导读:
日常生活中存在着各种各样的场景,比如参加晚会、海边度假、跑步、登山、垂钓等等。场景可以认为是在一些维度上相似的元素所构成的情境画面,不同场景会有不同的氛围、组成元素。
穿搭场景是一类重要的场景,淘宝平台上,服饰是很重要的一部分,服饰的穿搭也是场景导购重要的组成部分。本文我们主要介绍穿搭场景。我们抽象出具体场景知识,将重点放在穿搭本身,给用户提供个性化服饰搭配。(本论文由阿里巴巴-浙江大学前沿技术联合研究中心(AZFT) 合著,论文已被收录至ICMR 2018 oral)
ABSTRACT
Intelligent fashion outfit composition becomes more and more popular in these years. Some deep learning based approaches reveal competitive composition recently. However, the uninterpretable characteristic makes such deep learning based approach cannot meet the designers, businesses and consumers’ urge to comprehend the importance of different attributes in an outfit composition. To realize interpretable and customized multi-item fashion outfit compositions, we propose a partitioned embedding network to learn interpretable embeddings from clothing items. The network consists of two vitalcomponents: attribute partition module and partition adversarial module. In the attribute partition module, multiple attribute labels are adopted to ensure that different parts of the overall embedding correspond to different attributes.In the partition adversarial module, adversarial operations are adopted to achieve the independence of different parts. With the interpretable and partitioned embedding, we then construct an outfit composition graph and an attribute matching map. Extensive experiments demonstrate that 1) the partitioned embedding have unmingled parts which corresponding to different attributes and 2) outfits recommended by our model are more desirable incomparison with the existing methods.
1 INTRODUCTION
“Costly thy habit as thy purse can buy, But not expressed in fancy; rich, not gaudy, For the apparel oft proclaims the man.”
——William Shakespeare
Fashion style tells a lot about one’s personality.With the fashion industries going online, clothing fashions are becoming a much more popular topic among the general public. There have been a number of research studies on clothes retrieval and recommendation [8, 9, 12, 19, 37, 40], clothing category classification [4, 20, 30, 38], attribute prediction [1, 2, 5, 15, 39] and clothing fashion analysis [10, 19, 22]. However, due to the fact that the fashion concept is often subtle and subjective, the composition of fashion outfit keeps being an open problem to reach consensus for the general public.
Until now, there are few works [18] studying multi-item fashion outfit composition.Most existing works [4, 13, 14, 23, 25, 29, 33] are proposed to recommend tops (bottoms) to given bottoms (tops). Some early works [4, 13, 14] adopt hand-crafted features to represent items. Those hand-crafted attribute features are usually mixed with other attribute features. Other deep network based works [23, 25, 29, 33] adopt the mixed embedding to represent item of outfit, which is uninterpretable. Very recently, Li et al. [18] present a deep neural networkbased multi-modal method by adopting mixed multi-modal embedding to represent an outfit item as a whole. However, the obtained embedding is uninterpretable anddoes not bring attribute information. Unfortunately, in many practical applications, it is necessary to understand the importance of different attributes in an outfit composition for designers, businesses and consumers. That is to say, an interpretable and partitioned embedding is vital for apractical fashion outfit composition system.
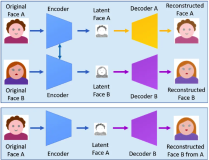
To address the aforementioned problems, we propose apartitioned embedding network in this paper. The network consists of two vital components: attribute partition module and partition adversarial module. In the attribute partition module, multiple attribute labels are adopted to ensure that different parts of the overall embedding correspond to different attributes. In the partition adversarial module, adversarial operations are adopted to achieve independence of different parts. Meanwhile, some indefinable attributes (such as style and occasion) can be extracted by the partition adversarial module. Then, considering that matching items may appear multiple times in different outfits, we propose a fashion composition graph to model matching relationships in outfit with the extracted partitioned embeddings. Meanwhile, an attribute matching map which learns the importance of different attributes in the composition is also built. Comparative framework between our model and the multi-modal embeddings based method [18] is shown in Figure 1.

