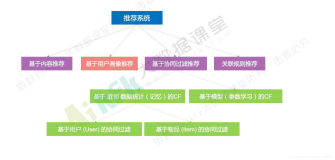
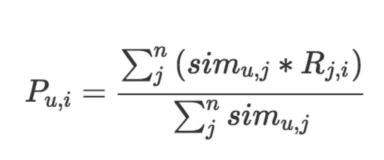协同过滤
为了解决基于内容过滤的一些限制,协同过滤同时使用用户和项目之间的相似性来提供推荐。这样会允许偶然的推荐出现; 也就是说,协同过滤模型可以基于类似用户B的兴趣向用户A推荐项目。此外,可以自动学习embedding特征,而不依赖于手工设计的特征。
电影推荐示例
假设现有一个电影推荐系统,其中训练数据由反馈矩阵组成,其中:
- 每行代表一个用户。
- 每列代表一个项目(电影)。
有关电影的反馈分为两类:
- 显式 - 用户通过提供数字评级来指定他们对特定电影的喜爱程度。
- 隐含 - 如果用户观看电影,系统会推断出用户对其感兴趣。
为简化起见,我们假设反馈矩阵是二进制的; 也就是说,“1”表示对电影感兴趣, "0"表示对其不感兴趣。
当用户访问主页时,系统应根据以下两者推荐电影:
- 与用户过去喜欢的电影相似;
- 类似用户喜欢的电影;
为了便于说明,让我们设计下表中描述电影的一些特征:
| 电影 | 评分 | 描述 |
|---|---|---|
| 黑暗骑士崛起 | PG-13 | 蝙蝠侠在DC Comics宇宙中设置的黑暗骑士续集中努力拯救Gotham City免受核毁灭 |
| 哈利·波特与魔法石 | PG | 一个孤儿发现他是一名巫师,并在霍格沃茨魔法学校就读,在那里他完成了他与邪恶伏地魔的第一场战斗 |
| 史莱克 | PG | 一个可爱的食人魔和他的伙伴开始执行救援公主菲奥娜的任务,菲奥娜被龙囚禁在她的城堡里 |
| 贝尔维尔三胞胎 | PG-13 | 当环法自行车赛冠军在环法自行车赛期间被绑架时,他的祖母和狗在在三位年长的爵士歌手的帮助下,拯救了他 |
| 纪念品 | [R | 一个失忆症人拼命寻求通过在他的身体上纹身线索来解决他妻子的谋杀案。 |
1维嵌入
假设我们为每部电影分配一个标量 [-1,1]描述电影是针对儿童(负值)还是成人(正值)。假设我们还为每个用户分配一个标量[-1,1]描述用户对儿童电影(接近-1)或成人电影(接近+1)的兴趣。对于我们期望用户喜欢的电影,电影嵌入和用户嵌入的产品应该更接近1。
还是成人电影(右)。 用户的位置描述了对儿童或成人电影的兴趣。")
在下图中,每个复选标记标识出特定用户观看的电影。很明显,第三和第四个用户具有通过该特征很好地解释的偏好:第三个用户更喜欢儿童电影,而第四用户更喜欢成人电影。然而,该一维特征并没有很好地解释第一和第二用户的偏好。
,使得两个嵌入的乘积近似于反馈矩阵中的地面实况值。")
2维嵌入
一维特征不足以解释所有用户的偏好。为了克服这个问题,让我们添加第二个特征:每部电影是爆米花电影或艺术片的程度。通过第二个特征,我们现在可以使用以下二维嵌入来表示每部电影:
还是成人电影(右); 它沿垂直轴的位置描述了这是一部重磅电影(上)还是一部艺术电影(下图)。 用户的位置反映了他们对每个类别的兴趣。")
我们再次将用户置于相同的嵌入空间中以最好地解释反馈矩阵:对于每个(用户,项目)对,我们希望当用户观看时,用户嵌入和电影嵌入的点积接近1, 否则为0。
,使得两个嵌入的点积近似于反馈矩阵中的基础真值。")
注意:我们在同一个嵌入空间中表示了项目和用户,可以将嵌入空间视为项目和用户共有的抽象表示,因此,我们可以使用相似性度量来衡量相似性或相关性。
在这个例子中,我们手工设计了嵌入。实际上,嵌入可以自动学习,这是协同过滤模型的强大功能。
当模型学习嵌入时,这种方法的协同性质是显而易见的。假设电影的嵌入向量是固定的。然后模型可以为用户学习嵌入向量,并能最好地解释他们的偏好。因此,具有相似偏好的用户的嵌入向量将紧密结合在一起。类似地,如果用户的嵌入向量是固定的,那么我们可以学习电影嵌入以最好地解释反馈矩阵。最终,类似用户喜欢的电影嵌入将在嵌入空间中相近。