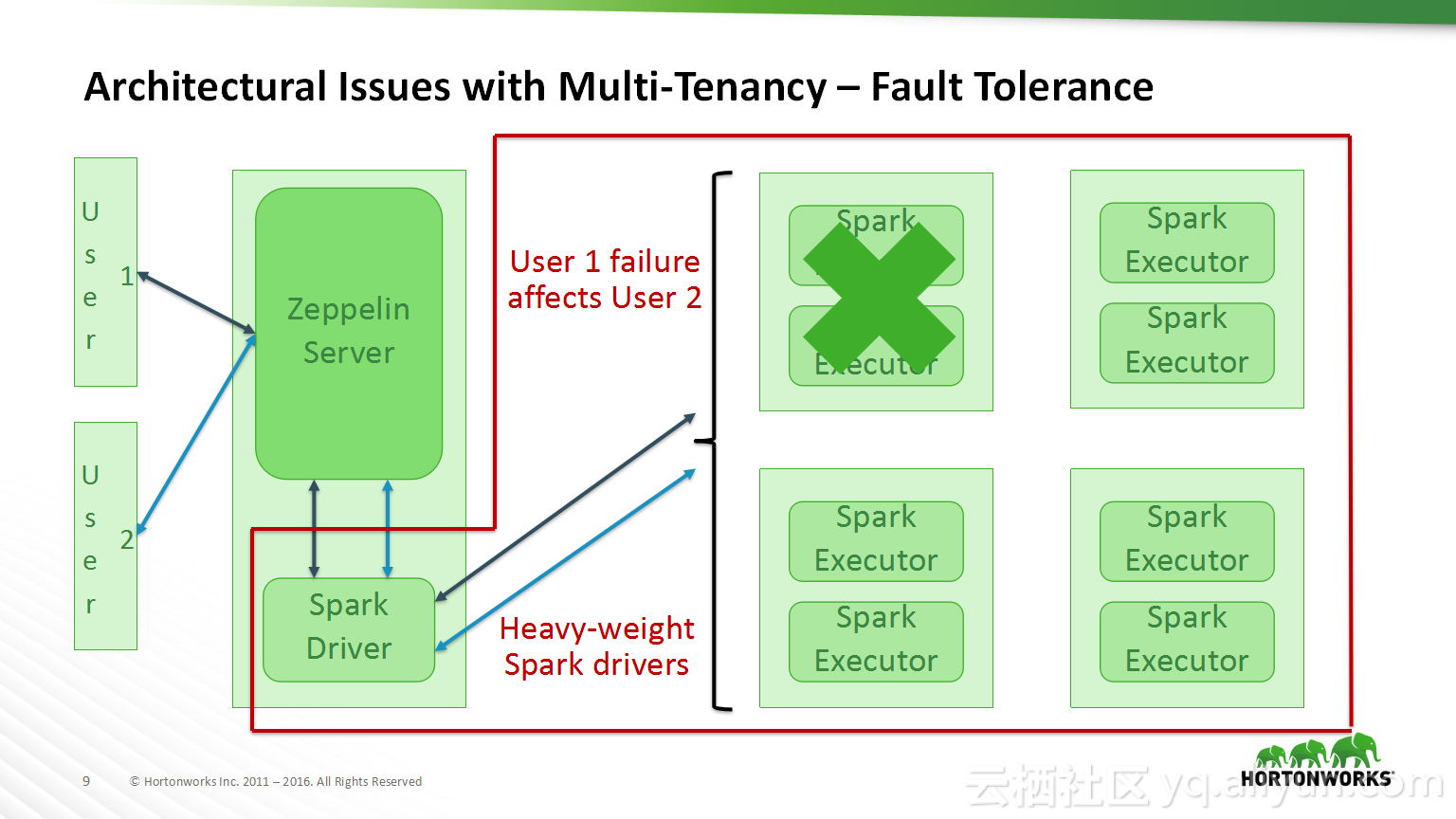
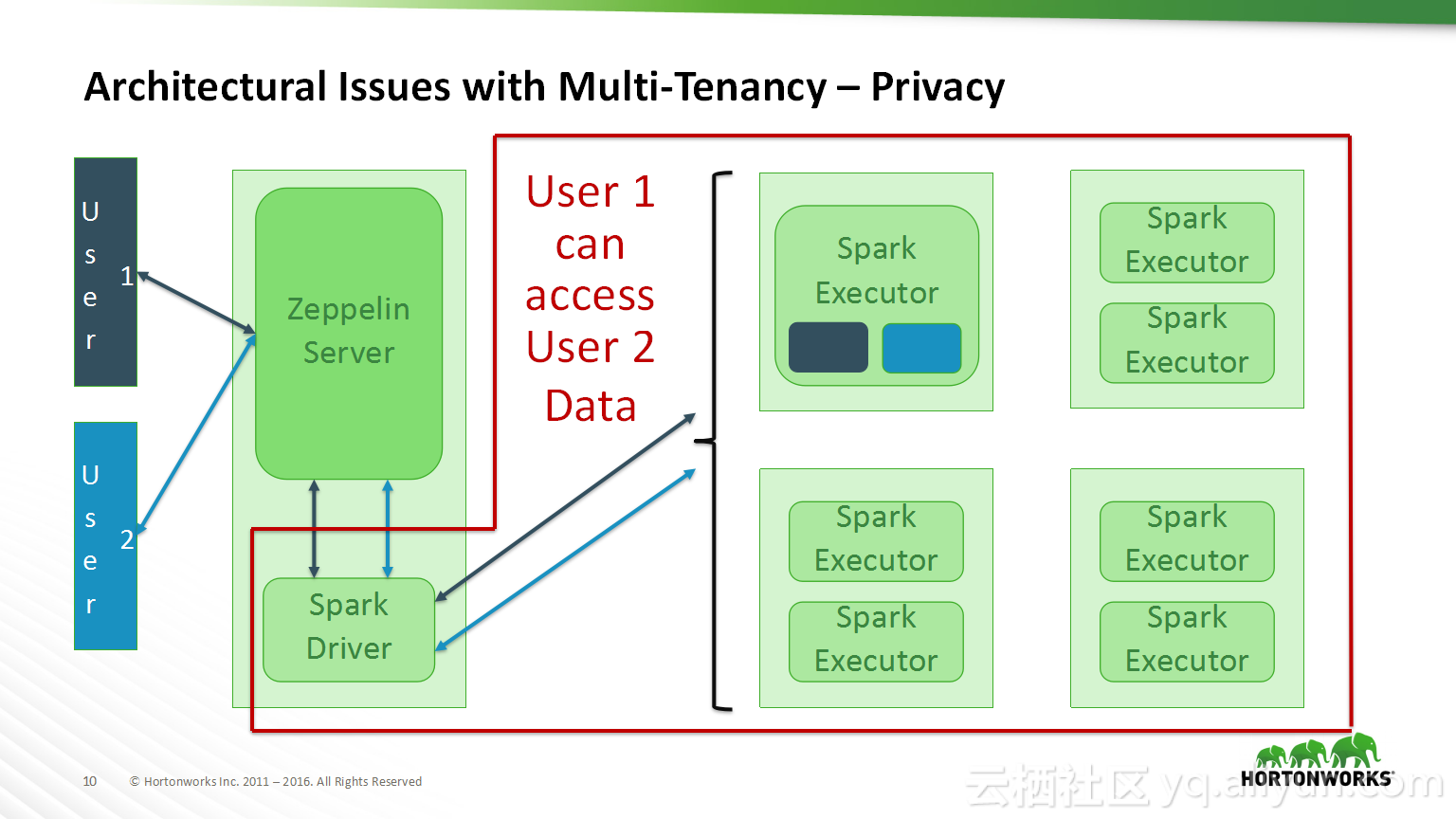

