更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
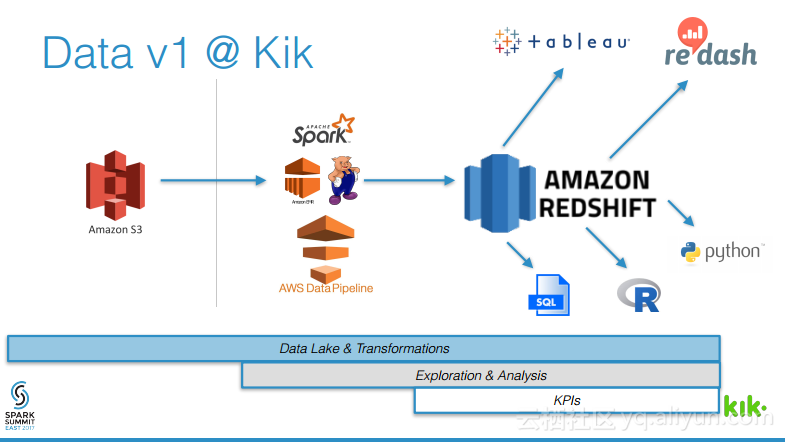
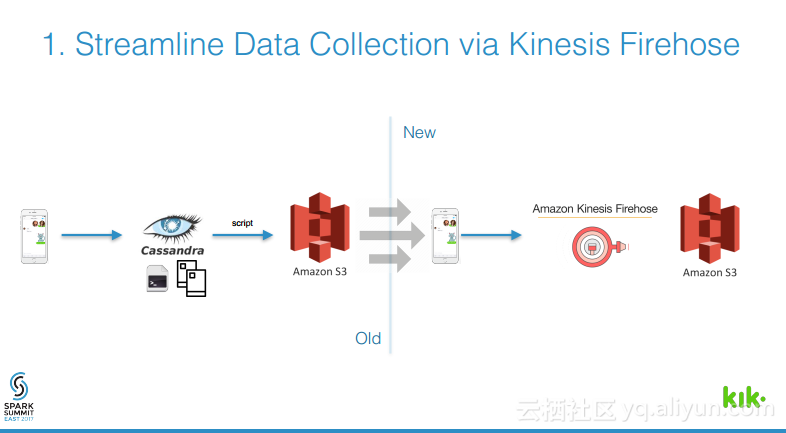
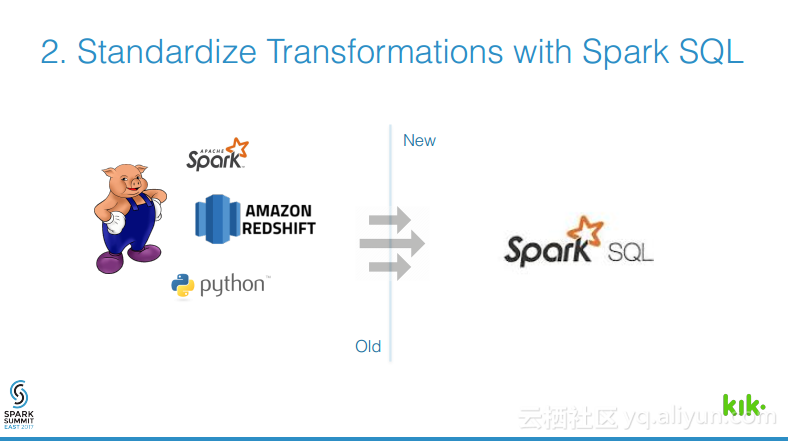
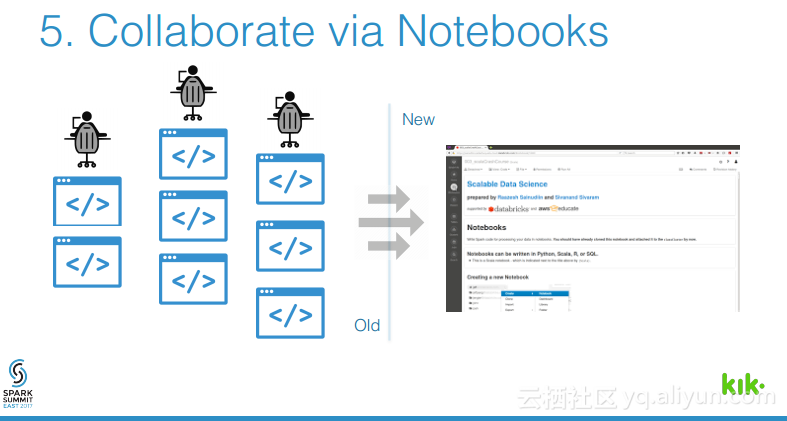
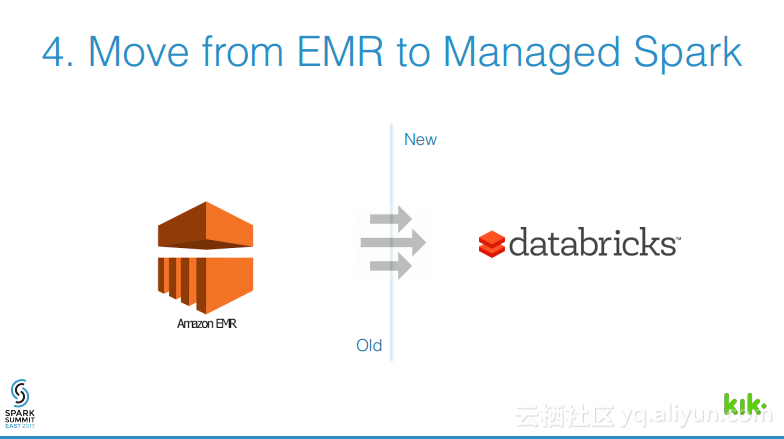
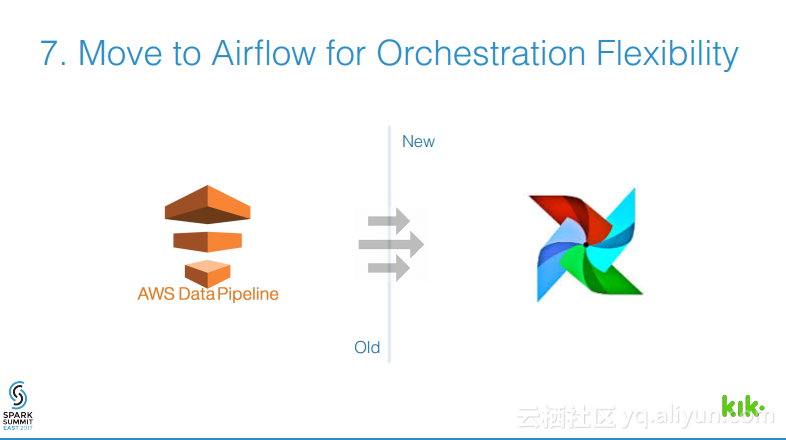
