MapReduce的编程思想(1)
简介:
MapReduce的编程思想(1)MapReduce的过程(2)1. MapReduce采用分而治之的思想,将数据处理拆分为主要的Map(映射)与Reduce(化简)两步,MapReduce操作数据的最小单位是一个键值对。2. MapReduce计算框架为主从架构,分别是JobTracker与TaskTracker。JobTracker在集群中为
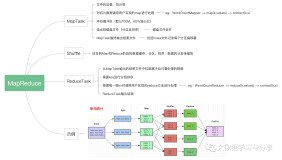
1. MapReduce采用分而治之的思想,将数据处理拆分为主要的Map(映射)与Reduce(化简)两步,MapReduce操作数据的最小单位是一个键值对。
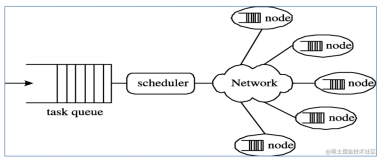
2. MapReduce计算框架为主从架构,分别是JobTracker与TaskTracker。
- JobTracker在集群中为主的角色,它主要负责任务调度和集群资源监控,并不参与具体的计算。
- TaskTracker在集群中为从的角色,它主要负责汇报心跳和执行JobTracker的命令(启动任务、提交任务、杀死人物、杀死作业和重新初始化)。
- 客户端,用户编写MapReduce程序通过客户端提交到JobTracker。
3. MapReduce作业(job)是指用户提交的最小单位,而Maop/Reduce任务(task)是MapReduce计算的最小单位。
- MapReduce作业由JobTracker的作业分解模块分拆为任务交给各个TaskTracker执行,在MapReduce计算框架中,任务分为两种,Map任务和Reduce任务。
4. MapReduce的计算资源划分
- Hadoop的资源管理采用了静态资源设置方案,即每个节点配置好Map槽和Reduce槽的数据量,一旦Hadoop启动后将无法动态更改。
- TaskTracker能启动的任务数量是由TaskTracker配置的任务槽(slot)决定。
- Map任务只能使用Map槽,Reduce任务只能使用Reduce槽。
5. MapReduce的局限性
- MapReduce的执行速度慢。
- MapReduce过于底层。
- 不是所有算法都能用MapReduce实现。