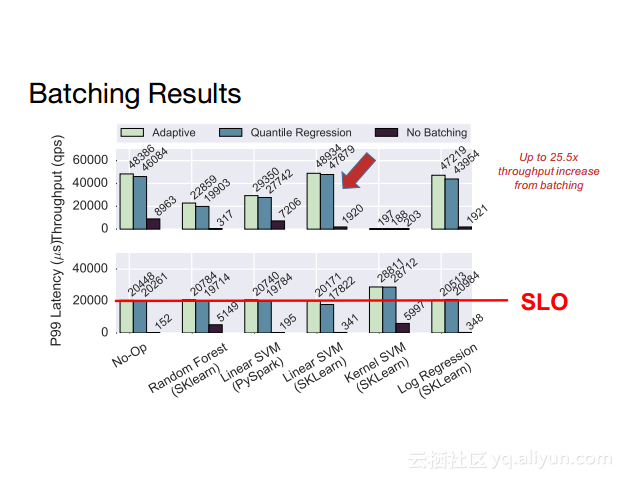
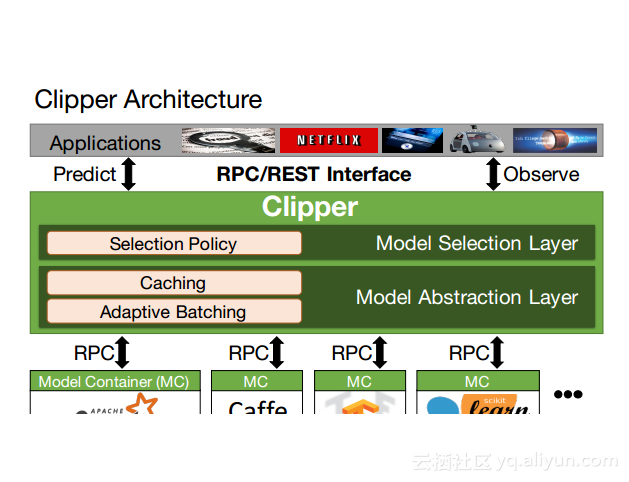
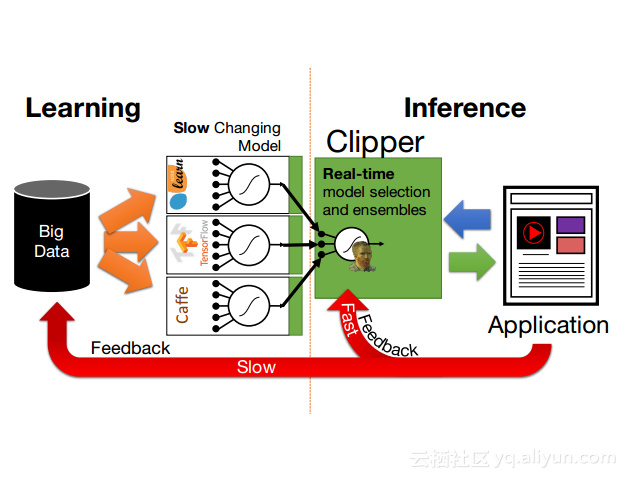
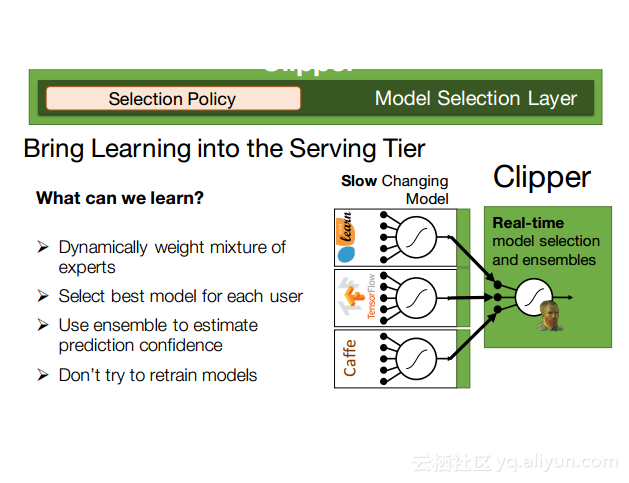
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