Figure 1: Comparative framework between our model and Li’s [18] model. Features used by Li’s method are usually mixed and uninterpretable, which lead to uninterpretable outfit composition. Different parts of embedding extracted by our model correspond to different attributes. With the partitioned embedding, our model can recommend outfit composition with interpretable matching scores.
To summarize, our work has three primary contributions: 1) We present a partitioned embedding network, which can extract interpretable partitioned embeddings from fashion outfit items. 2) We putforward a weakly-supervised multi-item fashion outfit composition model, which depends solely on a large number of outfits without quality scores of outfitsas others. Besides, our model can be extended to a dataset with annotated quality scores. 3) An iterative and customized fashion outfit composition scheme is given. Since fashion trends alter directions quickly and dramatically, our model can keep up with the fashion trends by easily incorporating new fashion outfit dataset.
2 RELATED WORK
Clothing embedding. In recent years, there are several models [22, 30, 34] can be used to get embeddings of clothes. Vittayakorn et al. [34] extract five basic feature (color, texture, shape, parse and style) of outfit appearance and concatenated them to form a vector for representing outfit. They use the vector to learning the outfit similarity and analyze visual trends in fashion. Matzenet al. [22] adopt deep learning method to train several attribute classifiers and used high-level features of the trained classifiers to create a visual embedding of clothing style. Then, using the embedding, millions of Instagram photos of people sampled worldwide are analyze to study spatiotemporal trends in clothing around the globe. Simo-Serra et al. [30] train a classifier network with ranking as the constraint to extract discriminative feature representation and also used high level feature of the classifier network as embeddings of fashion style. Kingma et al. [16] introduce a novel estimator of the variational lower bound for approximate inference with continuous latent variables. The continuous latent embedding usually contains mixed and uninterpretable features of original images.
Disentangled embedding. In the supervised setting, supervised methods [17, 26, 35] take the advantage of labeled data and try to disentangle the factors as expected. However, those methods require massive accurate labeled data and the learned disentangle units miss some complicated attribute feature of clothing. In the unsupervised setting, methods [6, 11, 27, 36] can learn interpretable embeddings but fail to anchor a specific meaning into the disentanglement. In the semi-supervised setting, Bouchacourt et al. [3] propose the ML-VAE that can learn disentangled representations from a set of grouped observations. Due to complicated of clothing’s attribute feature, it hard to build grouped observations. Siddharth et al. [28] learn disentangled representations with anauxiliary variable, which also can’t contain all complicated attribute feature of clothing. Most closely with our method, Veit et al. [32] propose Conditional Similarity Networks (CSN) that learn embeddings differentiated into semantically distinct subspaces that capture the different attributes ofsimilarities. However, Veit’s method will need larger number of triplet data when dealing with more attributes.
Fashion outfit composition. As described above, due to the difficulty in modeling outfit composition, there are several works [4, 13, 14, 18, 23, 25, 29, 33] studying fashion outfit composition.Iwata et al. [13] present an approach by concatenating hand-crafted features into a vector as an embedding for each clothing item. Liu et al. [4] developed an occasion oriented clothing recommendation and pairing system, which explores the matching rules of upper and lower-body clothing with specified occasions.Jagadeesh et al. [14] propose four models to discover key fashion insights from large quantities of online fashion images. These works [4, 13, 14] adopt hand-crafted feature to represent attribute features, where the extracted specified hand-crafted attribute features are usually mixed with other attribute features. Oramas et al. [25] present a hierarchical method to discover patterns of co-occurring activations of base-level elements that define visual compatibility between pairs of object classes. McAuley et al. [23] adopt features extracted by Convolutional Neural Network (CNN) to model human preference for the appearance of one item given that of another in terms of more than just the visual similarity between the two. Veit et al. [33] use a Siamese Convolutional Neural Network architecture to learn clothing matching from the Amazon co-purchase dataset, focusing on the representative problem of learning compatible clothing style. Simo-Serra1 et al. [29] introduce a Conditional Random Field to learn the different outfits, types of people and settings. The model is used to predict how fashionable a person looks on aparticular photograph. Very recently, Li et al. [18] use the quality scores as the label and multi-modal embeddings as features to train a grading model. The framework of Li’s approach is shown in Figure 1(a). However, the embeddings extracted by above deep learning based methods [23, 25, 29, 33] and the mixed multi-modal embedding used by Li’s model is uninterpretable, which leads to uninterpretable outfit composition.