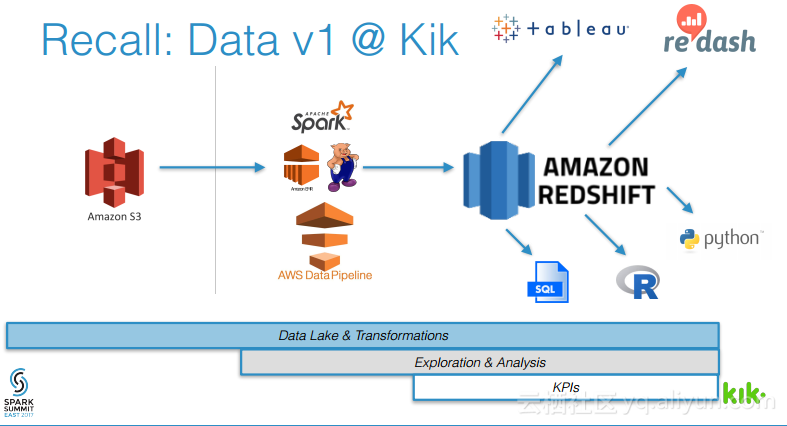
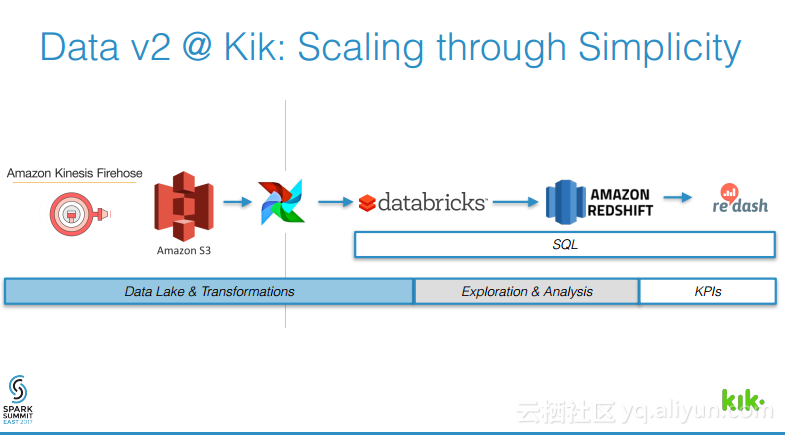
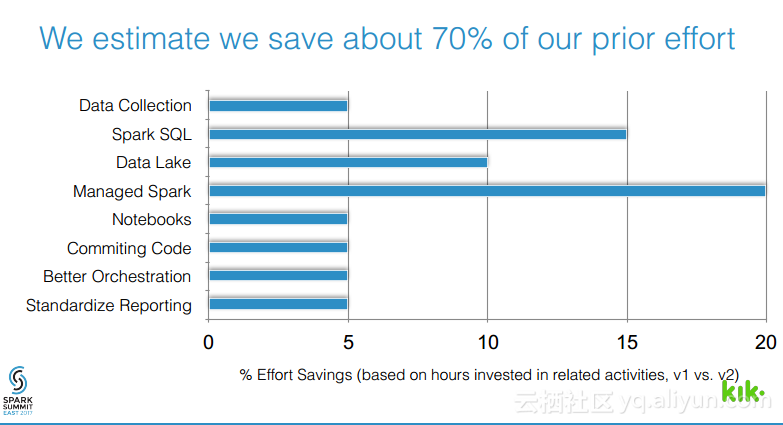
本讲义出自Joel Cumming在Spark Summit East 2017上的演讲,主要分享了使得3亿用户的聊天应用的数据工程量减少70%的8件事情,Joel Cumming与他的团队将数据栈从系统和进程的复杂结合体带入到可扩展、简单并且健壮的基于Spark和Databricks平台上,该平台将会使任何一家公司丢可以超级简单地使用数据。