产品
解决方案
文档与社区
权益中心
定价
云市场
合作伙伴
支持与服务
了解阿里云
备案
控制台
开发者社区
首页
探索云世界
探索云世界
云上快速入门,热门云上应用快速查找
了解更多
问产品
动手实践
考认证
TIANCHI大赛
活动广场
活动广场
丰富的线上&线下活动,深入探索云世界
任务中心
做任务,得社区积分和周边
高校计划
让每位学生受益于普惠算力
训练营
资深技术专家手把手带教
话题
畅聊无限,分享你的技术见解
开发者评测
最真实的开发者用云体验
乘风者计划
让创作激发创新
阿里云MVP
遇见技术追梦人
直播
技术交流,直击现场
下载
下载
海量开发者使用工具、手册,免费下载
镜像站
极速、全面、稳定、安全的开源镜像
技术资料
开发手册、白皮书、案例集等实战精华
插件
为开发者定制的Chrome浏览器插件
探索云世界
新手上云
云上应用构建
云上数据管理
云上探索人工智能
云计算
弹性计算
无影
存储
网络
倚天
云原生
容器
serverless
中间件
微服务
可观测
消息队列
数据库
关系型数据库
NoSQL数据库
数据仓库
数据管理工具
PolarDB开源
向量数据库
热门
Modelscope模型即服务
弹性计算
云原生
数据库
物联网
云效DevOps
龙蜥操作系统
平头哥
钉钉开放平台
大数据
大数据计算
实时数仓Hologres
实时计算Flink
E-MapReduce
DataWorks