3 THE PROPOSED METHOD
To overcome the limitations of existing fashion outfit composition approaches, we propose an interpretable partitioned embedding basedmethod to achieve customized multi-item fashion outfit composition. In this section, the partitioned embedding network is firstly presented to partition an embedding into independent parts which correspond to different attributes. Then, we introduce how to build composition relationship in our proposed composition graph and the attribute map with the interpretable and partitioned embedding.
3.1 Interpretable PartitionedEmbedding
Let I denote anoutfit item, R(I) denote the extracted embedding of I . To make the extracted embedding interpretable and partitionable, there are two constraints to be satisfied: on one hand, the fixed parts of the whole embedding should correspond to specific attributes; on the other hand, different parts of the whole embedding should be mutually independent. Thus, the embedded attribute embedding R(I) of item can be described as below:
Figure 2: The framework of partitioned embedding network. The network consists of two vital components: attribute partition module and partition adversarial module. The attribute partition module is composed of attribute networks Anet 1, Anet 2, Anet 3, which are used to ensure that Part 1', Part 2' and Part 3' of the overall embedding correspond to color, shape and texture attribute, respectively. The partition adversarial module includes adversarial prediction networks Pnet 1, Pnet 2,…, Pnet N and decoder network Dnet. The adversarial prediction networks can ensure that different parts of the whole embedding are independent. The decoder network guarantees that embedding contains all useful information of original clothing item.
3.1.1 Attribute Partition Module. As aforementioned, there are several attributes [20, 22, 34] for describing fashion, such as color, shape, texture, style and so on. To get the importance of attributes in the fashion cloth, we administer a questionnaire among 30 professional stylists. Statistically, attributes are split into 4 classes in the order of color, shape, texture and remaining attributes (style, occasion and others). In Figure 2, Bnet is used to extract an initial embedding of a clothing item, which is uninterpretable. To get interpretable embedding, the attribute partition module is introduced. The attribute partition module is composed of attribute networks Anet 1,Anet 2,Anet 3, which are used to ensure that Part 1', Part 2' and Part 3' of the overall embedding correspond to color, shape and texture attribute, respectively.
Color is a primary element in the fashion outfit composition. To get the color label, we adopt the latest proposed color theme extraction method [7] to extract color themes. This method can extract large span and any number of ranked color themes. We modify it to just extract color in the foreground area of an item. To get an explicit mapping relationship between shape and embedded codes, we adopt the Variational Auto-Encoder model [16] to encode and decode shape information. Texture attribute used in our paper are classified into 6 category: pure, strip, letter, repeating pattern, single pattern and stitching. In total, 100 thousand data are labeled for each category in our paper.
3.1.2 Partition Adversarial Module. With the attribute partition module, Part 1', Part 2' and Part 3' of the initial embedding contain color, shape and texture information, respectively. However, the extracted initial embedding has two drawbacks: different parts of the initial embedding may still mix other attribute information and remaining attribute (style and others) does not have explicitly corresponding part in thewhole embedding.
To address the above problems, our partition adversarial module is introduced. The partition adversarial module includes adversarial prediction networks and decoder network. Decoder network Dnet guarantees that embedding contains all useful information of the original clothing item. Adversarial prediction networks Pnet 1, Pnet 2, …, Pnet N ensure that different parts of whole embedding are independent. Under the influence of decoder network and adversarial prediction networks, the last part of the embedding solely contains the remaining attribute corresponding information.
where β is a balancing parameter, I' is the decoded image of I, Lc (I,I') is the decoded Loss and Ld (r1,r2,…,rN) is mutually independent loss, respectively.
