更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
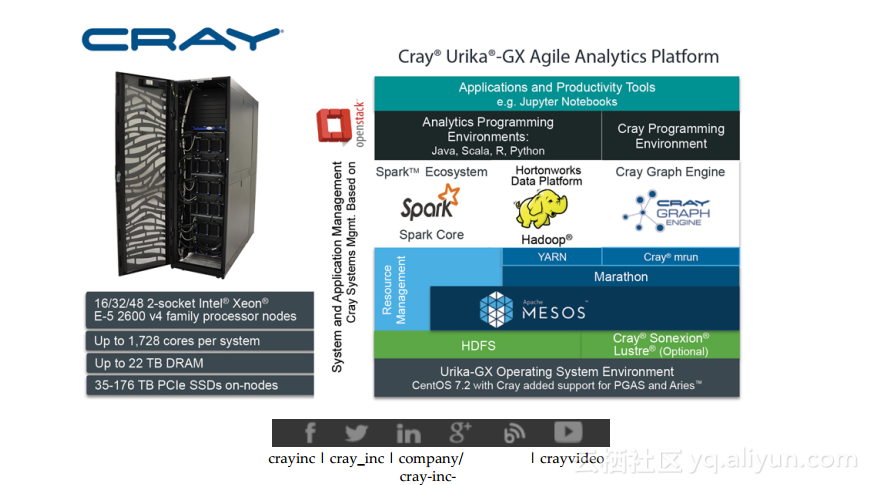
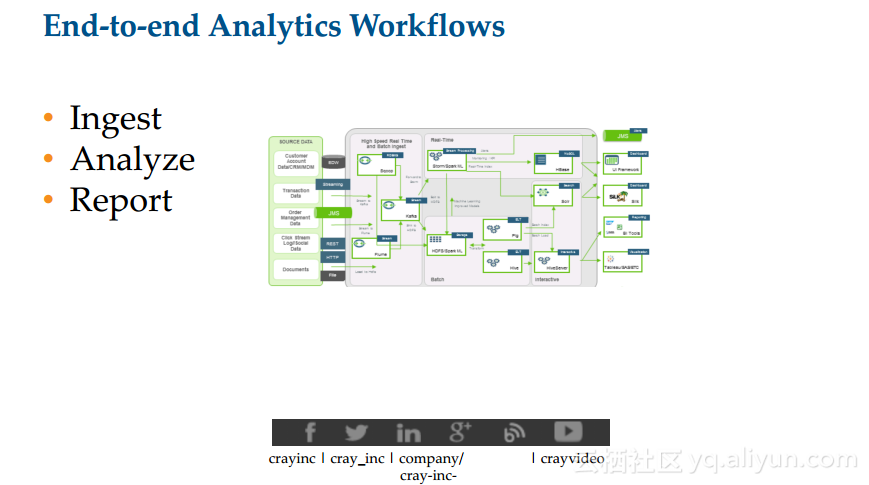
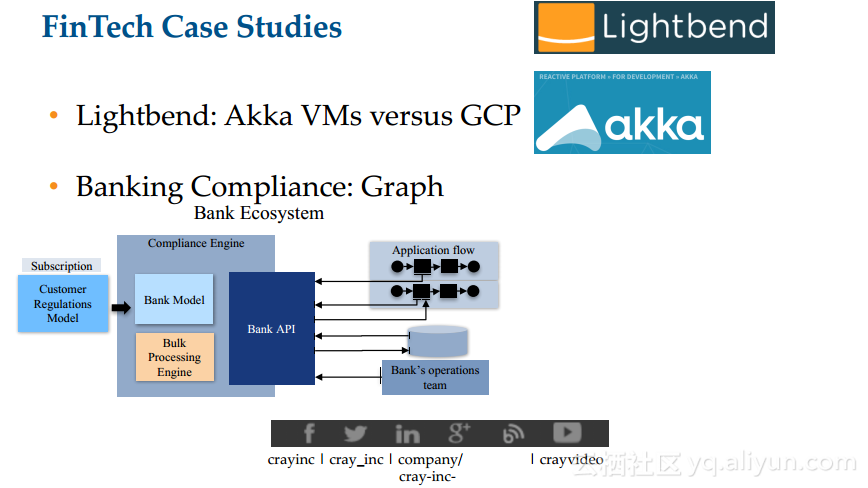
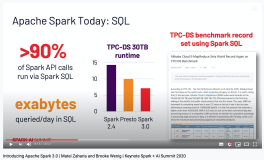
本讲义出自Anthony DiBiase在Spark Summit East 2017上的演讲,主要分享了如何为了大规模地部署服务压缩软件开发周期,并分享了应对自动化决策和模型的复杂性和基于Spark 的机器学习解决方案,演讲中还对于Cray超级计算机进行了介绍。