Elasticsearch
机器学习平台PAI
智能搜索推荐
人工智能
机器学习平台PAI
视觉智能开放平台
智能语音交互
自然语言处理
多模态模型
pythonsdk
通用模型
开发与运维
云效DevOps
钉钉宜搭
支持服务
镜像站
码上公益
开发者社区
大数据
文章
正文
【Hadoop Summit Tokyo 2016】将HDFS演进成广义分布式存储子系统
2017-02-26
2350
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《
阿里云开发者社区用户服务协议
》和 《
阿里云开发者社区知识产权保护指引
》。如果您发现本社区中有涉嫌抄袭的内容,填写
侵权投诉表单
进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
简介:
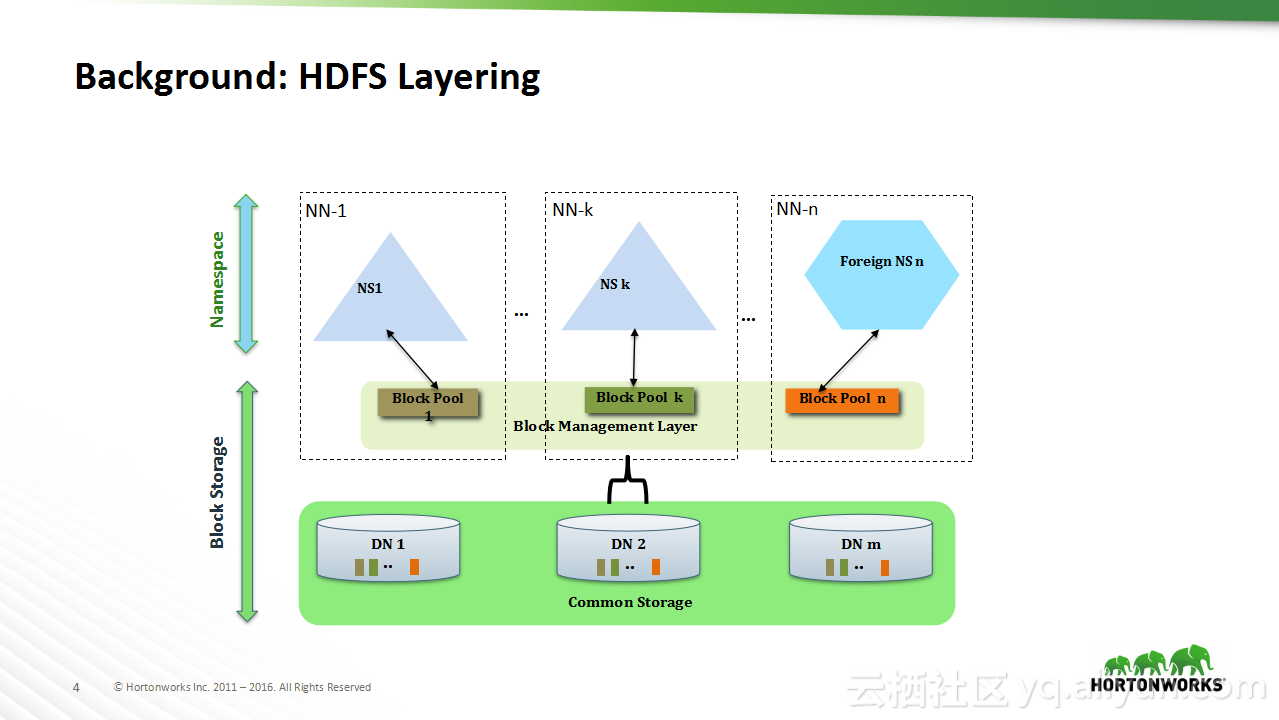
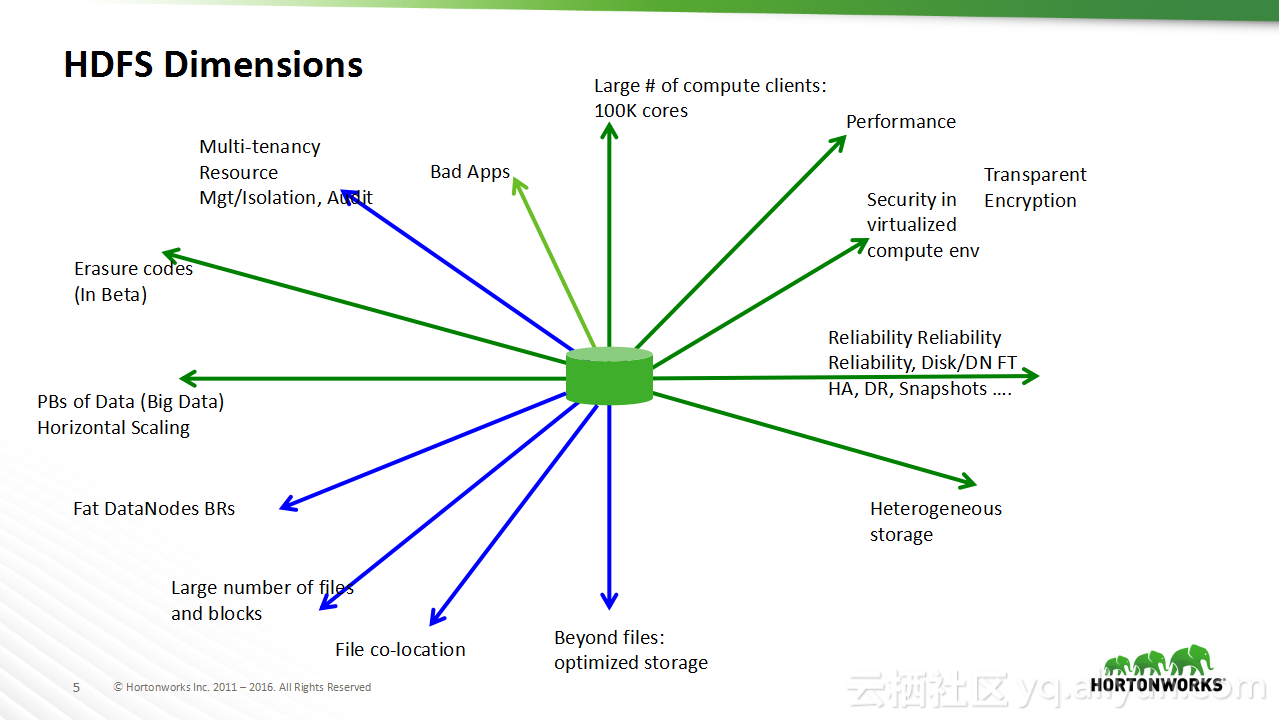
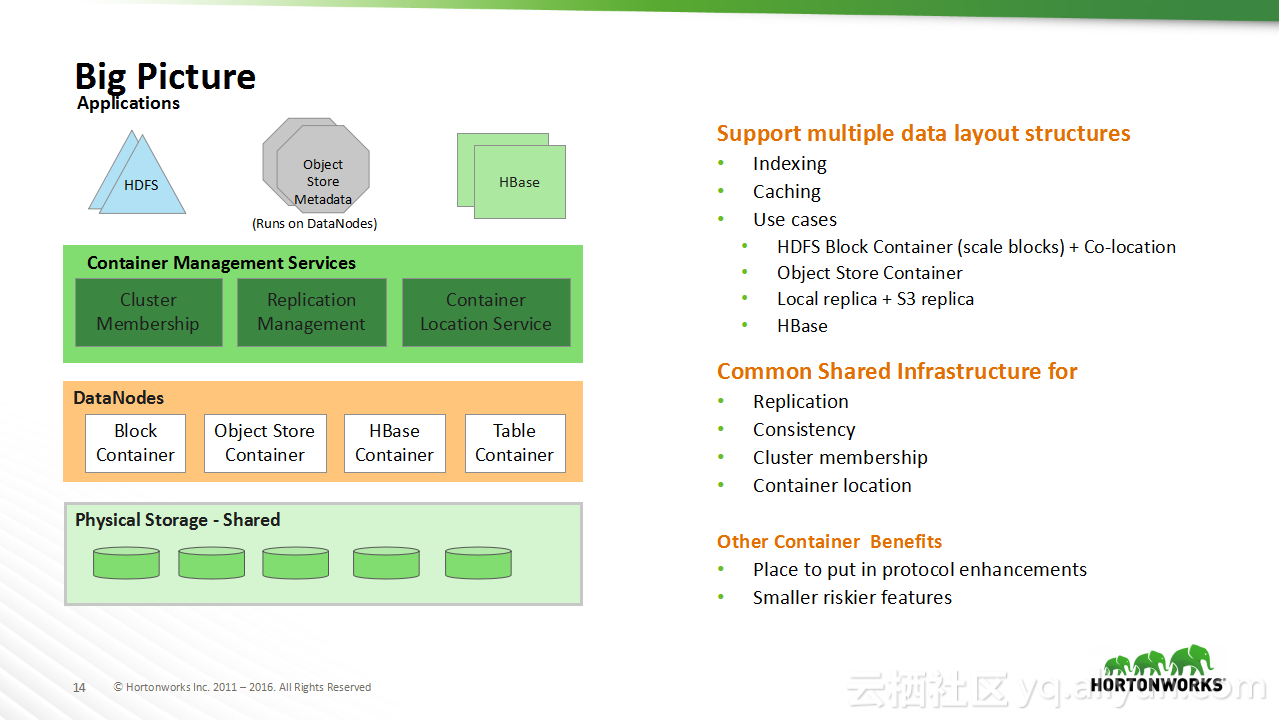
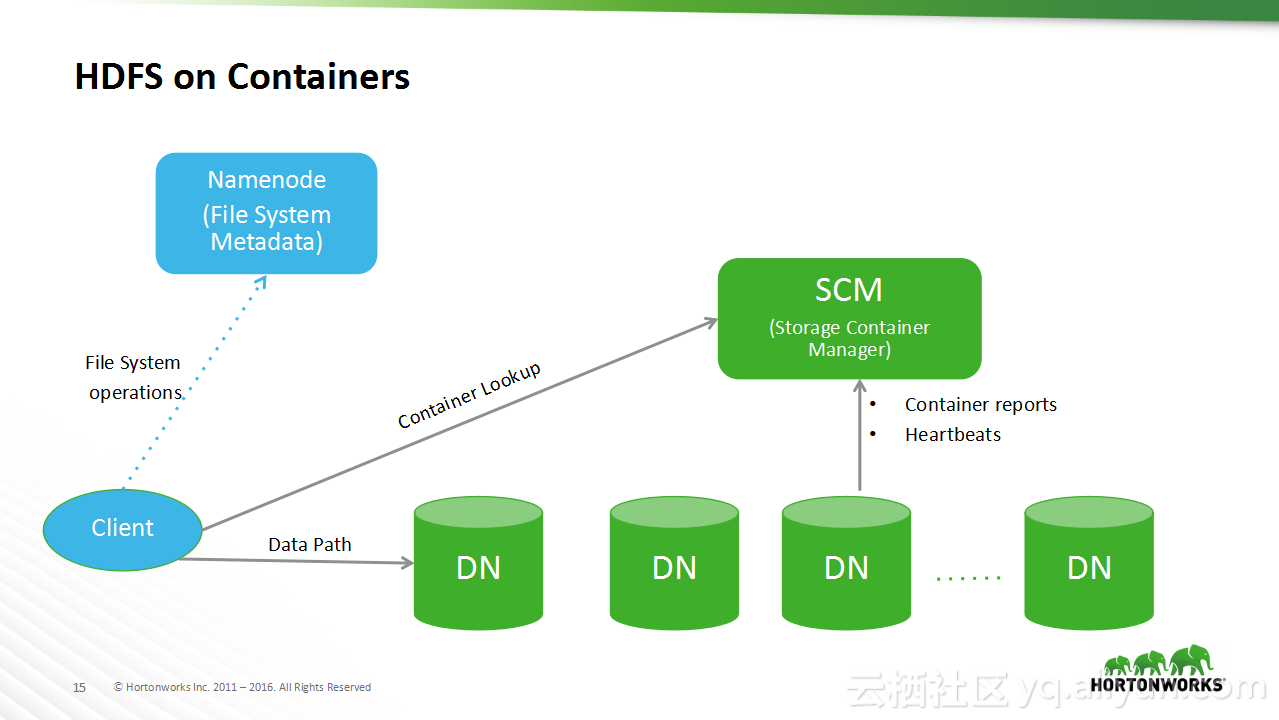
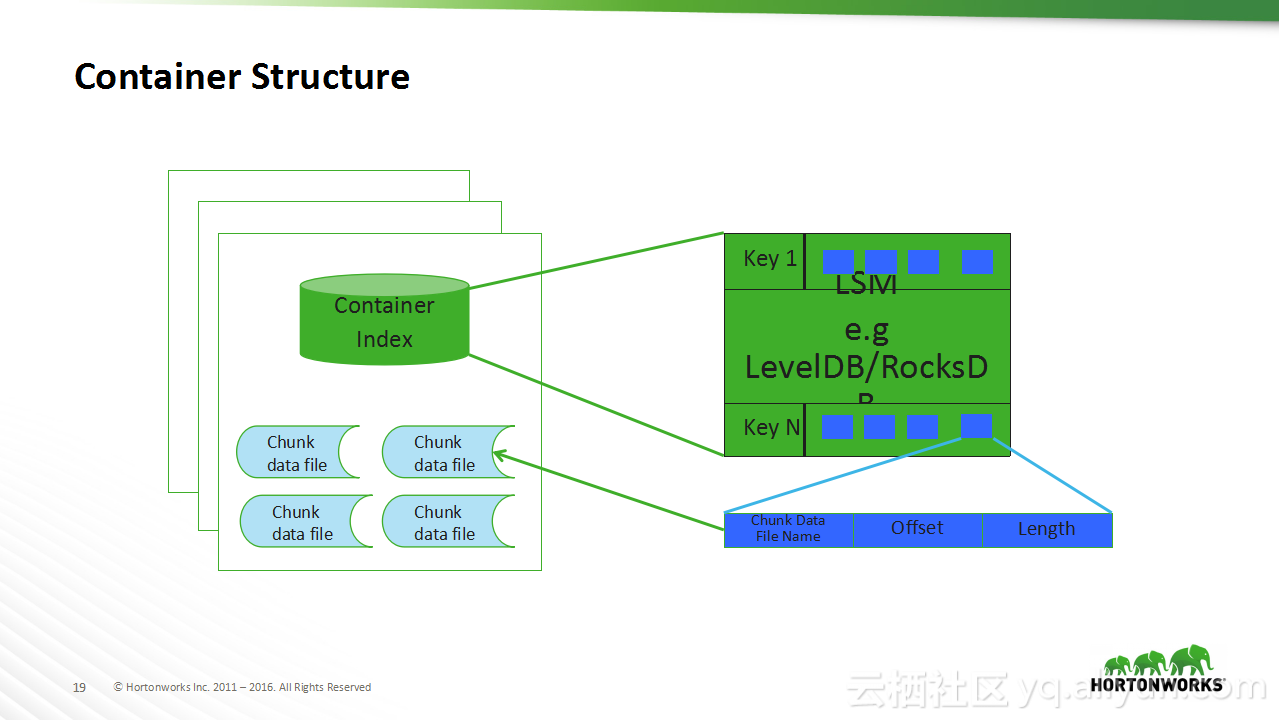
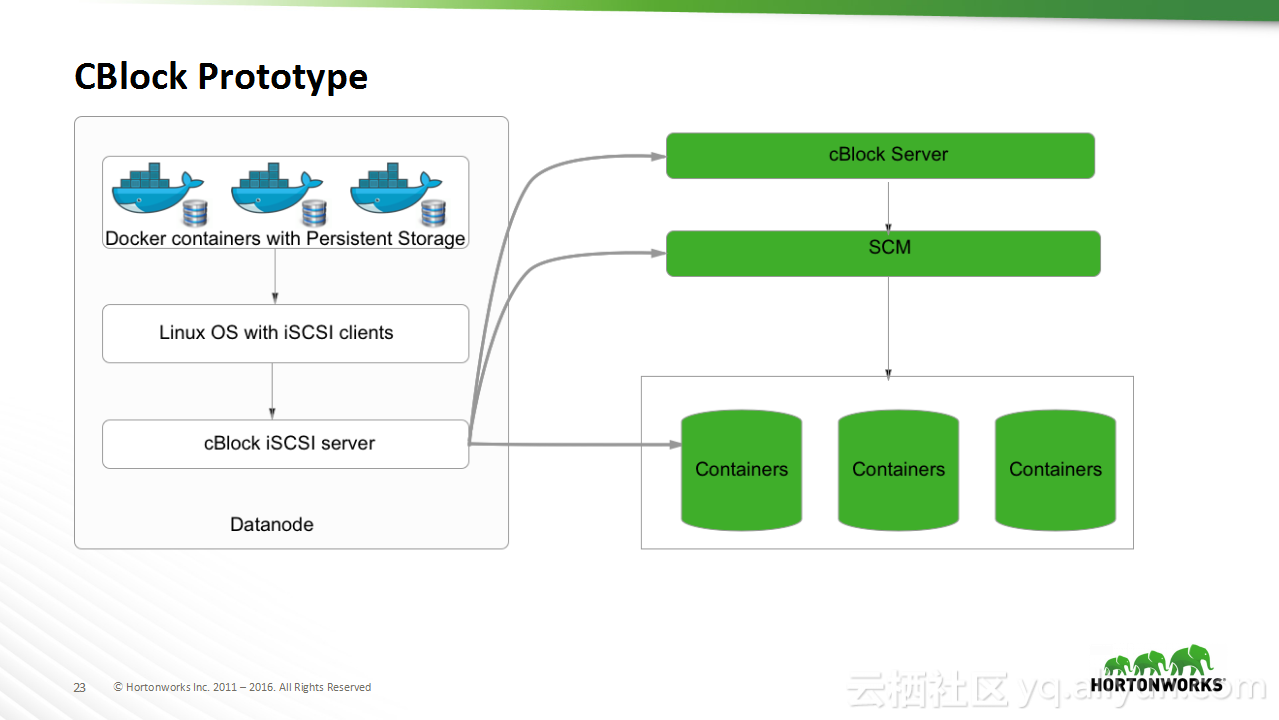
