更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
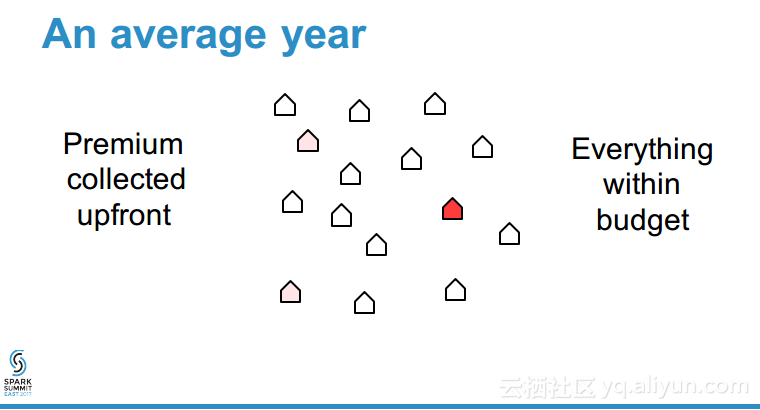
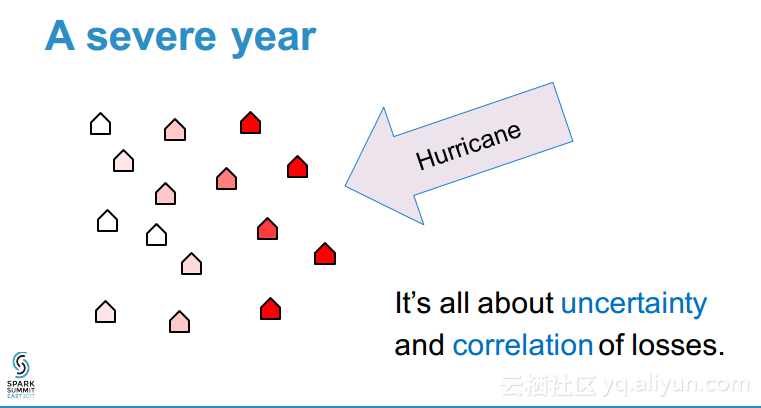
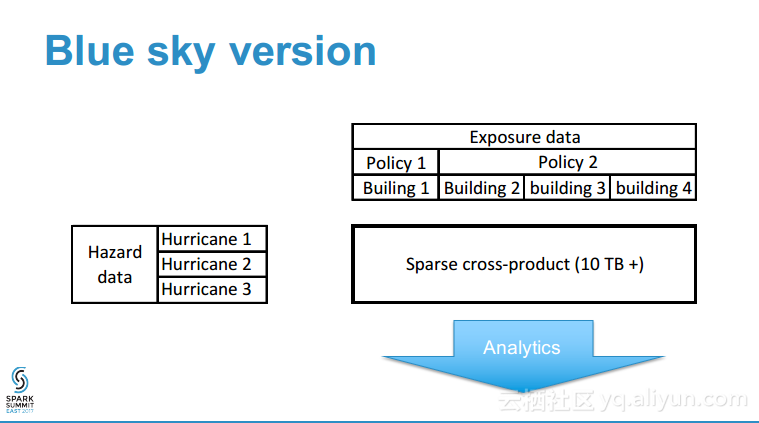
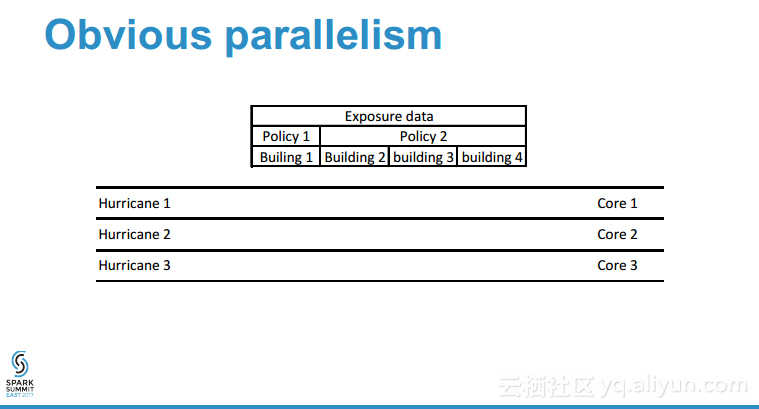
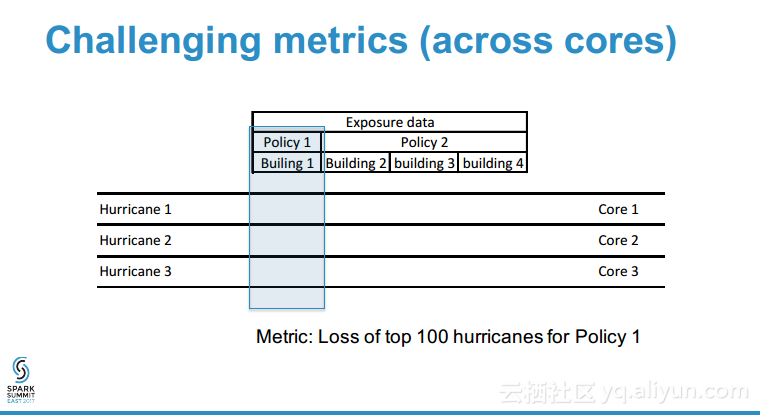
本讲义出自Shuai Zheng在Spark Summit East 2017上的演讲,分保公司的核心竞争力在于与像飓风和地震这样的灾难的风险量化评估能力,各种所谓的灾难模型往往是的公开的,可以获取到,但是处理这样灾难模型的数据量需要大数据能力和高性能,本讲义就介绍了如何使用Spark对于灾难性事件进行建模,并通过更加独特的理解获取核心竞争力。