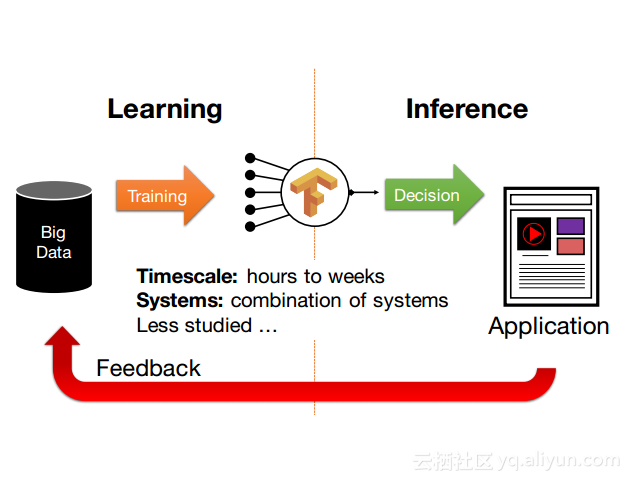
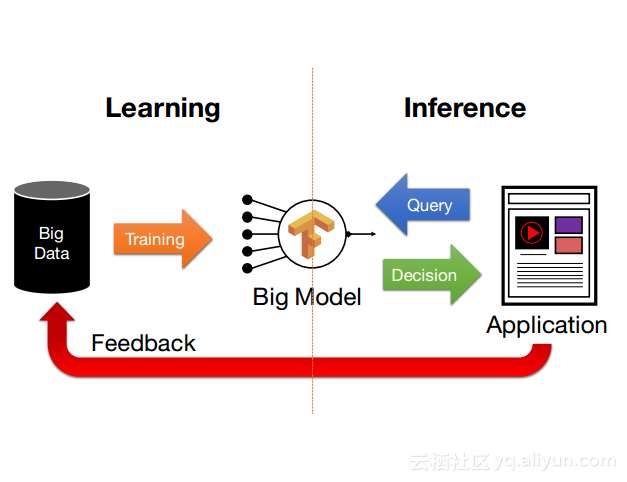
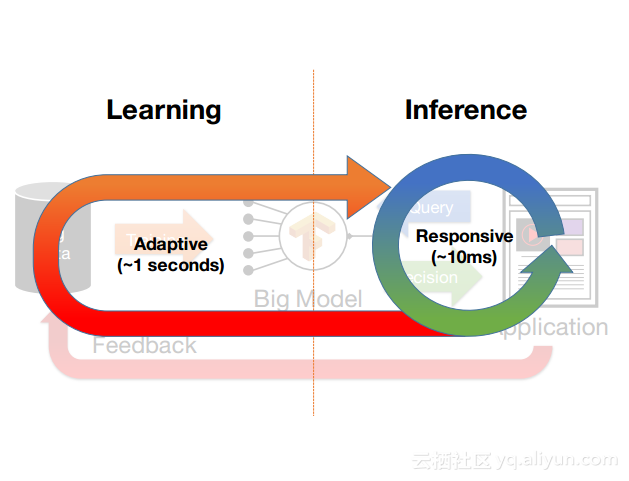
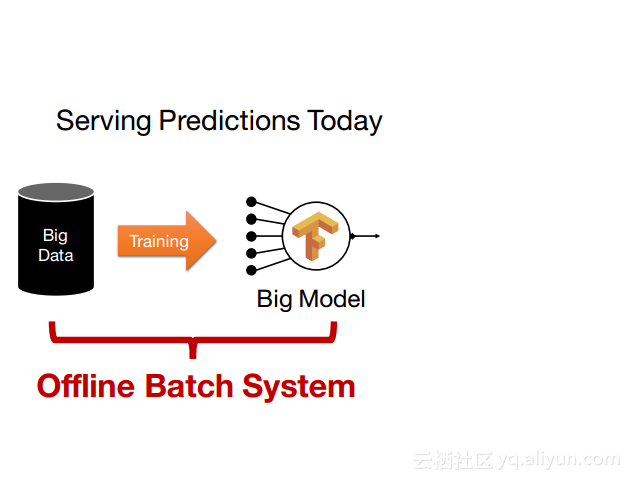
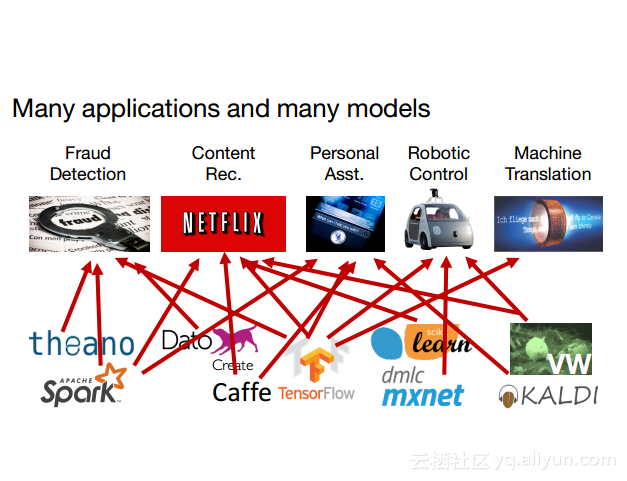
