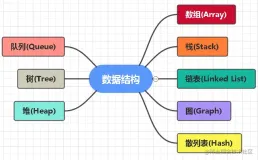
阅前:只是一篇随手的笔记(内容参考来源:数据结构与算法、算法导论、算法精解、算法图解等书籍),帮助自己记录学习过程,顺便留些坑。
栈
遵循后进先出原则的有序集合。
生产:
→ +3 | 3 |
→ +2 | 2 | | 2 |
| | → +1 | 1 | | 1 | | 1 |消费:
| 3 | → -3
| 2 | | 2 | → -2
| 1 | | 1 | | 1 | → -1 | |队列
遵循先进先出原则的有序集合。
生产:
→ +3 | 3 |
→ +2 | 2 | | 2 |
| | → +1 | 1 | | 1 | | 1 |消费:
| 3 |
| 2 | | 3 |
| 1 | → -1 | 2 | → -2 | 3 | → -3 | |如果要优先队列,在上面的结构上加入 priority ,根据 priority 排序。
// 比如 值越小优先级越高
| 1 : priority 3 |
| 2 : priority 2 |
| 3 : priority 1 |链表
链表存储的是一系列有序的元素集合,每一项在内存中可以不是连续放置的,通过当前元素的属性引用下一个元素(或加上上一个元素的引用,成双向链表)内存地址即可。
其结构如下:
------- ------- -------
| v : 1 | → | v : 2 | → | v : 3 |
| next | next | next | next | next |
------- ------- -------或者双向链表:
-------- -------- --------
| v : 1 | next | v : 2 | next | v : 3 |
| next | → | next | → | next |
| return | ← | return | ← | return |
-------- return -------- return --------小记:又如 react hooks,或者 fiber 对象链(这个链表有点畸形)
hooks 使用代码:
const [num, setNum] = useState(1);
const [str, setStr] = useState("a");fiber 对象上的 memoizedState 属性(hooks):
--------------------
| baseState : 1 |
| baseUpdate : null |
| memoizedState : 1 |
| next |
| queue |
--------------------
next ↓
--------------------
| baseState : "a" |
| baseUpdate : null |
| memoizedState : "a"|
| next |
| queue |
--------------------
next ↓
--------------------
| baseState : null |
| baseUpdate : null |
| memoizedState |
| next : null |
| queue : null |
--------------------集合
表示一组里面的项是无序且唯一的元素,由 {} 表示。
ECMAScript 6 里的 Set:
const mySet = new Set([1, 2, 3, 3, 4, 5, 6, 7]);
// Set(7) {1, 2, 3, 4, 5, 6, 7}并集 & 交集 & 差集 & 子集
A ∪ B : [ 1, 2, 3 ] ∪ [ 2, 3, 4 ] => [ 1, 2, 3, 4 ]
A ∩ B : [ 1, 2, 3 ] ∩ [ 2, 3, 4 ] => [ 2, 3 ]
A - B : [ 1, 2, 3 ] - [ 2, 3, 4 ] => [ 1 ]
B - A : [ 2, 3, 4 ] - [ 1, 2, 3 ] => [ 4 ]
B ⊆ A : [ 2, 3 ] ⊆ [ 1, 2, 3 ] => [ 2, 3 ]ES6 Set & WeakSet 具体的自己看 https://www.ecma-international.org/ecma-262/6.0/
字典(映射)
表示一组无序且唯一的[键, 值]对,通过键来查询值,也由 {} 表示。
ECMAScript 6 里的 Map:
const myMap = new Map([["1", 1], [1, "1"]]);
// Map(2) {"1" => 1, 1 => "1"}ES6 Map & WeakMap 具体的自己看 https://www.ecma-international.org/ecma-262/6.0/
散列表
在数组中,一般需要知道下标才能够直接取到需要的值(O(1),一次操作),如果使用关键字查找,那么最坏需要 N 次(N 是数组长度,也就是 O(n));而散列表可以将通过关键字搜索降到 O(1),其原理是通过散列函数将关键字转换成存储数据的下标存在在散列表中,当通过关键字搜索时,只需要通过散列函数取得该下标就能得到值(当然是理想情况下的 O(1),实际实现中大多还是 O(n),只不过它能够将其搜索范围缩小,起码 java 和 redis 里的 hashMap 的对应存储值是链表形式的...)。
在散列表中,通过散列函数,将搜查 key 数据的下标,结构如下:
---------------------------------------------------------
| key | hash fn | hash key | hash table |
---------------------------------------------------------
| "aa" | fn("aa") | 149 | [149] aa@gmail.com |
---------------------------------------------------------
| "bb" | fn("bb") | 153 | [153] bb@gmail.com |
---------------------------------------------------------
| "cc" | fn("cc") | 157 | [157] cc@gmail.com |
---------------------------------------------------------这里以取模求散列值的方法为例,用数组来存储数据:
// 表
var table = [];
// 举个例子,比如一个简单的散列计算函数
var hashCode = key => {
let hash = 0;
for (let i = 0; i < key.length; i++) {
hash = hash + key.charCodeAt(i);
}
return hash;
};
// 存值
var put = (key, value) => {
var position = hashCode(key);
table[position] = value;
};
// 取值
var query = key => {
var position = hashCode(key);
return table[position];
};
put("hy", "hello yeshou");
put("ht", "hello tutu");
put("hw", "hello world");
console.log(query("hy")); // output hello yeshou
console.log(query("ht")); // output hello tutu
console.log(query("hw")); // output hello world
put("yh", "hello haha");
console.log(query("hy")); // output hello world
console.log(query("yh")); // output hello world然而上面的代码是有问题的,当把hy倒过来yh的时候,hash 的计算是一样的值,于是会出现后面的现象,这就是 hash 函数计算的冲突了,更好的 hash 函数可以降低冲突率,比如网上的一些 lose lose, djb2,sdbm等..
