本讲义出自Tomomichi Hirano在Hadoop Summit Tokyo 2016上的演讲,主要分享了Rakuten公司遇到的大规模多租户Hadoop集群造成的迷之问题:从来不结束任务、数据结点冻结、命名结点冻结、命名节点重新启动后出现高负载以及在解决上述问题中获取的经验教训,并且分享了Rakuten的服务器配置和管理经验。









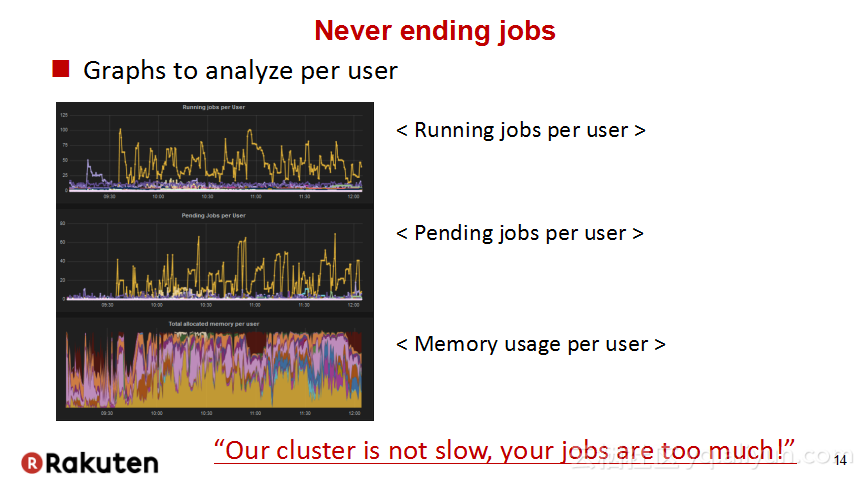
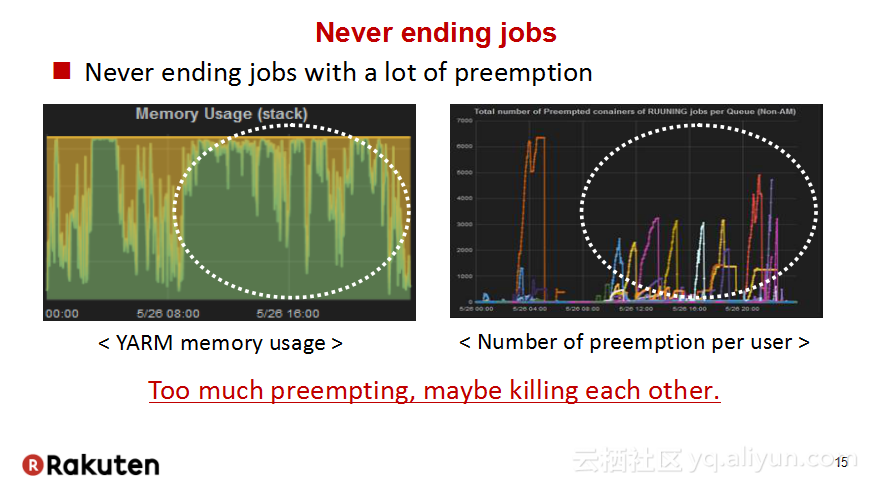