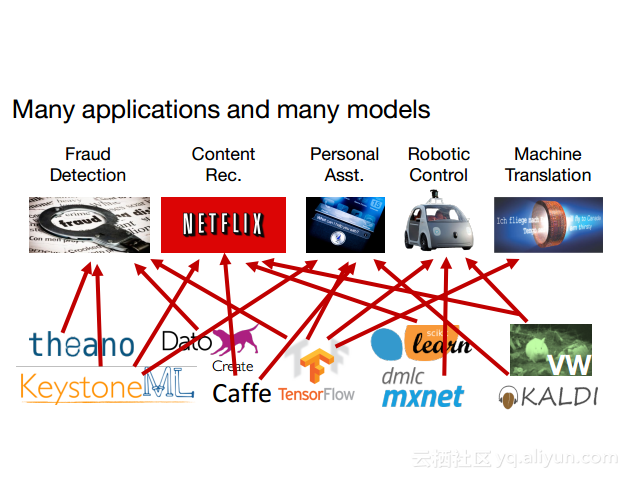
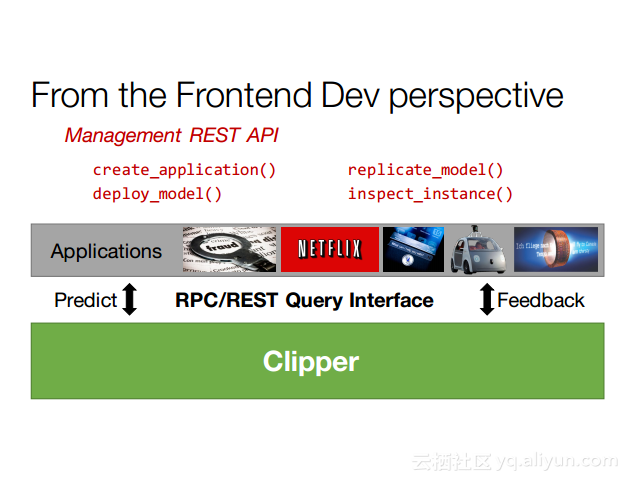
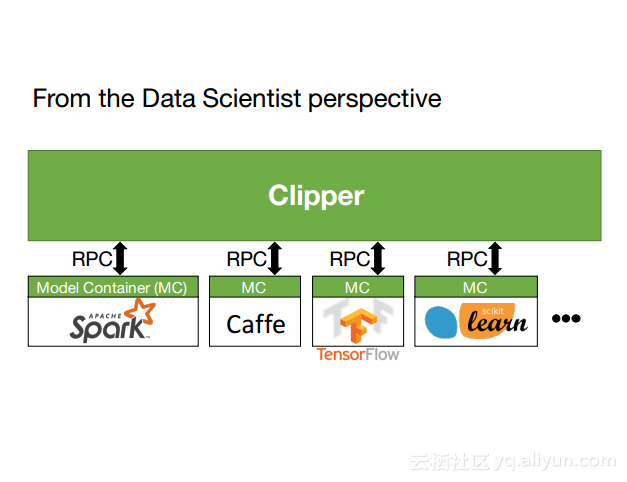
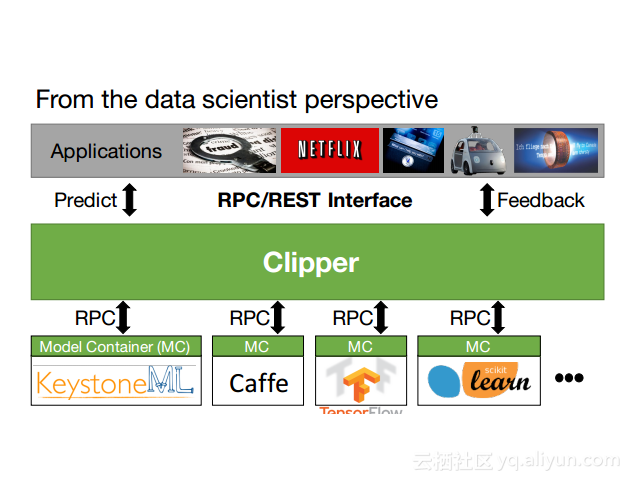
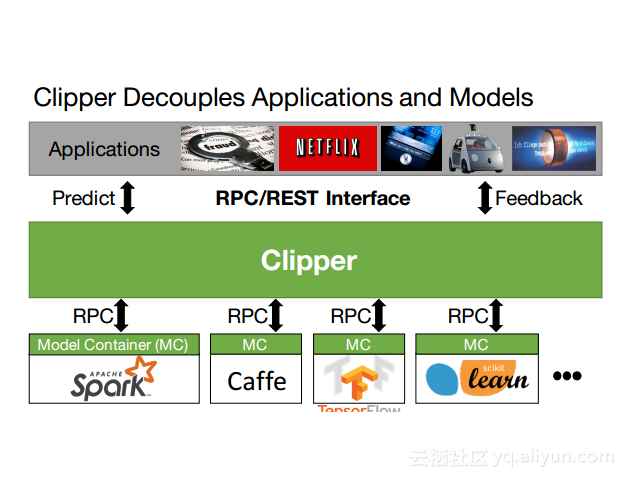
