《ElasticSearch6.x实战教程》之分词
第四章-分词
下雨天留客天留我不留
本打算先介绍“简单搜索”,对ES的搜索有一个直观的感受。但在写的过程中发现分词无论如何都绕不过去。term查询,match查询都与分词息息相关,索性先介绍分词。
ES作为一个开源的搜索引擎,其核心自然在于搜索,而搜索不同于我们在MySQL中的select查询语句,无论我们在百度搜索一个关键字,或者在京东搜索一个商品时,常常无法很准确的给出一个关键字,例如我们在百度希望搜索“Java教程”,我们希望结果是“Java教程”、“Java”、“Java基础教程”,甚至是“教程Java”。MySQL虽然能满足前三种查询结果,但却无法满足最后一种搜索结果。
虽然我们很难做到对于百度或者京东的搜索(这甚至需要了解Lucene和搜索的底层原理),但我们能借助ES做出一款不错的搜索产品。
ES的搜索中,分词是非常重要的概念。掌握分词原理,对待一个不甚满意的搜索结果我们能定位是哪里出了问题,从而做出相应的调整。
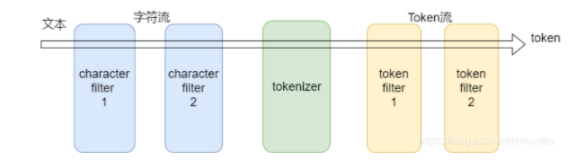
ES中,只对字符串进行分词,在ElasticSearch2.x版本中,字符串类型只有string,ElasticSearch5.x版本后字符串类型分为了text和keyword类型,需要明确的分词只在text类型。
ES的默认分词器是standard,对于英文搜索它没有问题,但对于中文搜索它会将所有的中文字符串挨个拆分,也就是它会将“中国”拆分为“中”和“国”两个单词,这带来的问题会是搜索关键字为“中国”时,将不会有任何结果,ES会将搜索字段进行拆分后搜索。当然,你可以指定让搜索的字段不进行分词,例如设置为keyword字段。
分词体验
前面说到ES的默认分词器是standard,可直接通过API指定分词器以及字符串查看分词结果。
使用standard进行英文分词:
POST http://localhost:9200/_analyze
{
"analyzer":"standard",
"text":"hello world" }
ES响应:
{
"tokens": [
{
"token": "hello",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "world",
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 1
}
]}
如果我们对“helloword”进行分词,结果将只有“helloword”一个词,standsard对英文按照空格进行分词。
使用standard进行中文分词:
POST http://localhost:9200/_analyze
{
"analyzer":"standard",
"text":"学生" }
ES响应:
{
"tokens": [
{
"token": "学",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "生",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
}
]}
“学生”显然应该是一个词,不应该被拆分。也就是说如果字符串中是中文,默认的standard不符合我们的需求。幸运地是, ES支持第三方分词插件。在ES中的中文分词插件使用最为广泛的是ik插件。
ik插件
既然是插件,就需要安装。注意,版本5.0.0起,ik插件已经不包含名为ik的分词器,只含ik_smart和ik_max_word,事实上后两者使用得也最多。
ik插件安装
ik下载地址(直接下载编译好了的zip文件,需要和ES版本一致):https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v6.3.2。ik历史版本下载页面:https://github.com/medcl/elasticsearch-analysis-ik/releases。
下载完成后解压elasticsearch-analysis-ik-6.3.2.zip将解压后的文件夹直接放入ES安装目录下的plugins文件夹中,重启ES。
使用ik插件的ik_smart分词器:
POST http://localhost:9200/_analyze
{
"analyzer":"ik_smart",
"text":"学生"
}
ES响应:
{
"tokens": [
{
"token": "学生",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
}
]}
这才符合我们的预期。那么ik插件中的ik_smart和ik_max_word有什么区别呢?简单来讲,ik_smart会按照关键字的最粗粒度进行分词,比如搜索“北京大学”时,我们知道“北京大学”是一个特定的词汇,它并不是指“北京的大学”,我们不希望搜索出“四川大学”,“重庆大学”等其他学校,此时“北京大学”不会被分词。而ik_max_word则会按照最细粒度进行分词,同样搜索“北京大学”时,我们也知道“北京”和“大学”都是一个词汇,所以它将会被分词为“北京大学”,“北京大”,“北京”,“大学”,显然如果搜索出现后三者相关结果,这会给我们带来更多无用的信息。
所以我们在进行搜索时,常常指定ik_smart为分词器。
有时候一个词并不在ik插件的词库中,例如很多网络用语等。我们希望搜索“小米手机”的时候,只出现“小米的手机”而不会出现“华为手机”、“OPPO手机”,但“小米手机”并不在ik词库中,此时我们可以将“小米手机”添加到ik插件的自定义词库中。
“小米手机”使用ik_smart的分词结果:
{
"tokens": [
{
"token": "小米",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "手机",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
}
]}
进入ik插件安装目录elasticsearch-5.6.0/plugins/elasticsearch/config,创建名为custom.dic的自定义词库,向文件中添加“小米手机”并保存。仍然是此目录,修改IKAnalyzer.cfg.xml文件,如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
重启ES后,再次通过ik_smart对“小米手机”进行分词,发现“小米手机”不再被分词。
创建映射指定分词器
在创建映射时,我们可以指定字段采用哪种分词器,避免我们在每次搜索时都指定。
创建word索引 PUT http://localhost:9200/word
创建analyzer_demo类型已经定义映射Mapping
PUT http://localhost:9200/word/analyzer_demo/_mapping
{
"properties":{
"name":{
"type":"text",
"analyzer":"ik_smart"
}}
}
查看word索引结构 GET http://localhost:9200/word
ES响应:
{
"word": {
"aliases": {},
"mappings": {
"analyzer_demo": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
},
"settings": {
"index": {
"creation_date": "1561304920088",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "A2YO9GpzRrGAIm2Q6rCoWA",
"version": {
"created": "5060099"
},
"provided_name": "word"
}
}
}}
可以看到ES在对name字段进行分词时会采用ik_smart分词器。
原文地址https://www.cnblogs.com/yulinfeng/p/11216377.html