热门
Java中数组详解
智能评估时代:SurveyKing开源问卷系统YYDS
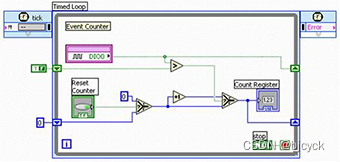
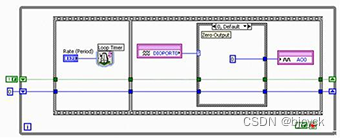
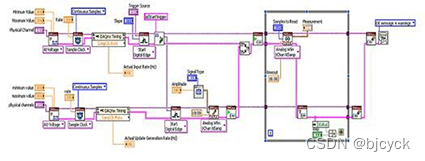
LabVIEW编程LabVIEW开发高级数据采集技术 操作数字IO 例程与相关资料
【大模型】描述与 LLM 相关的个人项目或感兴趣的领域
【大模型】使用哪些资源来了解 LLM 的最新进展?
LabVIEW编程LabVIEW开发高级数据采集技术 计数器定时器的操作 例程与相关资料
LabVIEW编程LabVIEW开发高级数据采集技术 模拟波形的生成 例程与相关资料
Linux:进程等待 & 进程替换
LabVIEW编程LabVIEW开发高级数据采集技术 同步 例程与相关资料
LabVIEW编程LabVIEW开发高级数据采集技术定时与触发 例程与相关资料
C++:现代类型转换
C++:智能指针
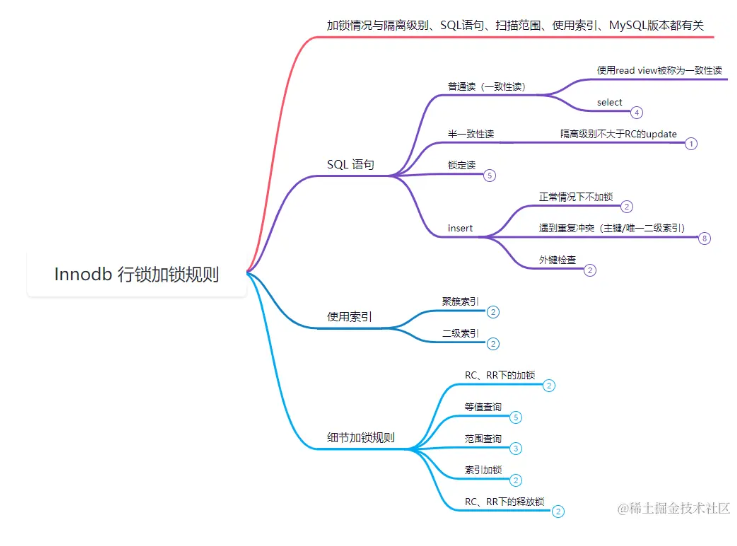
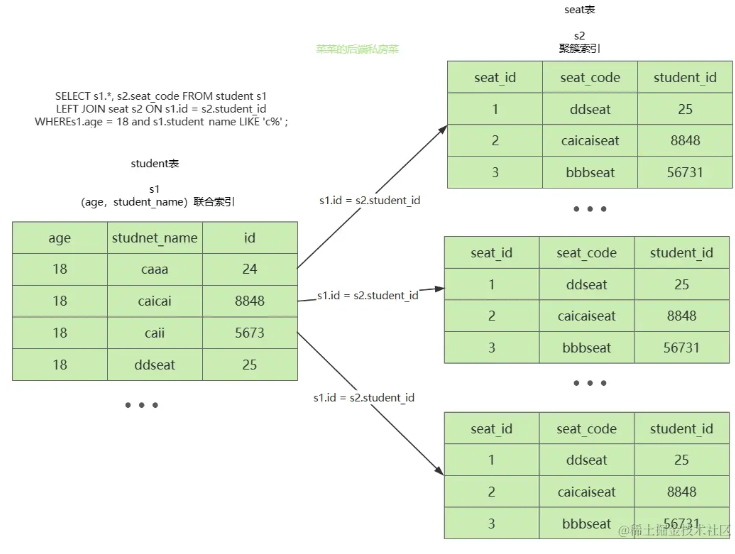
10个行锁、死锁案例⭐️24张加锁分析图🚀彻底搞懂Innodb行锁加锁规则!