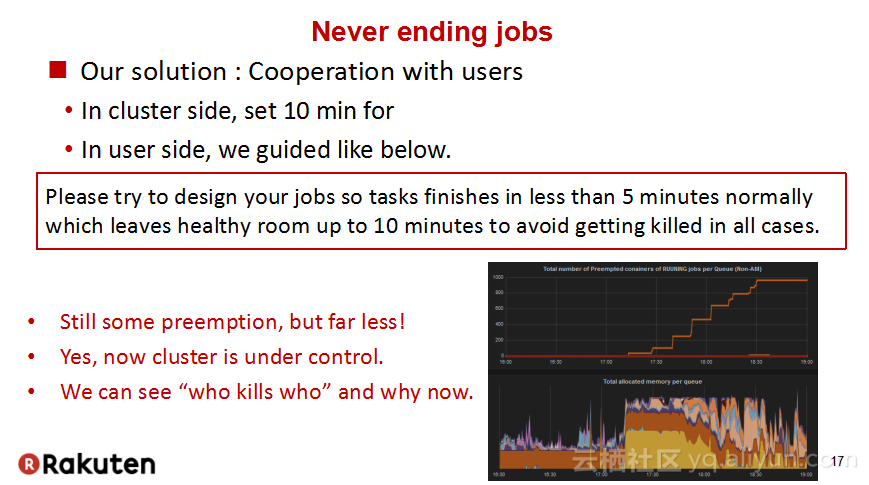



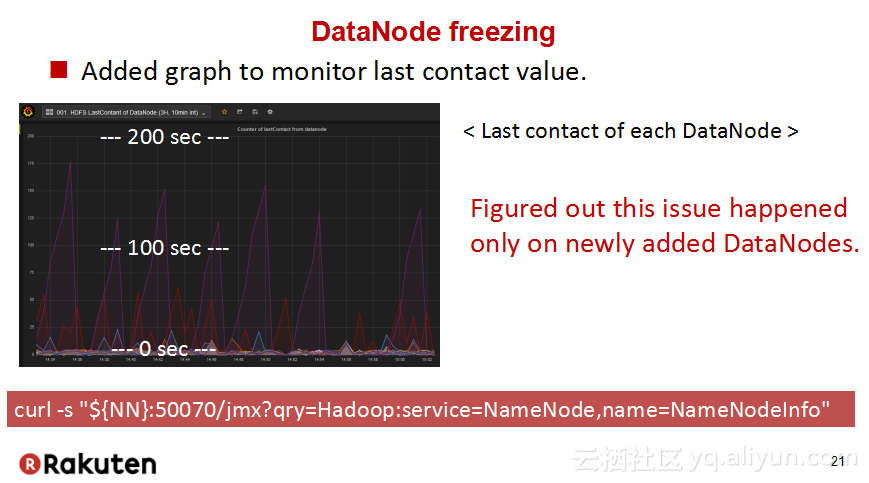
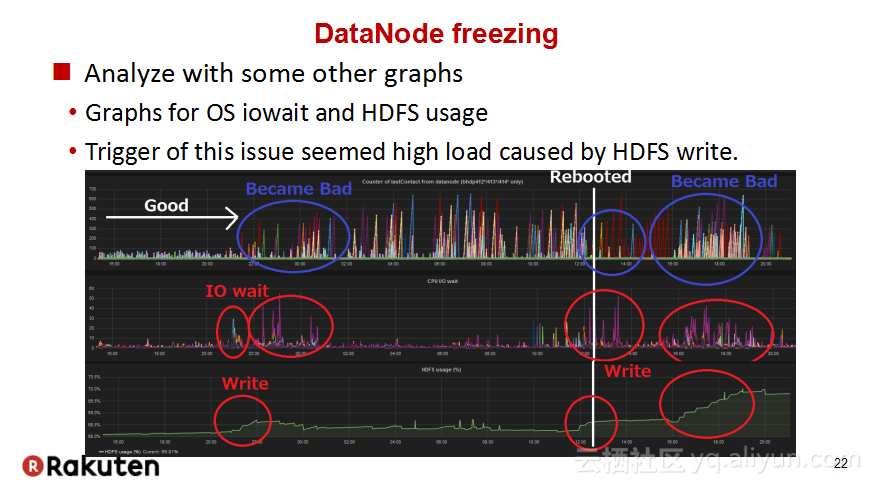