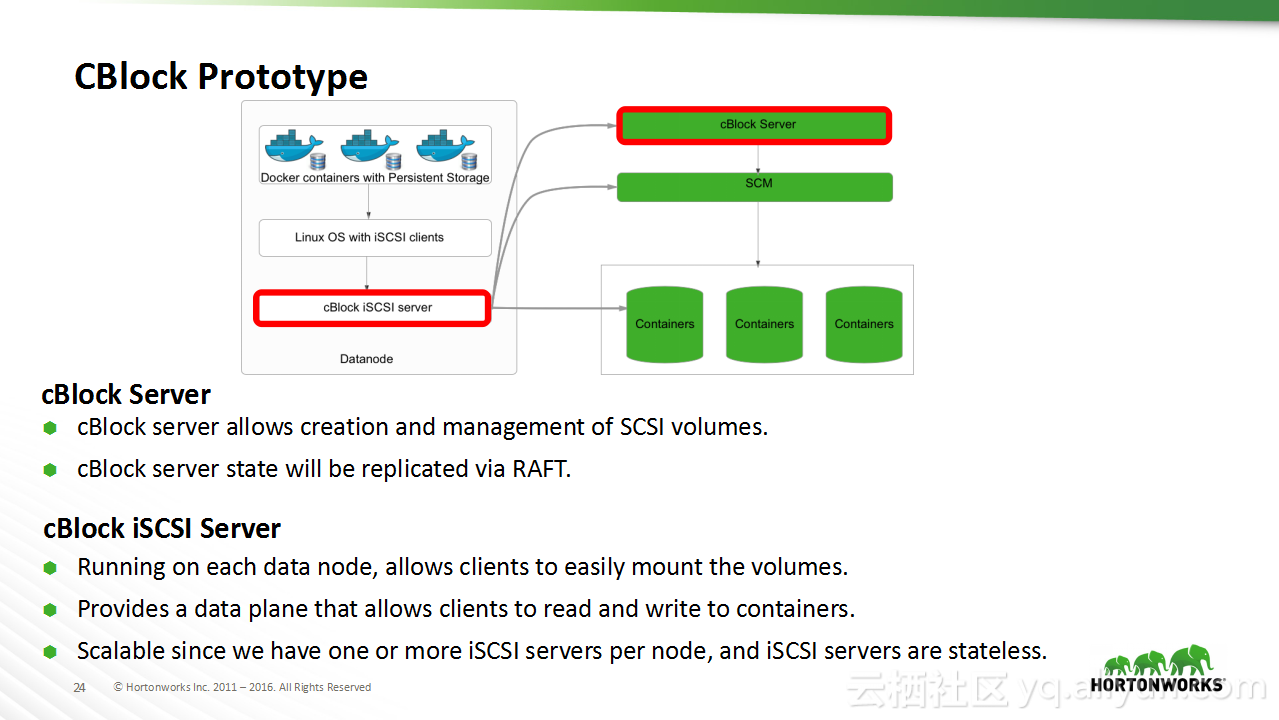
本讲义出自Sanjay Radia与Jitendra Pandey在Hadoop Summit Tokyo 2016上的演讲,主要分享了HDFS的相关概念,分享了HDFS从过去的演进过程以及在未来的发展方向,在讲义中介绍了目前值得关注的问题:文件和存储块的扩展性问题,并且分享了存储容器对于存储层的泛化。
本讲义出自
Sanjay Radia与Jitendra Pandey
在Hadoop Summit Tokyo 2016上的演讲,主要分享了HDFS的相关概念,分享了HDFS从过去的演进过程以及在未来的发展方向,在讲义中介绍了目前值得关注的问题:文件和存储块的扩展性问题,并且分享了存储容器对于存储层的泛化。
文章标签:
存储
容器
分布式计算
Hadoop
关键词:
文件存储HDFS版hadoop
hadoop文件存储HDFS版
hadoop hdfs
hadoop分布式
文件存储HDFS版分布式存储
小猫吃鱼569
目录
相关文章
桃李春风一杯酒
|
11天前
|
分布式计算
Hadoop
大数据
大数据技术与Python:结合Spark和Hadoop进行分布式计算