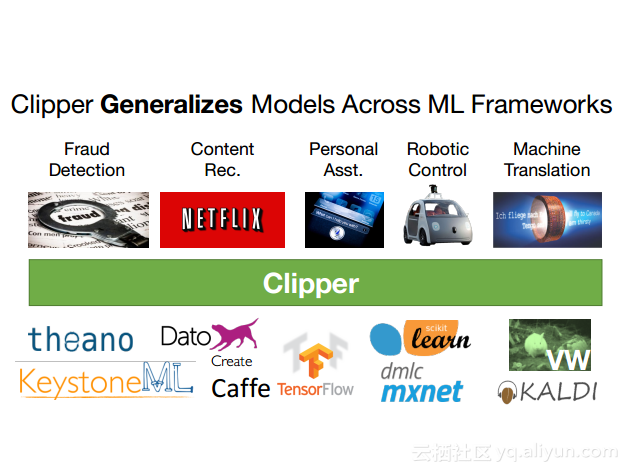
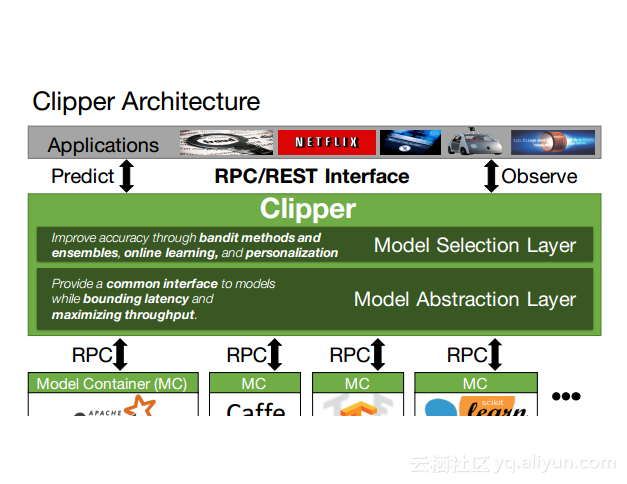
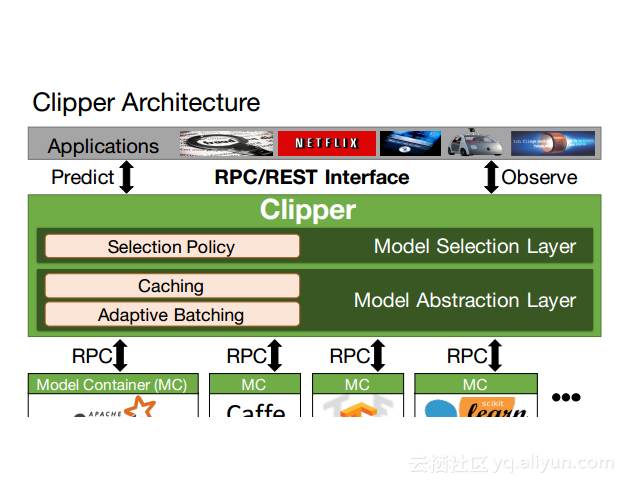
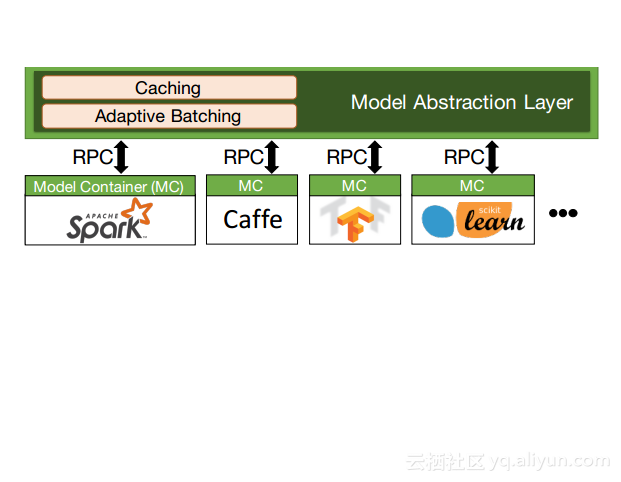
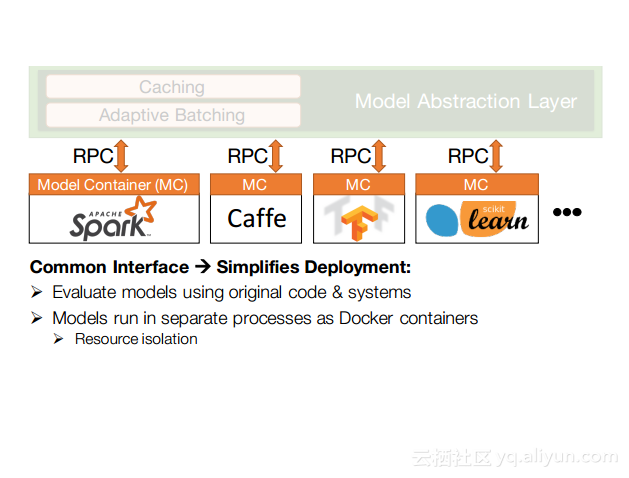