Inspired by the adversarial approach in [27], we adopt adversarial operation to meet the mutually independent constraint. Thus, the mutually independent loss Ld (r1,r2,…,rN) includes predicting loss Lp is and encoding loss Le . In the prediction stage, each prediction net Pnet i tries to predict the corresponding embedding part ri as much as possible to maximize the predictability. The predicted loss Lp can be defined as:
In summary, attribute partition module makes sure that different parts of the whole embedding contain corresponding attribute information. Parts adversarial module ensures that different parts of embedding are only related to corresponding attributes and the last part of embedding contains all remaining attribute information.
3.2 Fashion Outfit Composition
where V is the vertex set of all cluster center Ck, ℇ is the edge set and W is the weight set.
At the initial stage, all vertexes ν∈V have no connections and all weights ω∈W are set to zeros. If item I∈vi and item I'∈vj appear in the same outfit and there is no connection between vi and vj , a connection is created and weight w'ij is set as one. If corresponding vertices vi and vj already have connection, the weight between them will be updated as follow:

where w'ij is the weight in the last stage. Figure 3 shows an example of the connection process.
3.2.2 Attribute Matching Map. In the process of building fashion outfit graph G, an attribute matching map M of different attributes is also built. which is defined as:



where, a'(i,j) is last stage score value. b(i,j)∈B,d(i,j)∈D and t(i,j)∈T are updated in the same way.
After getting the outfit composition graph G and the attribute map M , composition score S of an outfit is defined as follows:

where, η is a balancing parameter, S1 is the weight matching score in composition graph, S2 is attribute matching scores. K is the number of matching weights in outfit ο,σ (w1, w2, …, wK) is variance amongmatching weights wk, k∈{1,2,3,…,K}. To get a matching outfit for an item I , an exhausting algorithm is adopted to search the most matching outfit. In order to reduce time complexity, only top Nc connected items of each category are taken into account.

Figure 3: Fashion outfit composition graph. In the graph, all items are classified into five classes according to the category. For each category, items are clustered into different cluster centers according to attributes’ importance. With these cluster centers as vertexes, edges and weights of fashion composition graph are learned from outfit dataset. Meanwhile, an attribute map are built, which model significance of different attributes.
4 EXPERIMENTS
4.1 Implementation Details
DataSet. Until now, there are many clothing related datasets(such as Hipster Wars [15], Deep Fashion [20], FCDB [1] and so on) as been summarized in [1]. However, the number of validation image in these datasets is insufficient for multi-item outfit composition. As a consequence, we collect a dataset from Polyvore.com, which is the most popular fashion oriented website in the US with tens of thousands of fashion outfits creating every day. In the dataset, fashion outfits are associated with the number of likes and some fashion items. Each fashion item has a corresponding image, category and like. In practical application, an outfit may contain many items, such as tops(blouse, cardigan, sweater, sweatshirt, hoodie, tank, tunic), bottoms (pant,skirt, short), hats, bags, shoes, glasses, watches, jewelry and so on. In this article, we choose five prerequisite categories (tops, bottoms, hats, bags and shoes). Through discarding items that mix human body, we finally get a set of 1.56 million outfits and 7.53 million items.
Network architectures. The number of parts N equals to 4. The basic network Bnet includes four branching networks Bnet1, Bnet2, Bnet3, and Bnet4, which encode color, shape, texture and remaining attribute feature, respectively. In attribute partition module, Anet1, Bnet2 and Anet3 are color, shape and texture attribute extracting network, respectively. Anet 1 is a Generative Adversarial Network architecture, which includes a generative model Gc and a discriminative model Dc. In partition adversarial module, all prediction networks Pnet1, Pnet2, Pnet3, Pnet4 share the same architecture. Let Ci denote a Convolution-BatchNorm-ReLU layer with i filters. CDj denotes a Convolution-BatchNorm-Dropout-ReLU layer with a dropout rate of 30% and j filters. DCk denotes a deconvolution-ReLU layer with k filters, and FCt denotes a Full Connection with t neuron.