【4月更文挑战第12天】本文介绍了大数据技术及其4V特性,阐述了Hadoop和Spark在大数据处理中的作用。Hadoop提供分布式文件系统和MapReduce,Spark则为内存计算提供快速处理能力。通过Python结合Spark和Hadoop,可在分布式环境中进行数据处理和分析。文章详细讲解了如何配置Python环境、安装Spark和Hadoop,以及使用Python编写和提交代码到集群进行计算。掌握这些技能有助于应对大数据挑战。
桃李春风一杯酒
28
1
1
yuanzhengme
|
9天前
|
分布式计算
Hadoop
测试技术
Hadoop【基础知识 05】【HDFS的JavaAPI】(集成及测试)
【4月更文挑战第5天】Hadoop【基础知识 05】【HDFS的JavaAPI】(集成及测试)
yuanzhengme
36
8
8
yuanzhengme
|
9天前
|
分布式计算
资源调度
Hadoop
Hadoop【基础知识 03+04】【Hadoop集群资源管理器yarn】(图片来源于网络)(hadoop fs + hadoop dfs + hdfs dfs 使用举例)
【4月更文挑战第5天】Hadoop【基础知识 03】【Hadoop集群资源管理器yarn】(图片来源于网络)Hadoop【基础知识 04】【HDFS常用shell命令】(hadoop fs + hadoop dfs + hdfs dfs 使用举例)
yuanzhengme
36
9
9
yuanzhengme
|
10天前
|
分布式计算
Hadoop
Shell