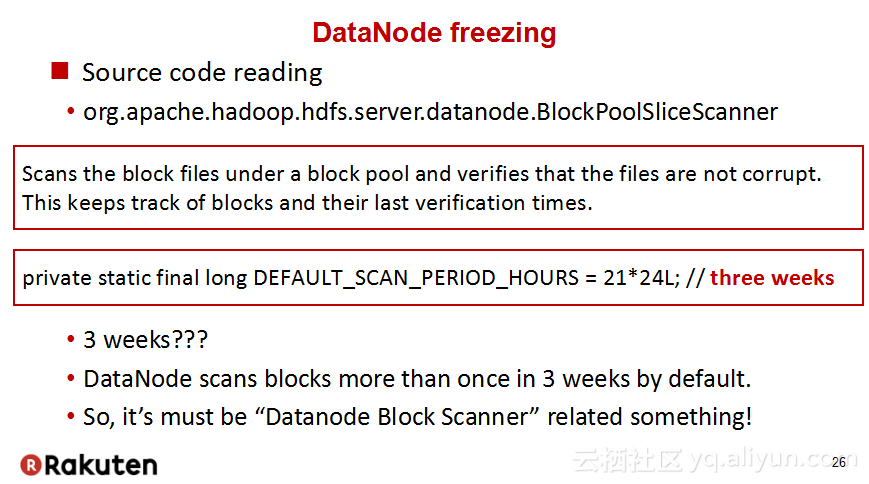




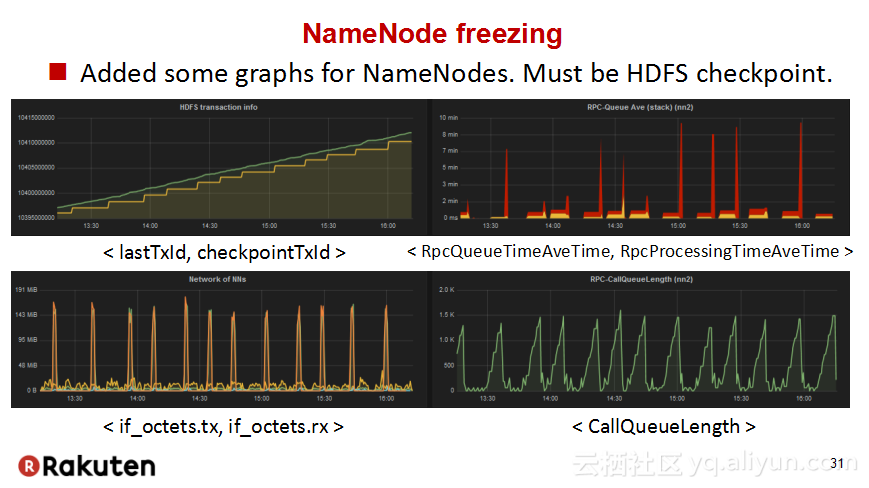




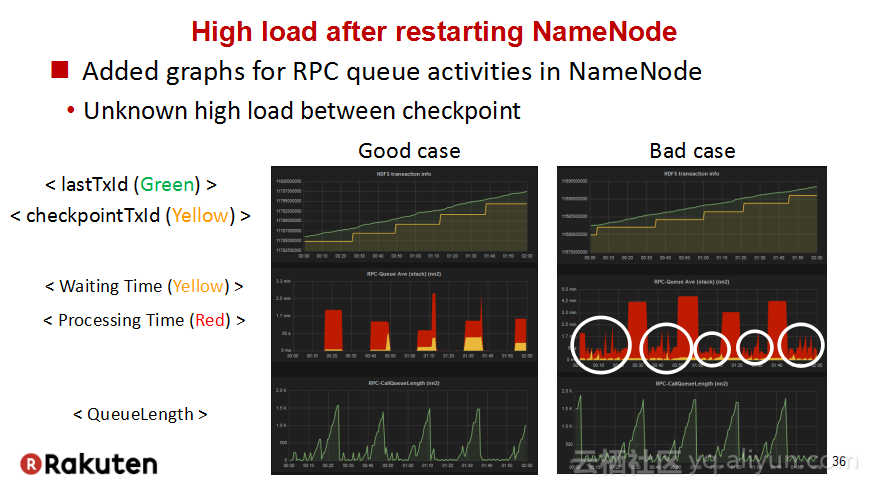
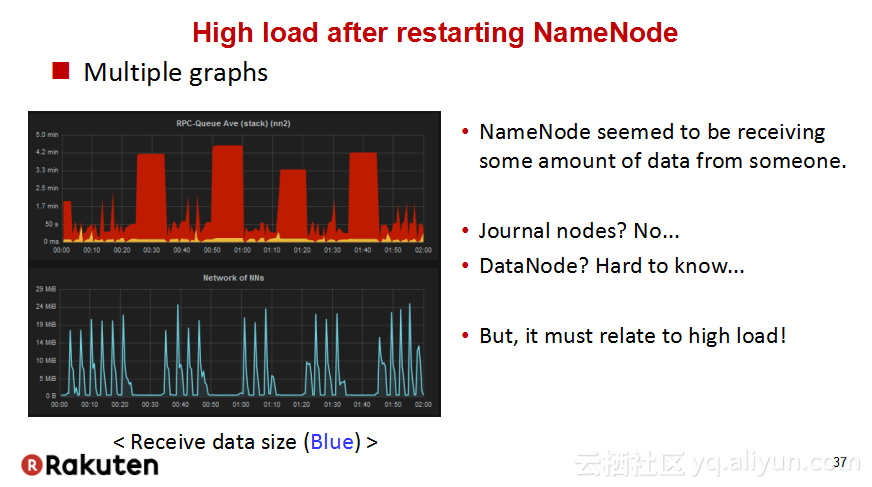









