算法简介
数据集介绍
实验流程
实验总结
本文数据为虚构,仅供实验
本实验拟在介绍dsw和eas的使用。如果您有相关的需求,想要提高最终的效果,请联系我们。我们为您提供完整的解决方案和商业合作。
算法简介
本实验流程,拿到数据和对应的标签,此标签分为积极态度和消极态度。将对应的文本数据按照单个字(没有分割成单词)进行分割,利用word2vec将每个字训练成向量,拿到每个文本所有字的向量,切取前150个字的向量,送入lstm网络结构当中获取最后的输出值,在进行维度映射成2维的,进行binary_crossentropy损失,以此训练。预测的时候同理拿到每个字在我们已经训练号的word2vec的模型中的向量,然后送入模型,得到最后输出2维中最大的下标,即是我们对应的预测的态度。具体实现见代码代码及数据下载。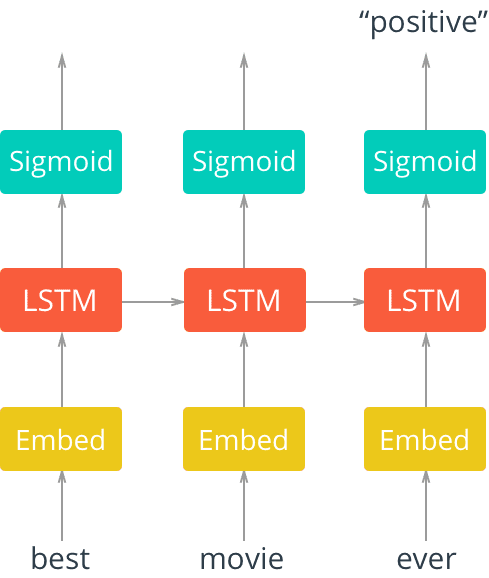
实验流程
本实验流程如下:
1:上传代码及数据至dsw平台
2:训练完成并将模型转换成savemodel格式
3:模型部署至EAS
4:API调用该模型
1、 上传代码及数据值dsw平台
(1).首先需要开通dsw-notebook平台,并创建一个实例。
(2).创建一个实例,计费方式随意,可以设置存储资源,完成之后后点击打开,进入Data Science Workshop页面。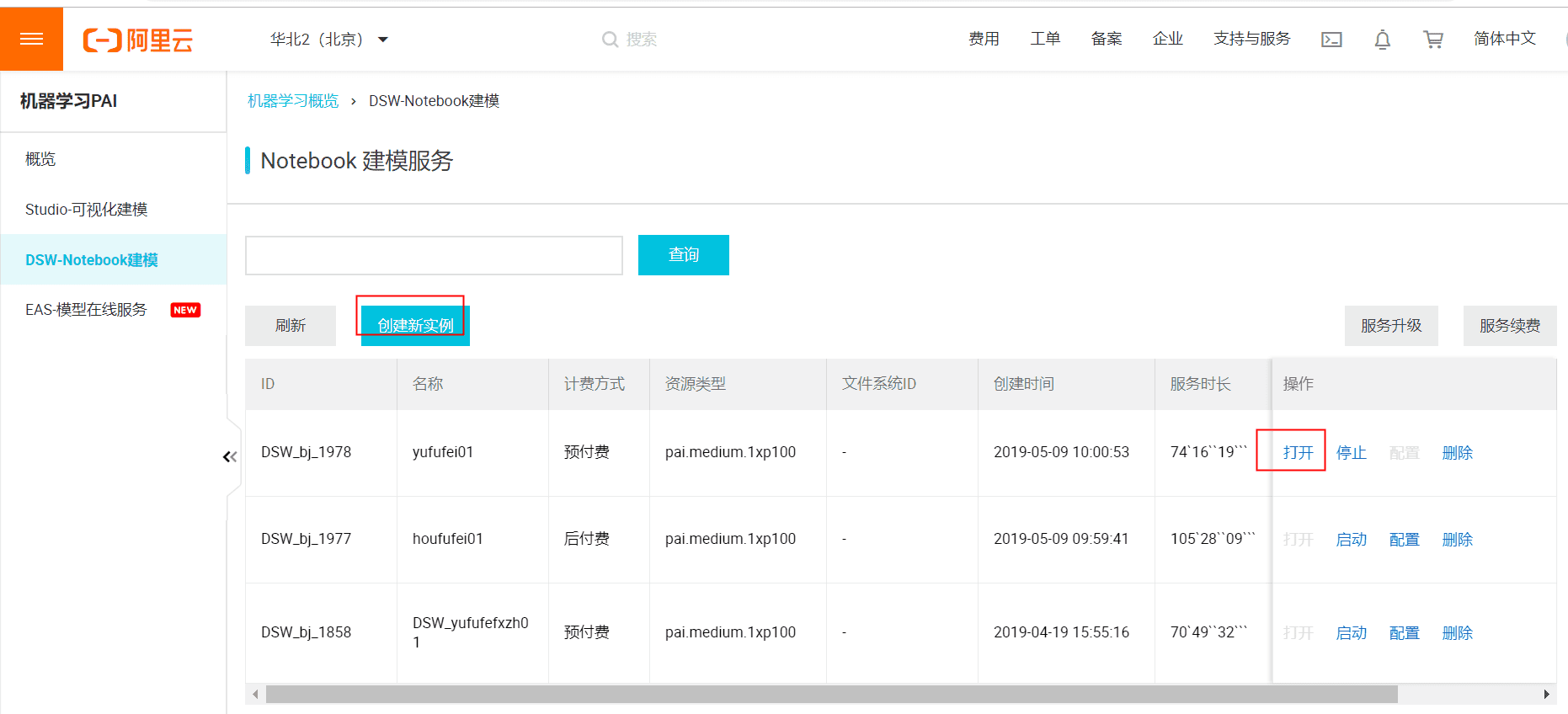