djb2
var hashCode = key => {
let hash = 5381; // 初始 hash 值
for (let i = 0; i < key.length; i++) {
hash = hash * 33 + key.charCodeAt(i); // 乘积因子 33
}
return hash % 1013; // mod 5381
};
console.log(hashCode("yh"), hashCode("hy")); // output 762 218个人认为这种方式生成的 hashMap 空间方面会比较多的无效占用(比如上面的 hashMap length=1012),但存的数据根据我希望的只需要有 78 个便足够,除非设计者本身就需要存这么多的数据,不然的话可以根据需求去设计初始的 hash 值、乘积因子和 mod 。(保留意见,暂时对这方面研究深度不够,仅做笔记)
除了精心设计的 hash 函数能够降低冲突率,一些书籍(如算导、数据结构、算法精解)中还有提到一些"改进 hashMap 存储规则的方法"来解决可能出现的冲突,如"链接法"和"开放寻址法"。这里仅简单提一下.
链接法:保留冲突,在冲突的项上创建是一个双向链表(算导里推荐的是双向链表,操作的负责度为 O(1)),可以简单理解为 Map+链表 的结合,在查找过程中可以快速定位查找范围,节省不必要部分的检索;
开放寻址法:保留冲突,在冲突位置根据指定的探查方式对散列表进行探查,直到探查到空槽来放置元素;元素都存在散列表里,装载因子 α 不会超过 1;三种常用的计算开放寻址法的探查序列:线性探查、二次探查、双重散列。
小记:java hashMap 使用的是链接法,在 JDK-1.8 之前由 load factor = 0.75 (装载因子 > 0.75)为界限执行扩容;1.8 后以 TREEIFY_THRESHOLD = 8 (链表长度 > 8)为界限执行转换红黑树。(保留笔记,之后有兴趣再探索扩容和转换过程)
树
树是一种分层数据的抽象模型,一个树结构包括一系列的存在父子关系的节点,每个节点(除了根节点)都有一个父节点以及零个或多个子节点。
如下结构:
(root)
10
/ \
8 9
/ / | \ \ |
1 2 4 5 7 15二叉树 & 二叉搜索树
二叉树是每个结点最多有两个子节点(树)的树结构。
二叉搜索树是二叉树的一种,规则是左侧子节点的值小于本身节点的值,右侧节点的值大于本身节点的值(使得其操作的复杂度等于树高)。
二叉搜索树结构如下:
(root)
11
/ \
7 15
/ \ / \
5 9 13 17
/ \ / \ / \ / \
4 6 8 10 12 14 16 18二叉树的遍历
先序遍历:以优先于后代节点的顺序访问每个节点,平常的遍历操作顺序就是这种。
代码如下:
function traverse(node, callback) {
if (node !== null) {
callback(node.v);
traverse(node.left, callback);
traverse(node.right, callback);
}
}如果拿上面的结构来说,顺序是 11,7,5,4,6,9,8,10,15,13,12,14,17,16,18
中序遍历:一种以上行顺序访问树中所有节点的遍历方式,以从最小到最大的顺序访问所有节点。
代码如下:
function traverse(node, callback) {
if (node !== null) {
traverse(node.left, callback);
callback(node.v);
traverse(node.right, callback);
}
}如果拿上面的结构来说,顺序是 4,5,6,7,8,9,10,11,12,13,14,15,16,17,18
后序遍历:先访问节点的后代节点,再访问节点本身。(应用:如计算一个目录和其子目录中所有文件所占空间大小)
代码如下:
function traverse(node, callback) {
if (node !== null) {
traverse(node.left, callback);
traverse(node.right, callback);
callback(node.v);
}
}如果拿上面的结构来说,顺序是 4,6,4,8,10,9,7,12,14,13,16,18,17,15,11
红黑树
红黑树是一颗二叉搜索树,它在每个节点上增加了一个存储位以表示节点的颜色(只可以是红色和黑色),通过对任何一条从根到叶子的简单路径上各个节点的颜色进行约束,确保没有一条路径会比其他路径长出 2 倍,因而保证此树是近似于平衡的(主要是保持树的平衡,可减短特殊情况下的操作路径)。
红黑树满足以下规则:
- 根节点是黑色的;
- 每个节点只能是红色或者黑色的;
- 每个叶子节点(nil)是黑色的;
- 如果一个节点是红色的,则它的两个子节点是黑色的;