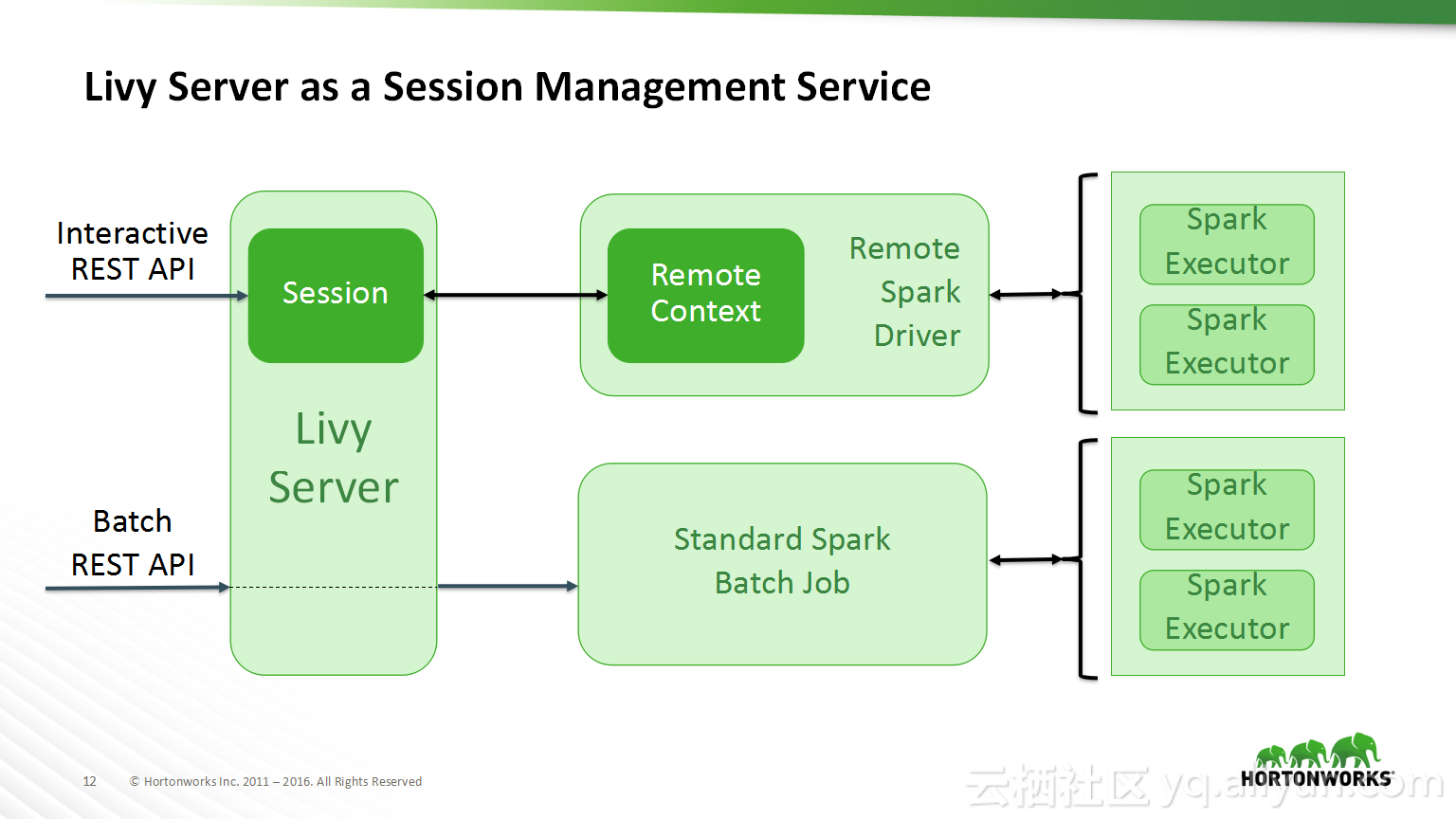
