11+大数据行业应用实践请见
https://yq.aliyun.com/activity/156
,同时这里还有流计算、机器学习、性能调优等技术实践。
此外,通过
Maxcompute及其配套产品
,低廉的大数据分析仅需几步,详情访问
https://www.aliyun.com/product/odps
;更多精彩内容参见
云栖社区大数据频道
:
https://yq.aliyun.com/big-data
。
江苏佰腾科技有限公司成立于2006年,是一家专业从事知识产权服务的高科技服务企业,国内知名的知识产权服务机构,江苏省最大的民营知识产权综合服务机构。 佰腾科技以专利信息应用和专利咨询服务为核心,面向国内外用户提供专利信息检索、专利大数据应用开发、专利代理服务、专利预警分析、专利战略研究、知识产权贯标辅导、知识产权管理、专利技术成果转化交易等服务,为客户提供知识产权、科技创新的整体解决方案。
佰腾科技的专利信息检索平台(专利探索者)已经持续研发了10年,是目前国内最知名的免费面向公众服务的大数据应用平台,为中国专利事业的发展做出了很多的突出贡献。
近日,笔者有幸与佰腾科技大数据团队进行交流,就专利大数据领域现状与实践进行了探讨。
以下为实录:
YQ:贵公司主要使用大数据来解决哪些方面的问题,想借助大数据取得哪些成果?
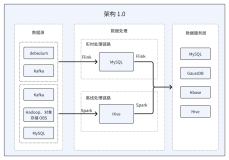
佰腾科技大数据团队:佰腾科技专注为客户提供最好的专利信息和技术创新服务,我们所依赖的核心就是专利信息的数据挖掘,以及与专利信息相关的其它延展信息的数据挖掘,如全球期刊文献、法律诉讼、企业信息等。专利信息的『大数据』与其它领域的『大数据』多少有些不同,虽然全球专利信息的总量仅在1亿多条,但是每条专利信息要分析获取的数据维度目前就多达200多项,实际处理的数据量在百亿级别。同时,针对各种客户的不同需求,我们还要基于这些数据实现数百种的分析模型和方法,从中挖掘出专利信息的深层次价值。
在我们的业务处理场景中,我们需要经常性的对原始数据进行维度的挖掘和测试,以确保数据维度满足客户分析应用的要求。以前,我们在自建的环境中进行一次回归数据处理要花费近一周的时间,如果中途发现错误还会导致大量的时间浪费,效率非常低下。而在使用了数加大数据基础服务之后,这个时间缩短到了小时级别,数据回归处理的风险大幅下降,数据分析工程师可以在更快的时间内验证分析模型和方法,效率提升非常显著。
另外,随着我们对专利信息维度挖掘的深入,我们对于信息挖掘的需求正在从『文字表述』向『逻辑概念』转移,比如我们希望从专利信息中挖掘出技术概念并发现它们之间的关系,这样我们就能帮助客户更好的分析技术发展的趋势和热点。目前我们正在推进专利信息深度挖掘技术的研发,借助数加平台的机器学习以及数据分析能力,为我们的客户提供更加精准、更加全面、更个性化的专利大数据应用服务。
YQ:在大数据实践的过程中,你们业务场景中的主要挑战有?
佰腾科技大数据团队:我们的挑战主要来自于三个方面:
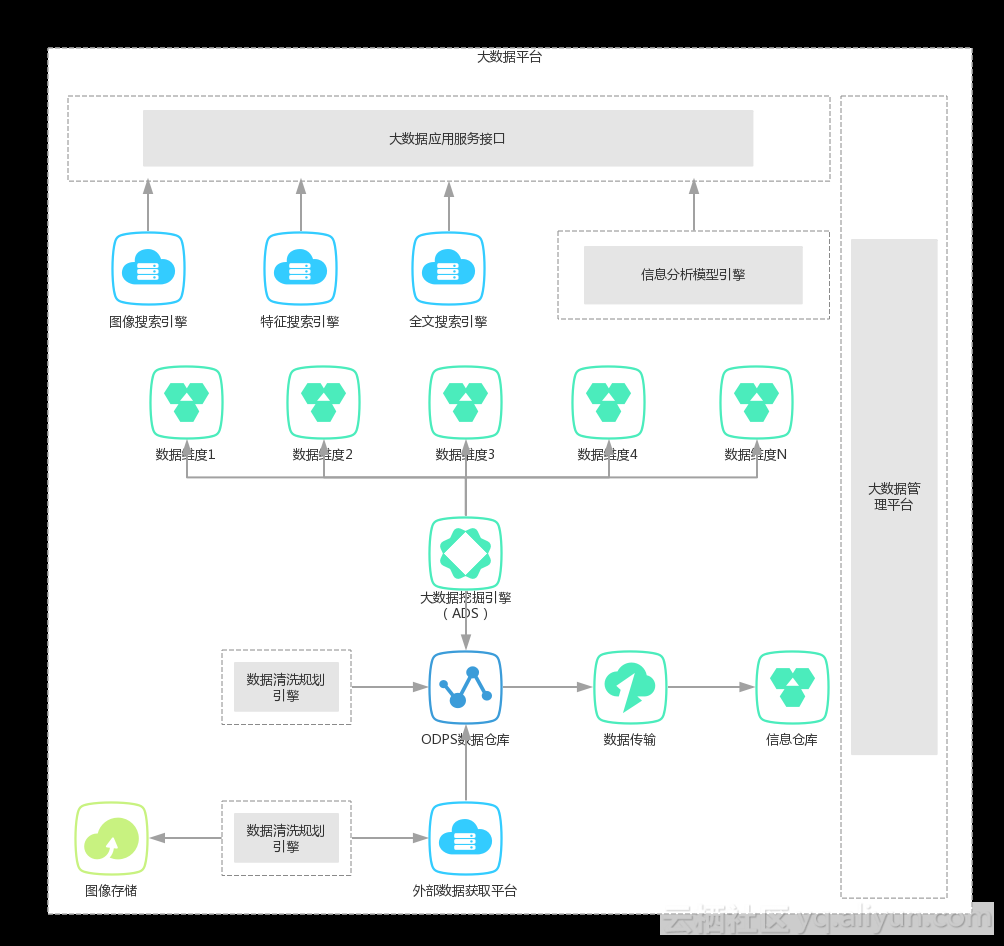
- 专利大数据处理的维度内容越来越多,数据量也越来越大,我们原有的以文本搜索为核心的数据框架平台亟待升级,未来我们需要把数加的能力融合到我们的新数据框架平台上,实现对数据的获取、清洗、挖掘、分析、应用的全周期的数据管理、监控和开发支撑。