MySQL连接的原理⭐️4种优化连接的手段性能提升240%🚀
云原生架构的未来展望
Linux:进程创建 & 进程终止
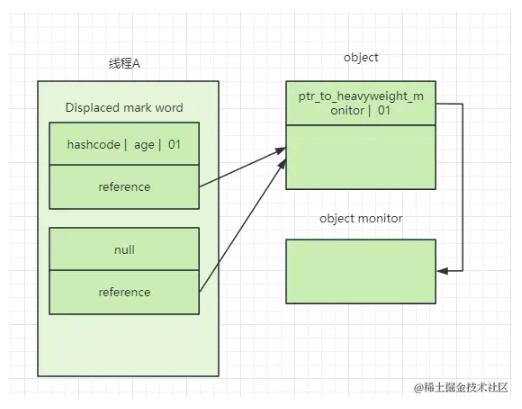
15000字、6个代码案例、5个原理图让你彻底搞懂Synchronized(下)
Linux:进程地址空间
15000字、6个代码案例、5个原理图让你彻底搞懂Synchronized(上)
Linux:环境变量
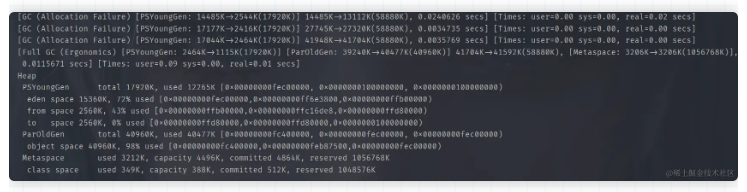
JVM参数太多?一网打尽常用JVM参数!
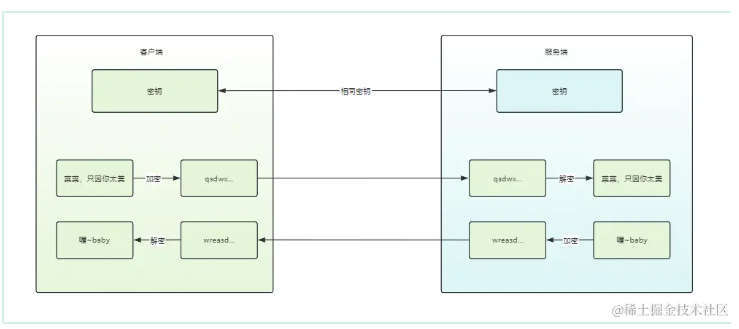
一文读懂HTTPS⭐揭秘加密传输背后的原理与Nginx配置攻略
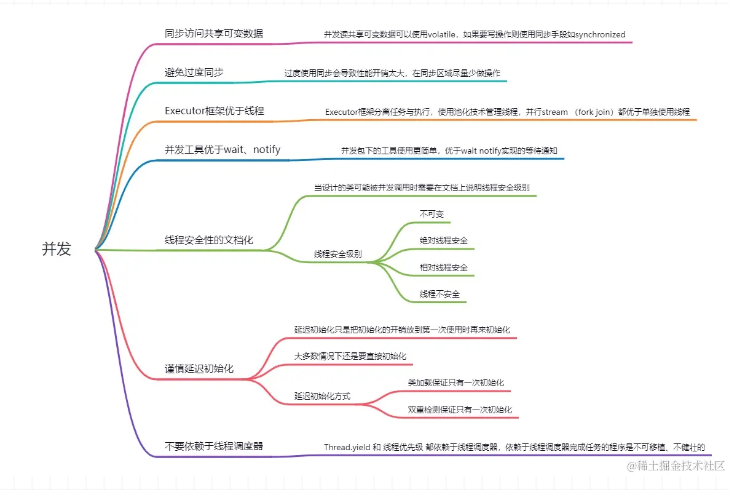
Java并发设计的7条原则
Linux:进程调度
LabVIEW编程LabVIEW开发NI 7851R同步到背板时钟 例程与相关资料