All convolutions are 4 × 4 spatial filters with stride 2. Convolutions in both encoder and the discriminator are downsampled by a factor of 2, where as in the decoder they upsample by a factor of 2. Input size of clothing item is 128 × 128 × 3. The size of whole embedding is 400 × 1 and the size of each part is 100×1. All the network architectures are summarized inTable 1. In our experiment, we adopt the Adam optimizer during training. Unless otherwise specified, the learning rate is fixed to be 0.001 and the minibatchsize is 64. Weights are initialized from a Gaussian distribution with mean as 0 and standard deviation as 0.02. Before training the whole network, and have been pre-trained on a small subset of dataset with 50, 000 clothing items. The learning rate of and and are 0.0005, 0.001, 0.007 and 0.0003, respectively.

Table 1: Architecture of allnetworks

4.2 Outfits’ Psycho-VisualTests
To verify the effectiveness of our proposed method, we make a pairwise comparison study. In this experiment, a total of one hundred items are used, along with 20 items for each category. For each item, each method will give an outfit. 30 professional stylists take part in the psychophysical experiment, 13 males and 17 females. In the paired comparison, a stylist is presented with a pair of the recommended outfit. The stylists are asked to choose the most matching composition. All pairs are presented twice to avoid mistakes in individual preferences. The number of pairs is n(n-1)Nb/2, where n is the number of composition methods and No is the total number of test outfits. For each pair, the outfit chosen by an observer is given a score of 1, the other outfit is given a score of 0 and both of them got a score of 0.5 when equally matching. After obtaining the raw data, we converted it to frequency matrix F=(fij)1≪i,j≪n, where the entry fij denotes the score given to composition method j as compared with composition method i. From matrix F, percentage matrix M=(mij)(1≪i,j≪n) is calculated through M=F/Nb, where Nb denotes total number of observations.
To get preference scales from the matrix M, we apply the case V of Thurstone’s law of comparative judgment [31] following Morovic’s thesis [24]. Firstly, alogistic matrix G=(gij)(1≪i,j≪n) is calculated through Equation (11) as

where τ is an arbitrary additive constant (0.5 is also been used in our experiment). Logistic matrix G are then transformed to z-scores matrix Z=(zij)(1≪i,j≪n) by using a simple scaling in the form of Z=λ*G where coefficient λ is determined by linear regression between z-scores and corresponding logistic values. We calculate this value of λ to be 0.5441 with Nb = 3000 observations for each pair of algorithms. From the matrix Z, an accuracy score of composition method i is calculated by averaging the scores of the ith column of the matrix Z. The final matching scores are contained in an interval around 0. The interval can be estimated as ±1.96/√(2Nb ) at the 95% confidence level. The resulting z-scores and confidence intervals for all outfits are shown in Figure 4, where Ours[score] means our method with normalized user favorite scores and GT means the original outfit composition. It is evident that our model performs superiorly to other methods and auto-encoder is the least suitable. The matching scores of five composition methods are −0.7123, −0.1546, 0.1227, 0.2655 and 0.4788 separately with ±0.0253 confidence interval. Figure 6 depicts directly visual comparative results of representative composition outfits. From the figure, we can see that our method get more satisfactory composition results. The method with score label gives a more reasonable composition. It is obvious that our method produces better composition outfit than the other methods.

Figure 4: Score of compositionfor the ranking experiment with all professional stylists.
4.3Tests on E-commerce Platform
To further validate the effectiveness of our proposed method. We test our outfit composition result on word famous e-commerce platform. In this part, we compare outfits generated by our method with original outfits and outfits generated by other two methods. For each category of item, five thousands outfits are generated with each method. Then, total 125 thousand outfits are exhibited on the e-commerce platform with 500 thousand pageview (PV). The average click-through rate (CTR) and the average second click-through rate (SCTR) are shown in Table 2, where we can see that original outfit composition (GT) has the highest CTR and SCTR. What’s more, CTR and SCTR of our method are higher than the other two methods, which proves that our method can generate more desirable outfit than other two methods.
4.4Validity of Partitioned Embedding
To validate the discriminative ability of embedding partitioned by our method, we compare with other two embeddings: hand-crafted features used in Vittayakorn’s method [34] and embedding extracted by Veit’s CSN [32]. In this part, we visualize the shape space of three shape embeddings using t-SNE [21], which is shown in Figure 5. For each visualized map, a dense region and a common region are magnified with red bounding boxes. From Figure 5(c), we can see that hats in the red bounding box share same shape and vary color and texture. However, hats in the red bounding box of Vittayakorn’s and Veit’s visualized map are usually mixed with different shape, which indicates that shape embedding extracted by our method is more unmingled that other two methods.