Hadoop【基础知识 04】【HDFS常用shell命令】(hadoop fs + hadoop dfs + hdfs dfs 使用举例)
【4月更文挑战第4天】Hadoop【基础知识 04】【HDFS常用shell命令】(hadoop fs + hadoop dfs + hdfs dfs 使用举例)
yuanzhengme
24
5
5
爱吃糖的范同学
|
13天前
|
存储
分布式计算
Hadoop
【Hadoop】HDFS 读写流程
【4月更文挑战第9天】【Hadoop】HDFS 读写流程
爱吃糖的范同学
23
0
0
听风de歌
|
11天前
|
存储
分布式计算
Hadoop
大数据处理架构Hadoop
【4月更文挑战第10天】Hadoop是开源的分布式计算框架,核心包括MapReduce和HDFS,用于海量数据的存储和计算。具备高可靠性、高扩展性、高效率和低成本优势,但存在低延迟访问、小文件存储和多用户写入等问题。运行模式有单机、伪分布式和分布式。NameNode管理文件系统,DataNode存储数据并处理请求。Hadoop为大数据处理提供高效可靠的解决方案。
听风de歌
33
2
2
长梦
|
13天前
|
SQL
分布式计算
Hadoop
利用Hive与Hadoop构建大数据仓库:从零到一