- 专利大数据的深度挖掘越来越需要依赖新的数据挖掘技术,比如文本聚类、机器学习、图像识别等,而我们不可能建立并拥有研发这些技术的专业团队,我们认为数加平台可以在我们的领域内给予针对性的能力支撑。
- 专利大数据的应用是一个实践性非常强的领域,随着客户应用需求的不断提升, 我们需要不断更新分析和展示数据结果的模型和方法,这里面不仅有提升数据处理效率的问题,也有提升数据分析应用能力的问题。
YQ:阿里云数加的哪些特性帮助你们解决了这些问题?
佰腾科技大数据团队:数加平台的MaxCompute 解决了我们数据存储量大的问题,保证了数据的安全性和完整性;平台的任务开发功能很好的解决了数据处理过程中流程标准化的问题,可以将任务托管后自动化执行,解放我们双手;分布式的框架结构解决了多任务的并发处理问题, 提高了任务处理的速度,实现了数据价值的快速挖掘,避免了我们自己开发系统存在的诸多不稳定问题;机器学习平台降低了算法的学习成本,也可利用既有的数据模型算法解决数据挖掘过程中的问题。 我们使用的服务有:数据存储、数据处理、流程任务、机器学习。
使用数加平台后,我们的数据存储和处理效率有了大幅提升。在我们自建的环境里进行一次回归数据处理需要7 天时间,而使用数加平台处理只需要3~6 个小时。这些效率的提升可以缩短我们数据分析应用产品的研发周期,并能更好的提高这些产品的需求符合度。
YQ:当初是什么原因促使您选择阿里云数加产品的?
佰腾科技大数据团队:
- 我们自建环境储存数据的代价高昂,不利于大量数据的安全存储和快速处理。
- 我们自建环境和原有数据框架平台对大数据处理的速度很慢,不能适应业务需求的快速变化。
- 我们原有的数据框架平台已使用多年,技术比较落后,已经不能很好的支撑新的大数据研发需求。
- 阿里云在国内大数据技术方面处于领先地位,也是最早进行大数据云化的平台,我们信任阿里云数加平台的能力。
YQ:对比云服务和自建大数据基础设施,你们是怎么衡量的?
佰腾科技大数据团队:云服务最大的特点就是只管使用服务,不需要关心底层技术架构、安全性、可靠性、稳定性等方面的问题。自建大数据基础设施需要采购和维护大量硬件设备,部署和配置复杂的系统环境,需要耗费大量资源保证服务的持续、稳定运行,并且对于运维人员的要求会更高。
对于我们专利大数据处理业务来讲,云服务是我们整个业务系统依赖的重要基础,能帮助我们节省大量的基础建设费用。同时,我们也会根据自身业务的需求,对云服务进行进一步的开发,形成最有利于自身业务发展的大数据分析应用平台。
YQ:你们未来还想借助大数据实现的场景有?阿里云数加是否能满足你们的需求?如果没有,期待有哪些?
佰腾科技大数据团队:我们希望借助阿里云数加平台打造面向专利大数据分析应用的领域性大数据平台,并利用大数据技术实现对专利信息数据价值的深度挖掘,能帮助客户及时掌握全球技术发展的动态和热点,提高企业技术创新和知识产权保护的效率和成效。
目前我们已经将基础数据处理和部分数据挖掘的任务放在阿里云数加平台上完成,我相信数加平台会不断发展并支撑我们更多的大数据业务需求,让我们更多的大数据工作逐步实现云化。
我们期待阿里云数加平台能在文本数据挖掘、图像数据识别、数据关联分析等方面给予更多的能力支撑,助力专利大数据分析应用领域的快速发展。