- 对每个节点,从该节点到其所有后代叶节点的简单路径上均包含相同数目的黑色节点。
对于红黑树的操作,会根据规则做一些改变(树节点的变色和旋转),如下案例:
树中的 n 为 nil,黑色 ; B 为黑色 ; R 为红色。
(root)
13(B)
/ \
8(R) 17(R)
/ \ / \
1(B) 11(B) 15(B) 23(B)
/ \ / \ / \ / \
n 6(R) n n n n 22(R) 25(R)
// 如果仅插入 14
(root)
13(B)
/ \
8(R) 17(R)
/ \ / \
1(B) 11(B) 15(B) 23(B)
/ \ / \ / \ / \
n 6(R) n n 14(R) n 22(R) 25(R)
/ \
n n
// 如果仅插入 21
(root)
17(B)
/ \
8(R) 23(R)
/ \ / \
1(B) 13(B) 22(B) 25(B)
/ \ / \ / \ / \
n 6(R) 11(R) 15(R) 21(R) n n n
/ \ / \ / \ / \
n n n n n n n n
// 如果仅删除 15
(root)
13(B)
/ \
6(R) 23(R)
/ \ / \
1(B) 8(B) 22(B) 25(B)
/ \ / \ / \ / \
n n n n n n n nB 树 & B+树
B 树将任何和关键字相关联的"数据指针"和关键字一起存放在节点中。其结构规则如下:
-
每个节点 x 具有下面属性;
- x.n,当前存储节点中的关键字个数;
- x.n 个关键字本身:x.key_1, x.key_2, ..., x.key_x.n,以非降序存放,使得:x.key_1 <= x.key_2 <= ... <= x.key_x.n;
- x.leaf,一个 boolean 值,如果 x 是叶节点,则是 ture;如果 x 是内部节点,则为 false;
- 每个内部节点 x 还包含 x.n+1 个指向其子节点的指针:x.c_1, x.c_2, ..., x.c_x.n+1,叶节点没有子节点,所以其 c_i 属性没有定义;
- 关键字 x.key_1 对存储在各个字数中的关键字范围进行分割:如果 k_i 为人任意一个存储在以 x.c_i 为根的子树中的关键字,那么:k_1 <= x.key_1 <= k2 <= x.key_2 <= ... <= x.key_x.n+1 <= k_x.n+1
- 每个叶节点具有相同是深度,即树的高度 h;
-
每个节点所包含的关键字个数有上界和下界,用 B 树的最小读书的固定整数 t >= 2 来表示这些界;
- 除了根节点以外的每个节点必须至少有 t-1 个关键字,因此除了根节点以外的每个内部节点至少有 t 个子节点;如果树非空,根节点至少有一个关键字;
- 每个节点至多可包含 2t-1 个关键字,因此一个内部节点至多可有 2t 个子节点,当一个节点恰好有 2t-1 个关键字时,则该节点是满了;
B+树将"数据指针"都存储在叶节点中,内部节点只存放关键字和子节点的指针,因此最大化了内部节点的分支因子。
小记:据说 mysql 的索引据说 B+树实现的... 留坑,闲时再做一次对 mysql 的深度探索。
图
如果说树是分层的抽象,那图就更加抽象了,针对结构的抽象模型,因为任何二元关系都可以用图来表示。
一个图结构由点(节点)和线(边)组成。
如下:
// 无(方)向图
A - B - C - D
| | |
E F - G - H
| |
-I-
// 有(方)向图
A → B → C → D
↓ ↓ ↓
E F → G → H
↓ ↓
→I←搜索:深度优先 & 广度优先
图的遍历可以用来寻找特定的节点或寻找两个节点之间的路径,检查节点之间是否连通或者是否含有环等。
如上述图,深度优先搜索(Depth-First Search)的顺序是:
A E
A B F G I
A B F G H I
A B C D H I如上述图,广度优先搜索(Breadth-First Search)的顺序是:
A E
A B C
A B F
A B C D
A B F G
A B C D H
A B F G I
A B F G H
A B C D H I
A B F G H I搜索过程是拆分成每次搜索步骤的,可能这样描述也不是很好理解... 能理解的就理解吧,不能理解的也确实不理解...
一般情况下深度搜索占用内存少但速度较慢,广度搜索占内存较多但速度较快。
深度优先和广度优先都有对应的应用场景(个人见解,这块还缺乏丰富的实践经验):比如要搜索单个值或特定值,那么深搜是相对较好的方式;比如搜索近似值或所有值,则广搜更具"全局"的概念。
小记:深搜广搜对于树也是适用的。同时这块深入进去还可以带"记忆"的搜索(缓存搜索过程和结果),动态规划等知识... 这块后续会有给出笔记,含分治策略等~
最后
希望自己技术水平越来越好吧 ~(・ェ・。)~ 越学越觉得自己渣...
本文内容仅做学习参考,更多详情自行官方学习;佛系写文,不喜勿喷。