Figure 5: Visualization of theshape space of hand-crafted shape features used in Vittayakorn’s method [34], shape embedding extracted by Veit’s CSN [32] and our partitioned shapeembedding using t-SNE [21].

Figure 7: Outfit compositionwith user specify attribute (color, shape or texture).
4.5Personalized Attributes Composition
In the stage of building composition graph, we cluster the attributes corresponding parts of embeddings into different level cluster centers as vertexes in the graph. In the testing stage, users can specify their preferred attribute, such as “color=red”, “shape=circle” or “texture=strip”, our model can give a series of specified attribute items with interpretable matching scores for users to choose. Figure 7 shows some ordered recommended matching items with six composition scores. For example, sum composition score of the recommended hat in the green box is 65.46. Weight composition score in the blue box is 16.45. Attributes matching scores corresponding to color, shape, texture and remaining attribute are 14.36, 11.74, 13.59 and 9.32, respectively. From attribute matching scores in the red bounding box, we can see that color and texture attributes give more contribution to the final composition than other attributes. Meanwhile, for the user specified attribute, the recommended items are satisfactory with user preference.
4.6 Outfit Composition’s Extension
As described above, our fashion composition graph is weakly supervised. Our model can also be extended to a dataset with matching score labels. After normalizing the user favorite scores, the fashion composition graph with the score is built using Eq.(7) by setting ρ to the normalized score. Outfit composition result with normalized scores are given in Table 2, Figure 6 and Figure 4.

Figure 6: Composition visualcomparison among different methods.
Table 2: CTR & SCTR forthe test outfits

The fashion trends are known for its quick and dogmatical variation [1]. The proposed technique enables us to keep up with the fashion trend along time. When new trend outfit dataset joints, old W of composition graph is divided by √(Nm ), where Nm is the max weight of the graph. Then, the fashion composition graph is updated following Eq.(7) with ρ > 1. In the experiments, we classify our whole outfit dataset into four groups according to years: dataset1 (2007− 2009), dataset2 (2010−2012), dataset3 (2013−2015), dataset4 (2016−2017). We use our proposed iterated model with dataset1 (2007−2009) as the basic dataset to get initial outfit composition graph. Then, by constantly adding new dataset into the basic dataset, we can get new outfit composition graph, by which fashion trend is kept up with. Figure 8 gives the visual most popular outfit along years. We can see that our iterated model can keep up with fashion trends tightly.

Figure 8:Fashion trends with different years.
5 CONCLUSION
Fashion style tells a lot about one’s personality. Interpretable embeddings of items are fatal in design, market and clothing retrieval. In this paper, we propose a partitioned embedding network, which can extract interpretable partitioned embedding from clothing items. The network consists of two vital components: attribute partition module and partition adversarial module. In the attribute partition module, multiple attribute labels are adopted to ensure that different parts of the overall embedding correspond to different attributes. In the partition adversarial module, adversarial predicted networks and encoded network are adopted to achieve the independence of different parts. Then, using the extracted partitioned embeddings, a composition graph and an attribute matching map are built. When users specify their preference attributes, such as color and shape, our model can recommend desirable outfit with interpretable attribute matching scores. In practice, people’s skin color and stature have great influence on the outfit composition. Thus, personalization would be taken into consideration in our future work.
REFERENCES
[1] Kaori Abe, Teppei Suzuki, Shunya Ueta, Akio Nakamura, Yutaka Satoh, andHirokatsu Kataoka. 2017. Changing Fashion Cultures. arXiv preprintarXiv:1703.07920 (2017).
[2] Lukas Bossard, Matthias Dantone, Christian Leistner, Christian Wengert,Till Quack, and Luc Van Gool. 2012. Apparel classification with style. In Asianconference on computer vision. Springer, 321–335.
