更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
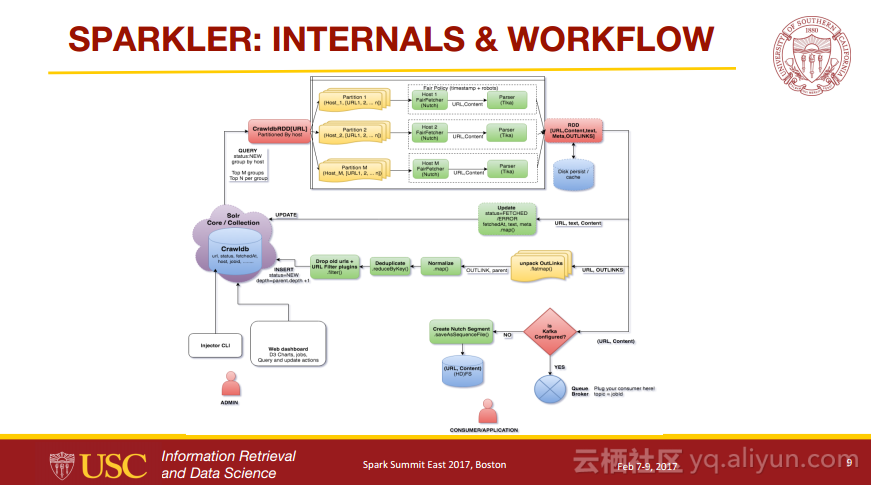
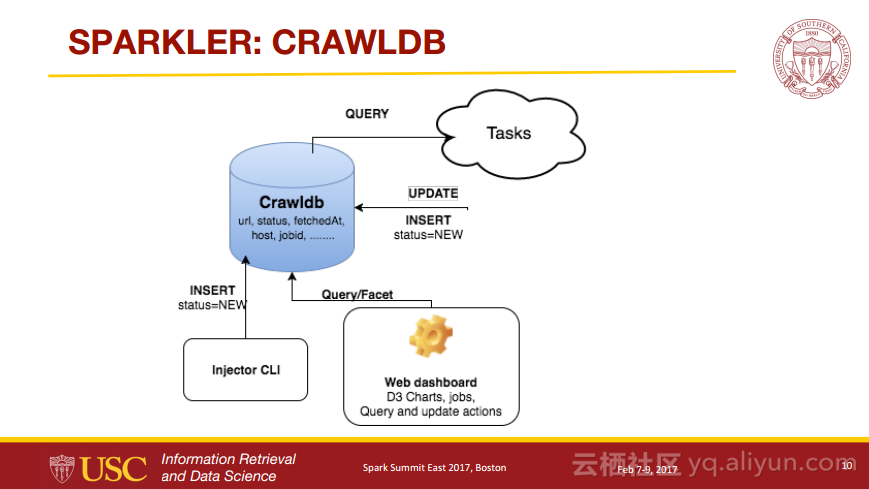
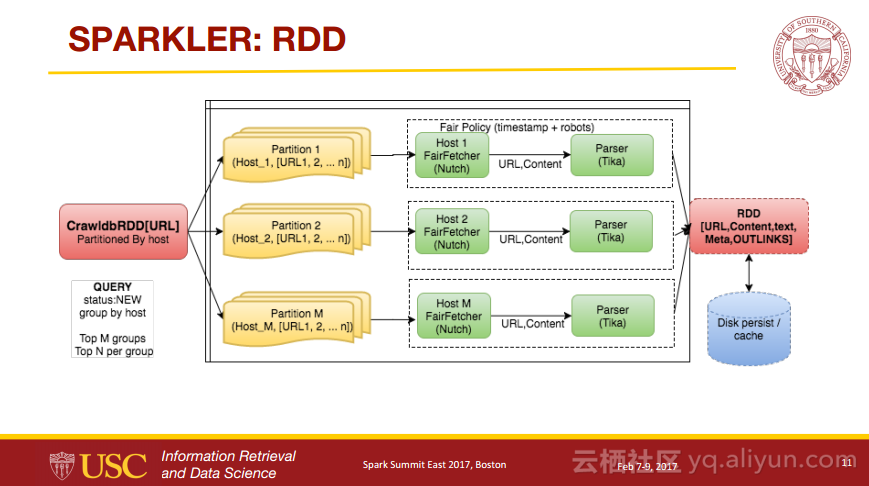
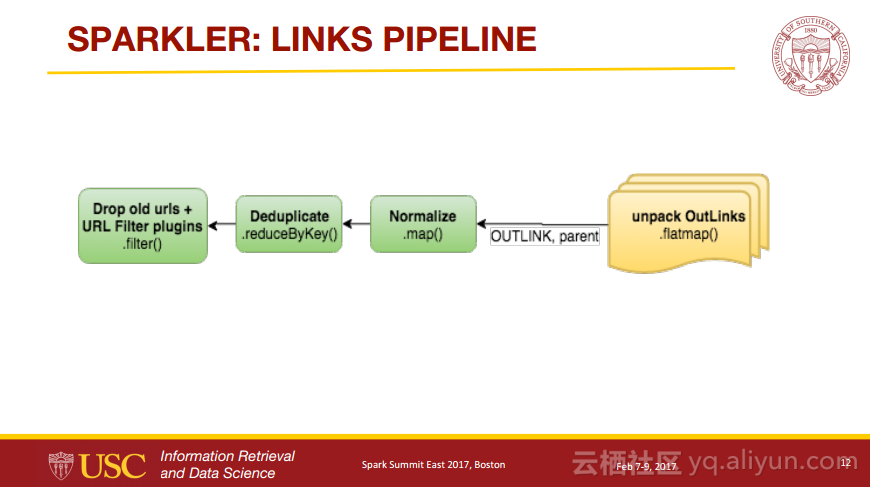
本讲义出自Karanjeet Singh与Thamme Gowda Narayanaswamy在Spark Summit East 2017上的演讲,主要介绍了利用了分布式计算和信息检索领域的最新发展技术并且组合了像Spark, Kafka, Lucene/Solr, Tika, 和Felix等各种Apache项目的爬虫程序——Sparkler,Sparkler是一个具有高性能、高扩展性以及高性能的网络爬虫程序,并且是运行在Spark上Apache Nutch的进化。