【4月更文挑战第7天】本文介绍了如何使用Apache Hive与Hadoop构建大数据仓库。Hadoop的HDFS和YARN提供分布式存储和资源管理,而Hive作为基于Hadoop的数据仓库系统,通过HiveQL简化大数据查询。构建过程包括设置Hadoop集群、安装配置Hive、数据导入与管理、查询分析以及ETL与调度。大数据仓库的应用场景包括海量数据存储、离线分析、数据服务化和数据湖构建,为企业决策和创新提供支持。
长梦
50
1
1
疯狂的猿
|
30天前
|
消息中间件
SQL
分布式计算
大数据Hadoop生态圈体系视频课程
熟悉大数据概念,明确大数据职位都有哪些;熟悉Hadoop生态系统都有哪些组件;学习Hadoop生态环境架构,了解分布式集群优势;动手操作Hbase的例子,成功部署伪分布式集群;动手Hadoop安装和配置部署;动手实操Hive例子实现;动手实现GPS项目的操作;动手实现Kafka消息队列例子等
疯狂的猿
20
1
1
wux_labs
|
4月前
|
分布式计算
资源调度
搜索推荐
《PySpark大数据分析实战》-02.了解Hadoop
大家好!今天为大家分享的是《PySpark大数据分析实战》第1章第2节的内容:了解Hadoop。
wux_labs
48
0
0
Maynor
|
4月前
|
存储
搜索推荐
算法
【大数据毕设】基于Hadoop的音乐推荐系统的设计和实现(六)
【大数据毕设】基于Hadoop的音乐推荐系统的设计和实现(六)
Maynor
165
0
0
热门文章
最新文章
1
bigdata-07-Hdfs原理到实战
2
利用Hive与Hadoop构建大数据仓库:从零到一