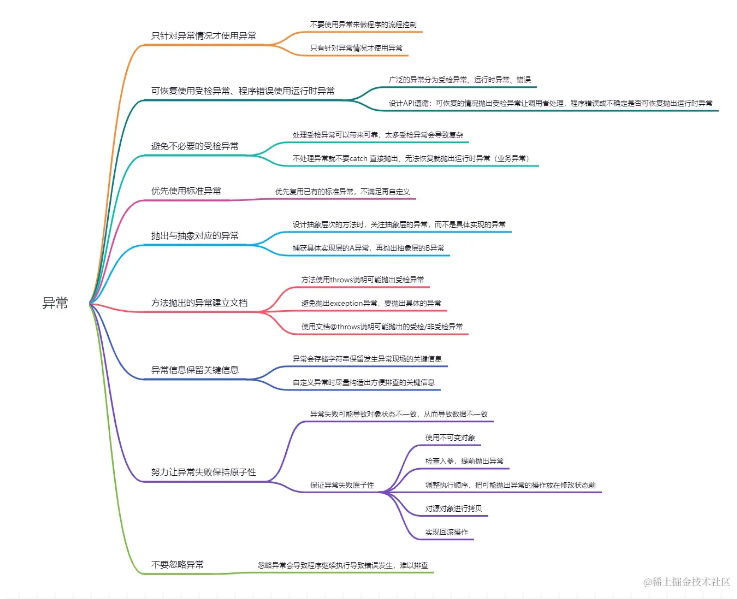
关于Java异常处理的9条原则
LabVIEW编程LabVIEW开发NI PCI-6513数字滤波 例程与相关资料
Linux:进程状态
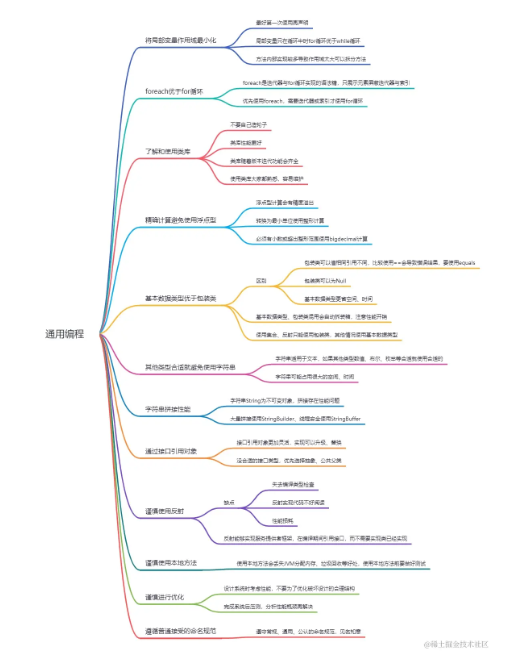
12条通用编程原则✨全面提升Java编码规范性、可读性及性能表现
C++:异常
LabVIEW编程LabVIEW开发DAQ采集消除串扰 例程与相关资料
JavaWeb之Servlet(下)
掌握8条方法设计规则,设计优雅健壮的Java方法
LabVIEW编程LabVIEW开发NI PCI-6255消除鬼影 例程与相关资料
在Ubuntu安装RPM文件
Linux:进程概念
LabVIEW编程LabVIEW开发1920 LCR仪表例程与相关资料
PolarDB 体验报告
JavaWeb之Servlet(上)
Github 2024-05-07 Python开源项目日报 Top10
