直播回看点我
直播主题:
【Spark Relational Cache 原理和实践】
时间:
6月26日 19:00-20:00
分享嘉宾:
李呈祥,阿里巴巴计算平台事业部EMR团队的高级技术专家,Apache Hive Committer, Apache Flink Committer,深度参与了Hadoop,Hive,Spark,Flink等开源项目的研发工作,对于SQL引擎,分布式系统有较为深入的了解和实践,目前主要专注于EMR产品中开源计算引擎的优化工作。
内容介绍:
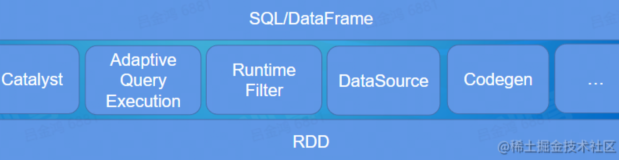
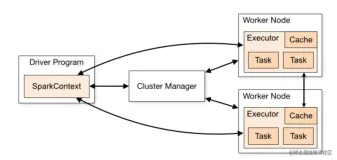
主要介绍Relational Cache/物化视图的历史和背景,以及EMR Spark基于Relational Cache加速Spark查询的技术方案,及如何通过基于Relational Cache的数据预计算和预组织,使用Spark支持亚秒级响应的交互式分析使用场景。