3
Hadoop【基础知识 03+04】【Hadoop集群资源管理器yarn】(图片来源于网络)(hadoop fs + hadoop dfs + hdfs dfs 使用举例)
4
Hadoop【基础知识 05】【HDFS的JavaAPI】(集成及测试)
5
大数据处理架构Hadoop
6
Hadoop【hadoop学习大纲完全总结01+02+03+04+05】【自学阶段整理的xmind思维导图分享】【点击可放大看高清】
7
Hadoop【问题记录 02】【hadoop-3.1.3 单机版】ResourceManager无法启动NodeManager启动后过自动关闭 javax/activation/DataSource
8
大数据技术与Python:结合Spark和Hadoop进行分布式计算
9
Hadoop【基础知识 04】【HDFS常用shell命令】(hadoop fs + hadoop dfs + hdfs dfs 使用举例)
10
大数据Hadoop生态圈体系视频课程
1
Hadoop的NameNode的监控与副本管理
12
2
Hadoop集群节点添加
15
3
hadoop的伪分布式搭建-带网盘
15
4
Hadoop的运行模式
7
5
Hadoop【hadoop学习大纲完全总结01+02+03+04+05】【自学阶段整理的xmind思维导图分享】【点击可放大看高清】
32
6
Hadoop【基础知识 05】【HDFS的JavaAPI】(集成及测试)
36
7
Hadoop【基础知识 03+04】【Hadoop集群资源管理器yarn】(图片来源于网络)(hadoop fs + hadoop dfs + hdfs dfs 使用举例)
36
8
Hadoop【基础知识 04】【HDFS常用shell命令】(hadoop fs + hadoop dfs + hdfs dfs 使用举例)
24
9
Hadoop【基础知识 03】【Hadoop集群资源管理器yarn】(图片来源于网络)
22
10
大数据技术与Python:结合Spark和Hadoop进行分布式计算
28
相关课程
更多
大数据实战项目:反爬虫系统(Lua+Spark+Redis+Hadoop框架搭建)第二阶段
大数据实战项目:反爬虫系统(Lua+Spark+Redis+Hadoop框架搭建)第四阶段
大数据实战项目 - 反爬虫系统(Lua+Spark+Redis+Hadoop框架搭建)第七阶段
大数据Hadoop快速入门
Hadoop快速入门
Hadoop企业优化及扩展案例
相关电子书
更多
《构建Hadoop生态批流一体的实时数仓》
零基础实现hadoop 迁移 MaxCompute 之 数据
CIO 指南:如何在SAP软件架构中使用Hadoop
相关实验场景
更多
搭建Hadoop环境
下一篇
部署LAMP环境(Alibaba Cloud Linux 3)