[3] Diane Bouchacourt, Ryota Tomioka, and Sebastian Nowozin. 2017.Multi-level variational autoencoder: Learning disentangled representations fromgrouped observations. arXiv preprint arXiv:1705.08841 (2017).
[4] Huizhong Chen, Andrew Gallagher, and Bernd Girod. 2012. Describingclothing by semantic attributes. Computer Vision– ECCV 2012 (2012), 609–623.
[5] Qiang Chen, Junshi Huang, Rogerio Feris, Lisa M Brown, Jian Dong, andShuicheng Yan. 2015. Deep domain adaptation for describing people based onfine-grained clothing attributes. In Proceedings of the IEEE conference oncomputer vision and pattern recognition. 5315–5324.
[6] Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, andPieter Abbeel. 2016. Infogan: Interpretable rep- resentation learning by informationmaximizing generative adversarial nets. In Advances in Neural InformationProcessing Systems. 2172–2180.
[7] Zunlei Feng, Wolong Yuan, Chunli Fu, Jie Lei, and Mingli Song. 2017.Finding intrinsic color themes in images with human visual perception.Neurocomputing (2017).
[8] Jianlong Fu, Jinqiao Wang, Zechao Li, Min Xu, and Hanqing Lu. 2012.Efficient clothing retrieval with semantic-preserving visual phrases. In AsianConference on Computer Vision. Springer, 420–431.
[9] M Hadi Kiapour, Xufeng Han, Svetlana Lazebnik, Alexander C Berg, andTamara L Berg. 2015. Where to buy it: Matching street clothing photos in onlineshops. In Proceedings of the IEEE International Conference on Computer Vision.3343–3351.
[10] Ruining He and Julian McAuley. 2016. Ups and downs: Modeling the visualevolution of fashion trends with one-class collaborative filtering. Inproceedings of the 25th international conference on world wide web.International World Wide Web Conferences Steering Committee, 507–517.
[11] Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, XavierGlorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. 2016. betavae:Learning basic visual concepts with a constrained variational framework.(2016).
[12] Junshi Huang, Rogerio S Feris, Qiang Chen, and Shuicheng Yan. 2015.Cross-domain image retrieval with a dual attribute-aware ranking network. InProceedings of the IEEE International Conference on Computer Vision. 1062–1070.
[13] Tomoharu Iwata, Shinji Wanatabe, and Hiroshi Sawada. 2011. Fashioncoordinates recommender system using photographs from fashion magazines. InIJCAI, Vol. 22. 2262.
[14] Vignesh Jagadeesh, Robinson Piramuthu, Anurag Bhardwaj, Wei Di, and Neel Sundaresan.2014. Large scale visual recommendations from street fashion images. InProceedings of the 20th ACM SIGKDD international conference on Knowledgediscovery and data mining. ACM, 1925–1934.
[15] M Hadi Kiapour, Kota Yamaguchi, Alexander C Berg, and Tamara L Berg.2014. Hipster wars: Discovering elements of fashion styles. In Europeanconference on computer vision. Springer, 472–488.
[16] Diederik P Kingma and Max Welling. 2014. Auto-Encoding Variational Bayes.stat 1050 (2014), 1.
[17] Tejas D Kulkarni, William F Whitney, Pushmeet Kohli, and Josh Tenenbaum.2015. Deep convolutional inverse graphics network. In Advances in NeuralInformation Processing Systems. 2539– 2547.
[18] Yuncheng Li, Liangliang Cao, Jiang Zhu, and Jiebo Luo. 2017. Mining FashionOutfit Composition Using An End-to-End Deep Learning Approach on Set Data. IEEETransactions on Multi-media (2017).
[19] Qiang Liu, Shu Wu, and Liang Wang. 2017. DeepStyle: Learning UserPreferences for Visual Recommendation. In Proceedings of the 40th InternationalACM SIGIR Conference on Research and Development in Information Retrieval. ACM,841–844.
[20]Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. 2016.Deepfashion: Powering robust clothes recognition and retrieval with rich annotations.In Proceedings of the IEEE Conference on Computer Vision and PatternRecognition. 1096–1104.