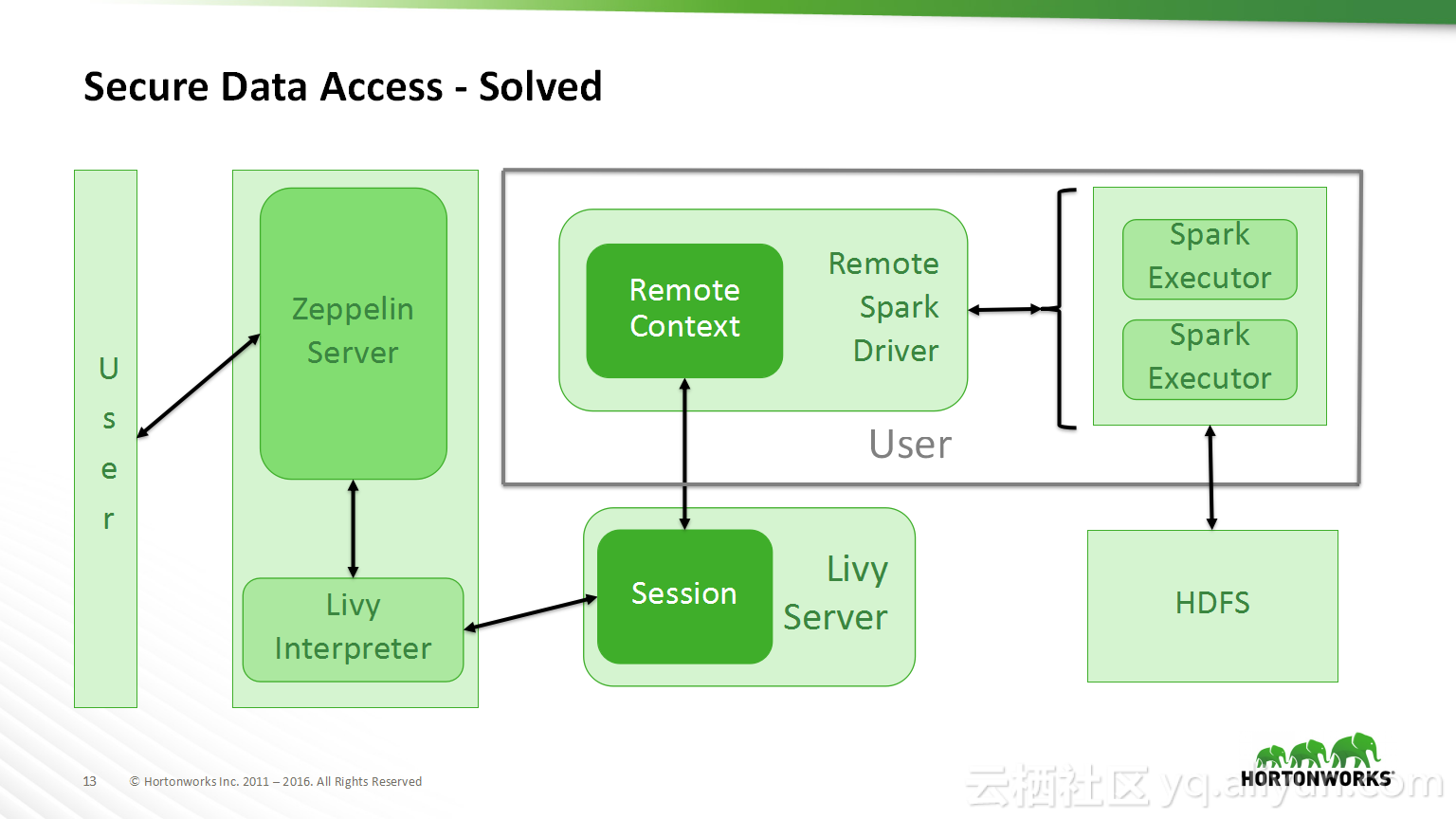
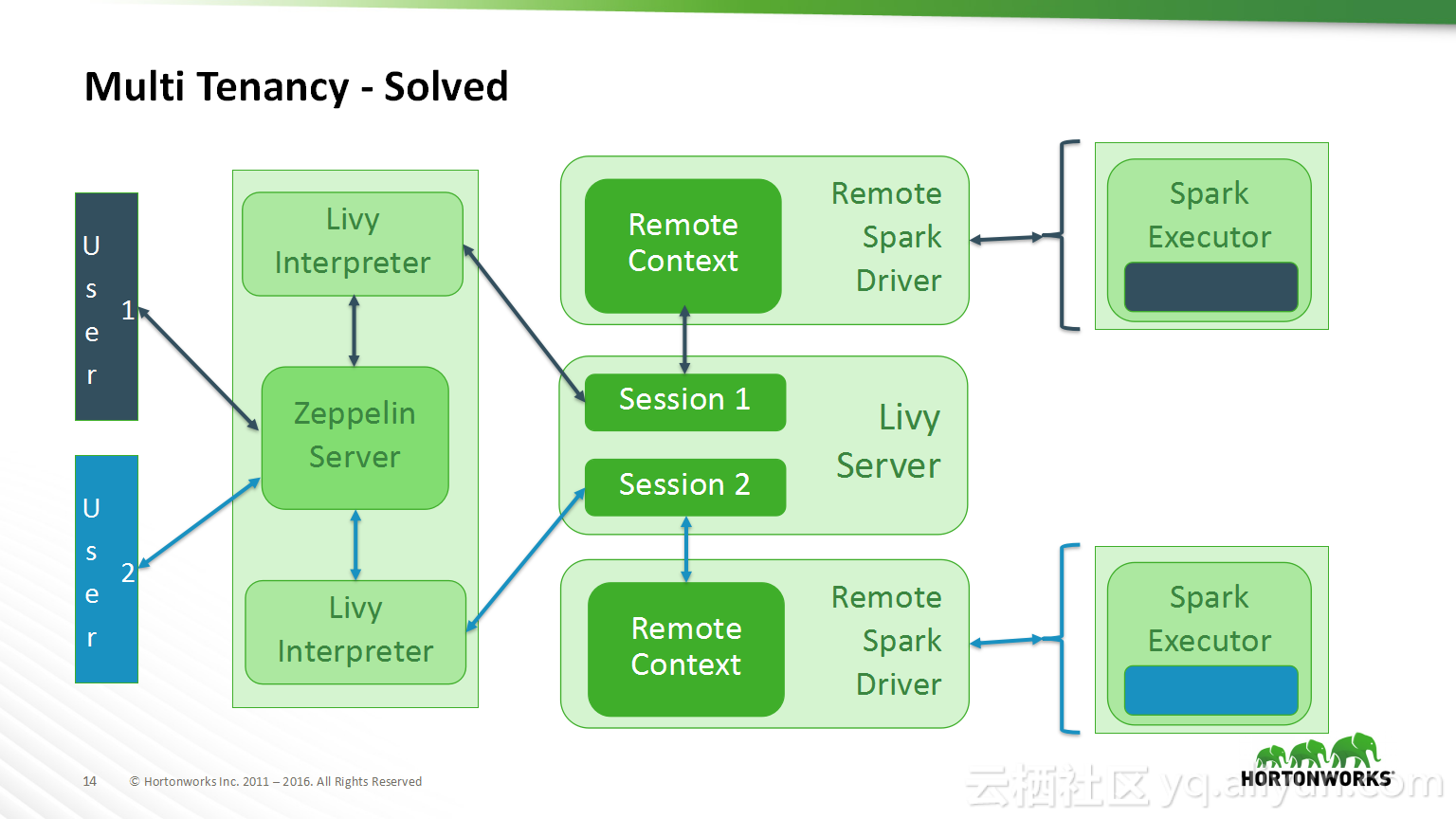




本讲义出自Bikas Saha在Hadoop Summit Tokyo 2016上的演讲,主要分享了如何使得数据科学在企业中变得容易实现以及目前企业中实现数据科学所面临的的挑战,并分享了在企业中如何使用Apache Zeppelin以及企业中数据科学的未来的发展规划。
