更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
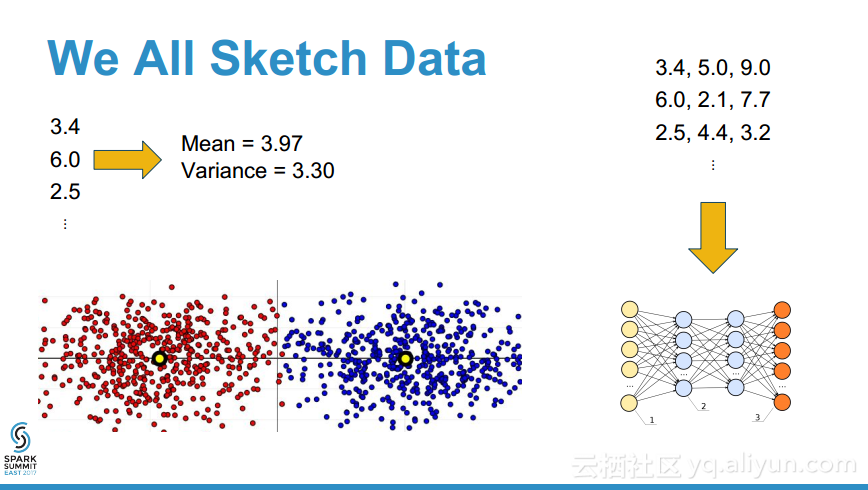
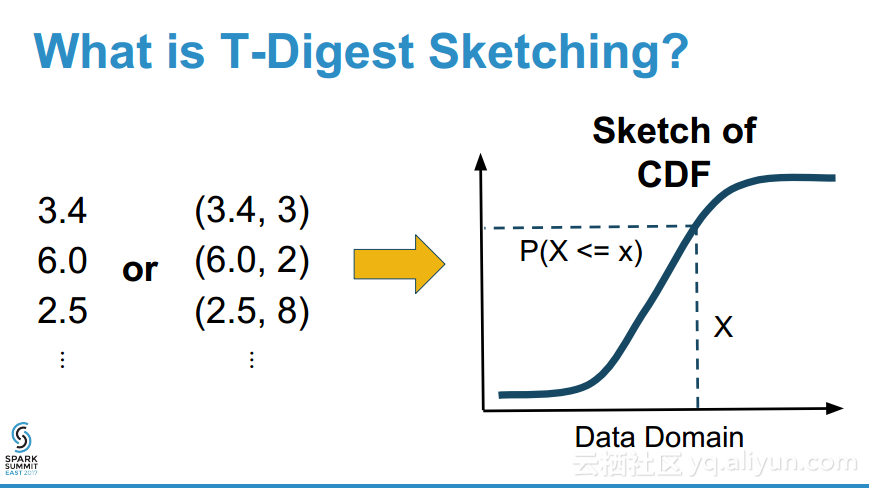
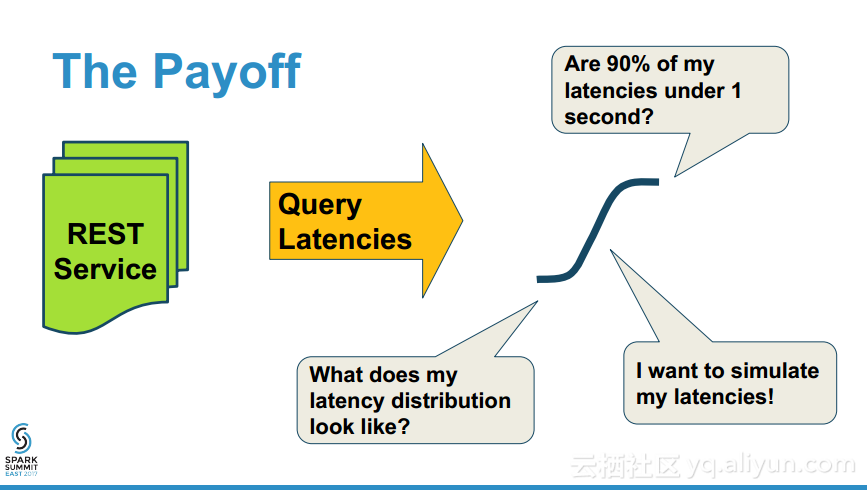
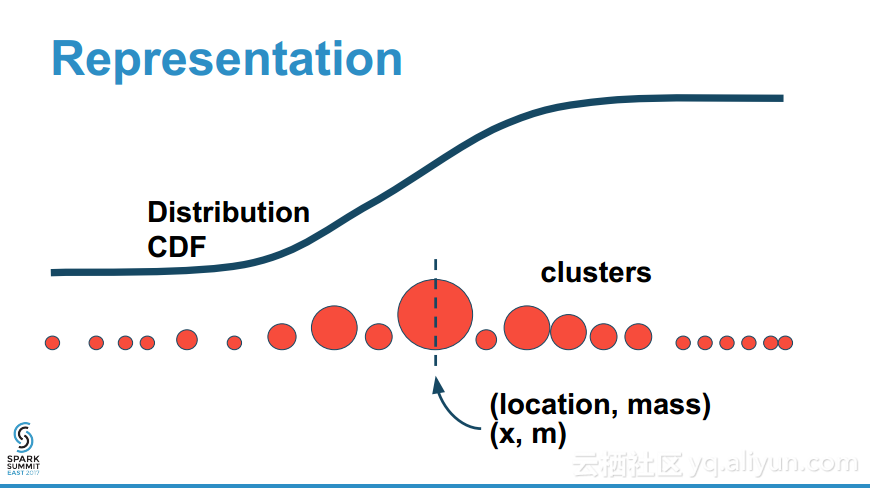
本讲义出自Erik Erlandson在Spark Summit East 2017上的演讲,大型数据集的草图概率分布的算法是现代数据科学的一个基本构建块,草图在可视化、优化数据编码、估计分位数以及数据合成等不同的应用中都有应用之地,T-Digest是一个通用的的草图的数据结构,并且非常适合于map-reduce模式,演讲中演示了Scala原生的T-Digest草图算法实现并证实了其在Spark的可视化展示、分位数估计以及数据合成的作用。