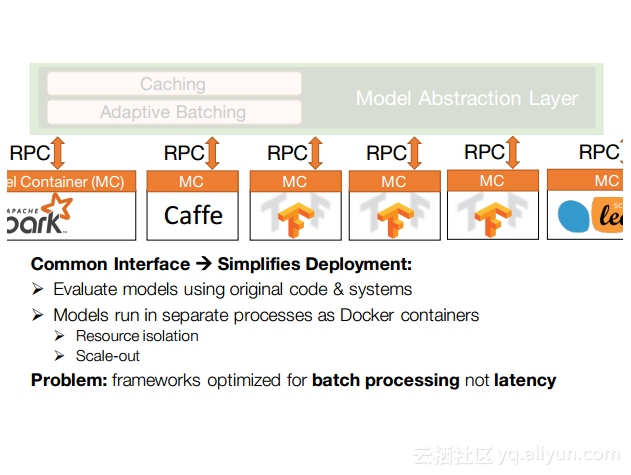
本讲义出自Dan Crankshaw在Spark Summit East 2017上的演讲,主要介绍了Clipper——一个通用的低延迟预测服务系统,介于最终用户应用程序和各种机器学习框架之间的Clipper模块化的体系结构来简化对于模型的跨框架部署,此外,Clipper通过引入缓存、批处理和自适应模型选择技术,减少了预测延迟并且提高了吞吐量和预测精度以及系统的鲁棒性。