计算机网络:MAC地址 & IP地址 & ARP协议
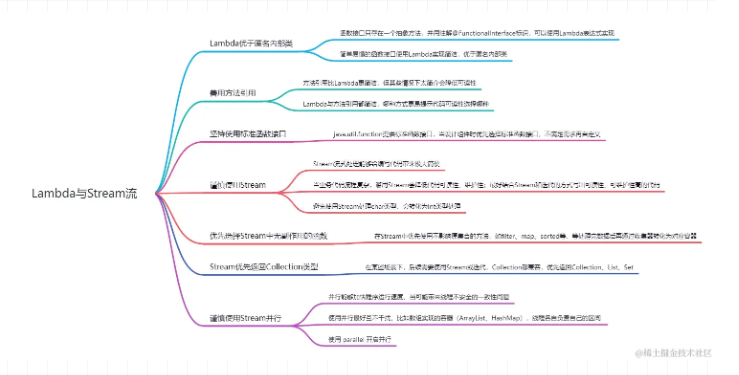
Lambda与Stream✨让代码简洁高效的七大原则
LabVIEW编程LabVIEW开发Memmert oven温箱例程与相关资料
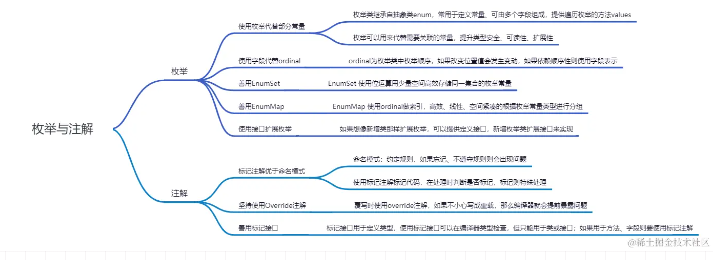
8条枚举与注解技巧,提升代码质量与设计美学
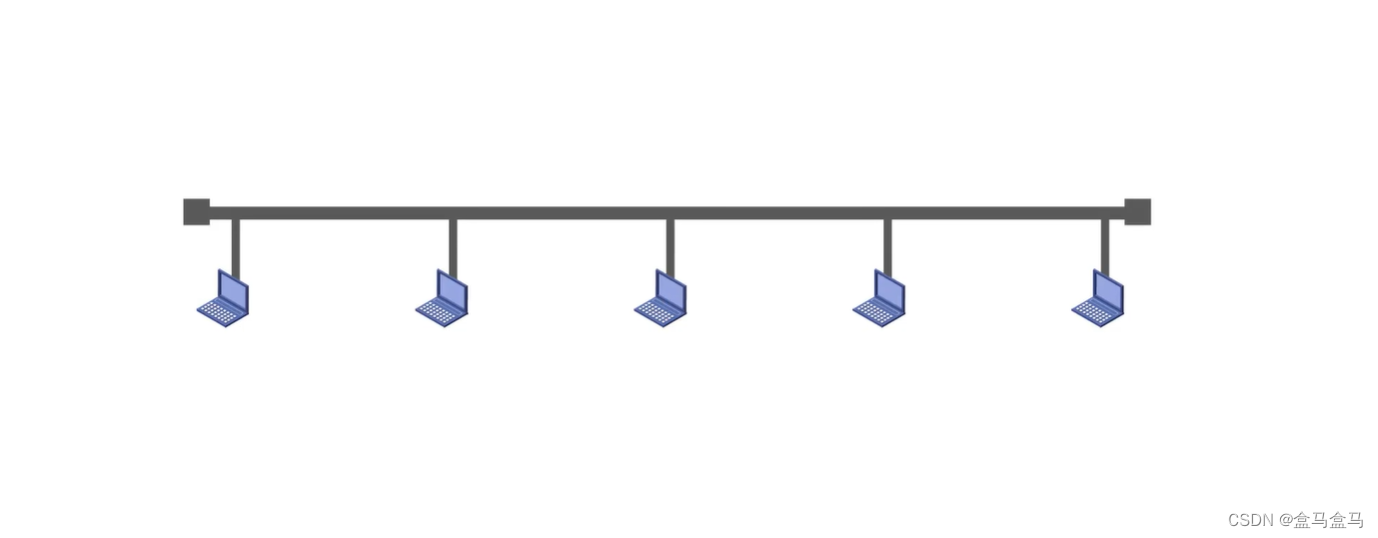
计算机网络:CSMA/CA协议
LabVIEW编程NI 6602计数器DMA冲突例程与相关资料
云效流水线 Flow 评测:助力企业高效完成 CICD 全流程
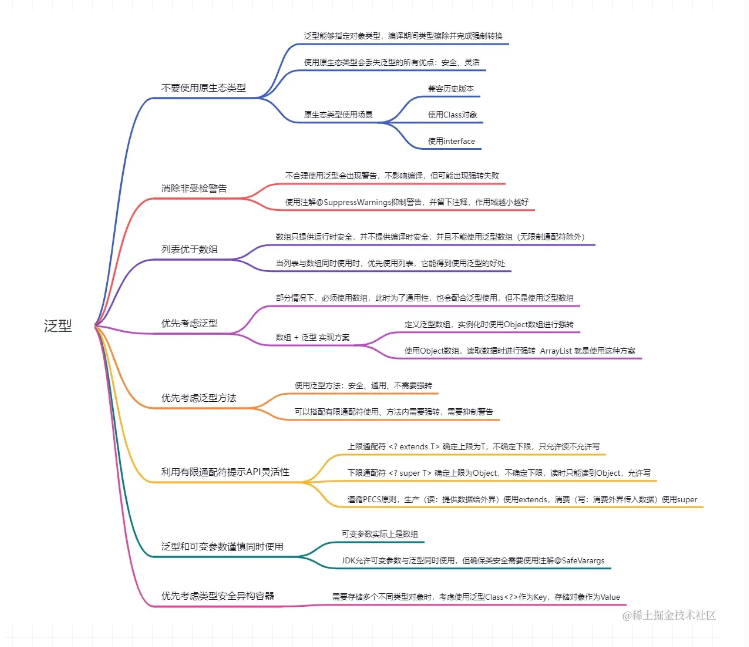
掌握8条泛型规则,打造优雅通用的Java代码
区块链系统开发|(成熟技术)/区块链系统开发介绍方案
如何进行资产梳理(上)