[21]Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE.Journal of machine learning research 9, Nov (2008), 2579–2605.
[22] KevinMatzen, Kavita Bala, and Noah Snavely. 2017. Street-Style: Exploring world-wideclothing styles from millions of photos. arXiv preprint arXiv:1706.01869(2017).
[23]Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel. 2015.Image-based recommendations on styles and substitutes. In Proceedings of the38th International ACM SIGIR Conference on Research and Development in InformationRetrieval. ACM, 43–52.
[24]Jan Morovic. 1998. To develop a universal gamut mapping algorithm. (1998).
[25]Jose Oramas and Tinne Tuytelaars. 2016. Modeling visual compatibility throughhierarchical mid-level elements. arXiv preprint arXiv:1604.00036 (2016).
[26] GuimPerarnau, Joost van de Weijer, Bogdan Raducanu, and Jose M A ́lvarez. 2016.Invertible conditional gans for image editing. arXiv preprint arXiv:1611.06355(2016).
[27] Jürgen Schmidhuber. 2008. Learning factorial codes by predictabilityminimization. Learning 4, 6 (2008).
[28] NSiddharth, Brooks Paige, Alban Desmaison, JanWillem van de Meent, Frank Wood,Noah D Goodman, Pushmeet Kohli, and Philip HS Torr. 2016. Learning DisentangledRepresentations in Deep Generative Models. (2016).
[29] EdgarSimo-Serra, Sanja Fidler, Francesc Moreno-Noguer, and Raquel Urtasun. 2015. Neuroaestheticsin fashion: Modeling the perception of fashionability. In Proceedings of the IEEEConference on Computer Vision and Pattern Recognition. 869–877.
[30] EdgarSimo-Serra and Hiroshi Ishikawa. 2016. Fashion style in 128 floats: Jointranking and classification using weak data for feature extraction. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition.298–307.
[31] LouisL Thurstone. 1927. A law of comparative judgment. Psychological review 34, 4(1927), 273.
[32] AndreasVeit, Serge Belongie, and Theofanis Karaletsos. 2017. Conditional similaritynetworks. Computer Vision and Pattern Recognition (CVPR 2017) (2017).
[33] AndreasVeit, Balazs Kovacs, Sean Bell, Julian McAuley, Kavita Bala, and SergeBelongie. 2015. Learning visual clothing style with heterogeneous dyadicco-occurrences. In Proceedings of the IEEE International Conference on ComputerVision. 4642– 4650.
[34] SirionVittayakorn, Kota Yamaguchi, Alexander C Berg, and Tamara L Berg. 2015. Runwayto realway: Visual analysis of fashion. In Applications of Computer Vision(WACV), 2015 IEEE Winter Conference on. IEEE, 951–958.
[35] ChaoyueWang, Chaohui Wang, Chang Xu, and Dacheng Tao. 2017. Tag disentangled generativeadversarial network for object image re-rendering. In Proceedings of theTwenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI.2901–2907.
[36] XiaolongWang and Abhinav Gupta. 2016. Generative image modeling using style and structureadversarial networks. In European Conference on Computer Vision. Springer,318–335.
[37]Xianwang Wang and Tong Zhang. 2011. Clothes search in consumer photos via colormatching and attribute learning. In Proceedings of the 19th ACM internationalconference on Multi-media. ACM, 1353–1356.
[38]Kota Yamaguchi, M Hadi Kiapour, Luis E Ortiz, and Tamara L Berg. 2012. Parsingclothing in fashion photographs. In Computer Vision and Pattern Recognition(CVPR), 2012 IEEE Conference on. IEEE, 3570–3577.
[39]Kota Yamaguchi, Takayuki Okatani, Kyoko Sudo, Kazuhiko Murasaki, and YukinobuTaniguchi. 2015. Mix and Match: Joint Model for Clothing and AttributeRecognition.. In BMVC. 51–1.
[40]Zhengzhong Zhou, Yifei Xu, Jingjin Zhou, and Liqing Zhang. 2016. InteractiveImage Search for Clothing Recommendation. In Proceedings of the 2016 ACM onMultimedia Conference. ACM, 754–756.