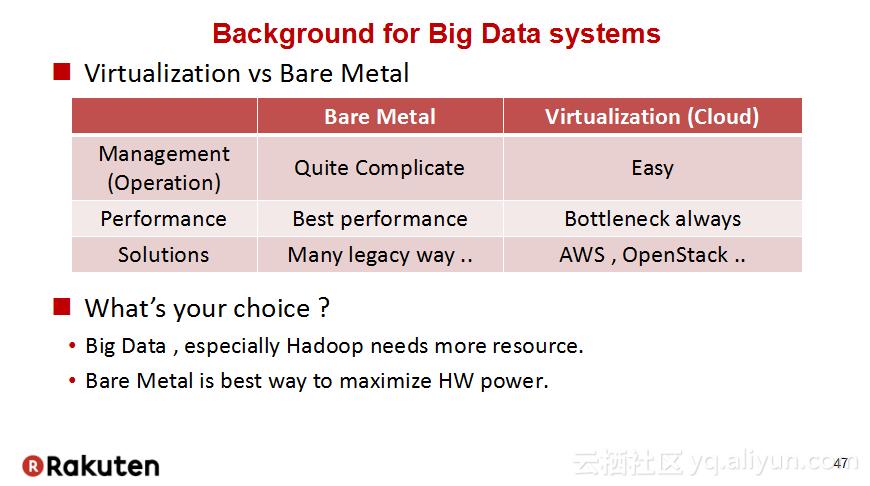

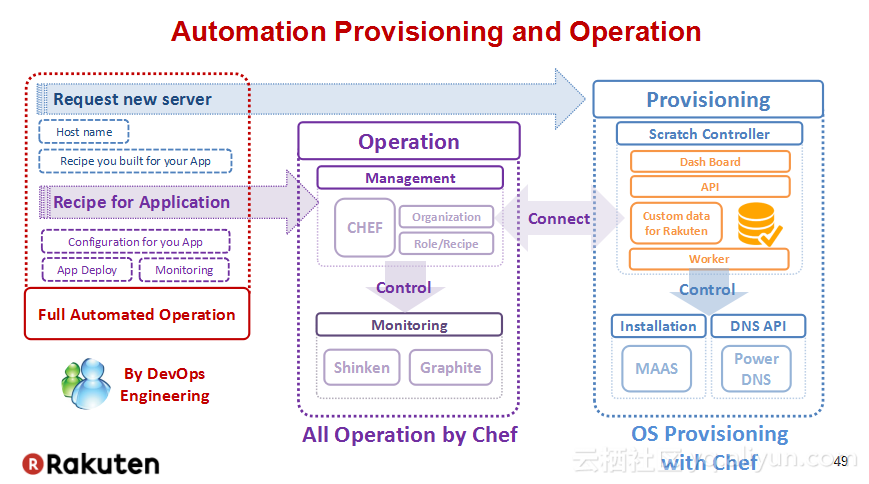
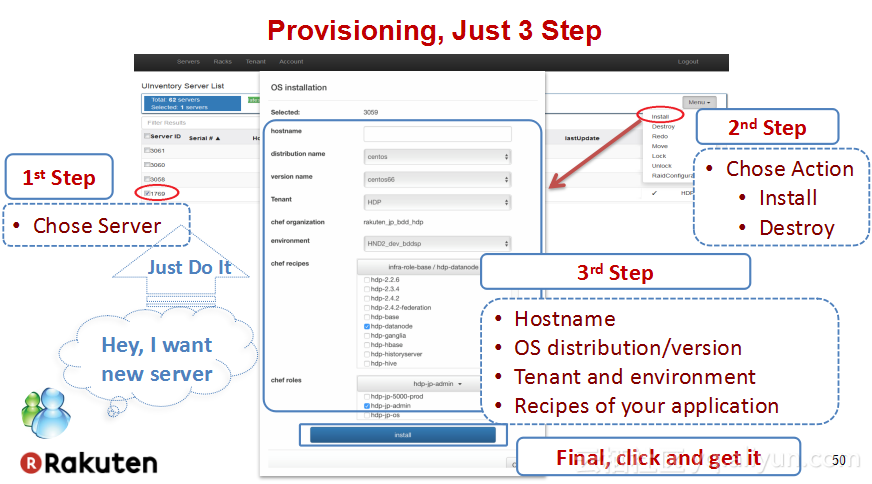
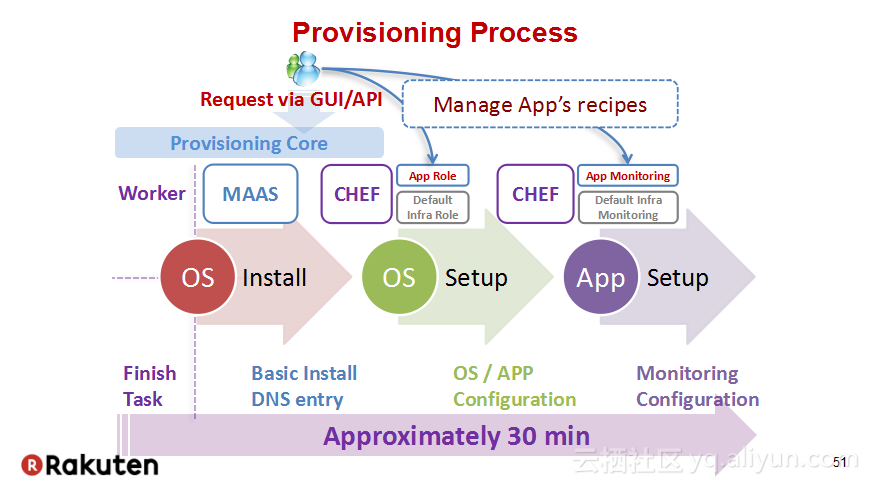



本讲义出自Tomomichi Hirano在Hadoop Summit Tokyo 2016上的演讲,主要分享了Rakuten公司遇到的大规模多租户Hadoop集群造成的迷之问题:从来不结束任务、数据结点冻结、命名结点冻结、命名节点重新启动后出现高负载以及在解决上述问题中获取的经验教训,并且分享了Rakuten的服务器配置和管理经验。