(3).选择对应的路径点击上传,上传本实验提供的代码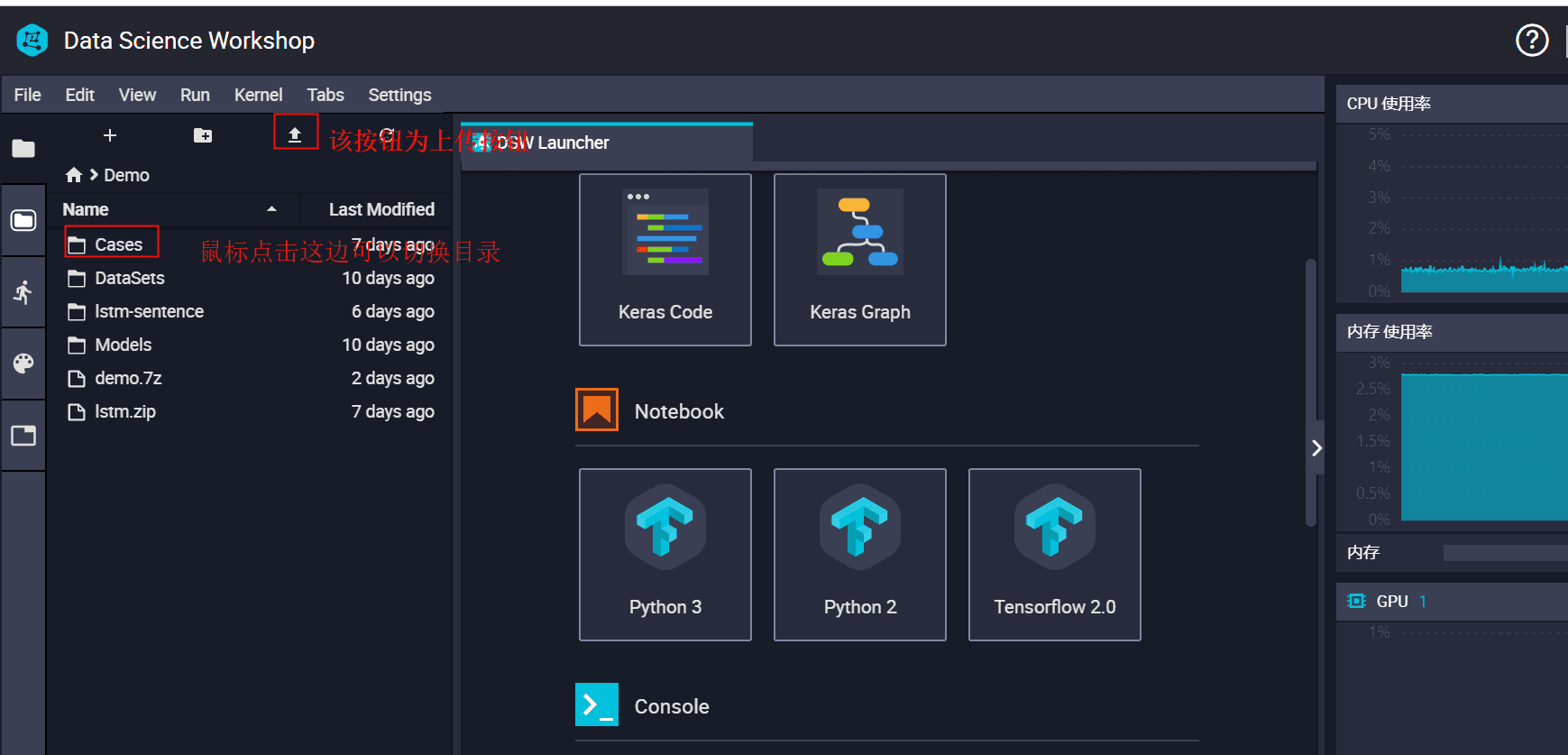
(4)打开一个Terminal,这和我们的linux操作是一样的,进入我们的上传目录,进行解压.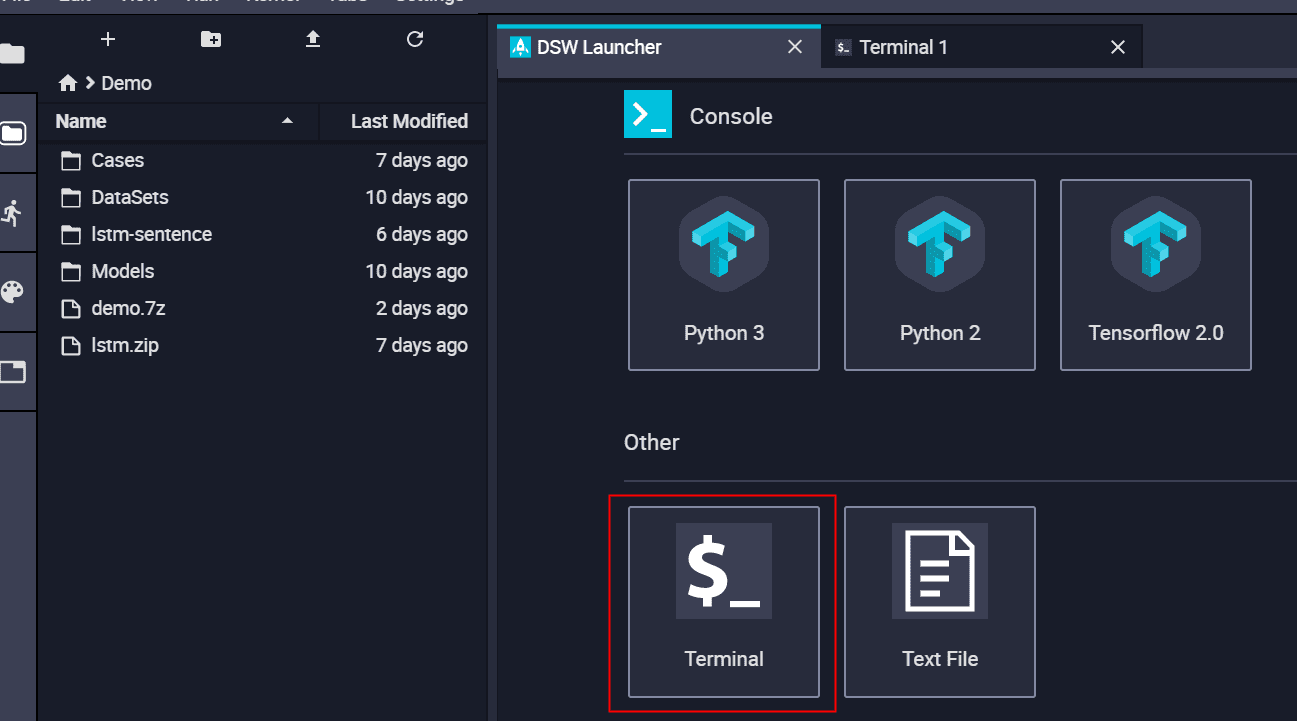
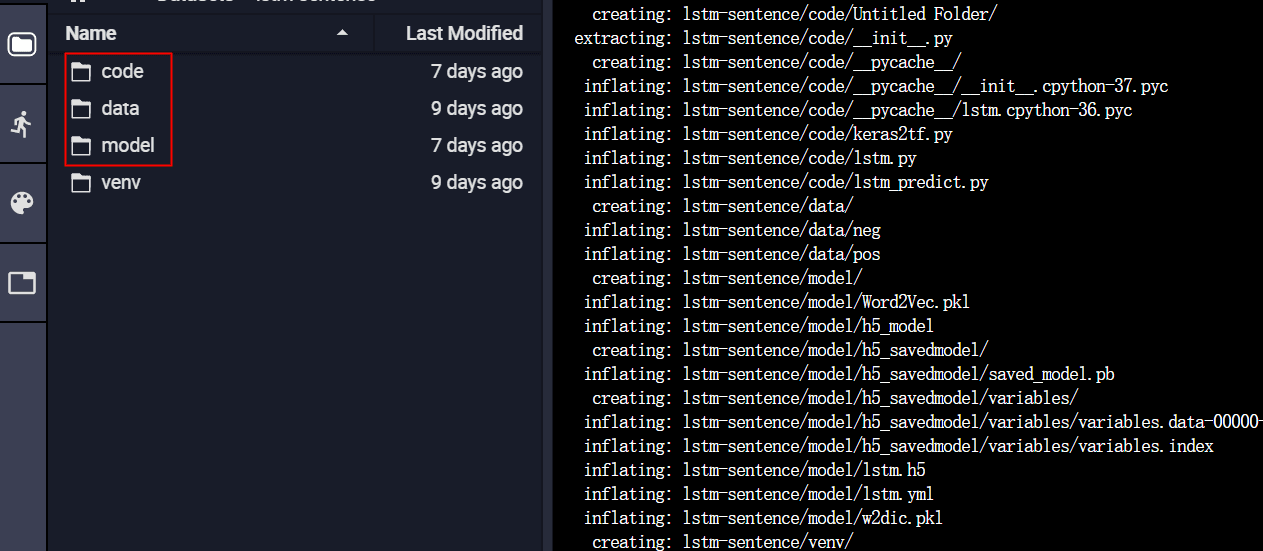
三个目录分别存放是的代码,数据,还有模型保存的检查点
(5).目录切换至我们的代码code目录下,直接执行python3 lstm.py开始训练模型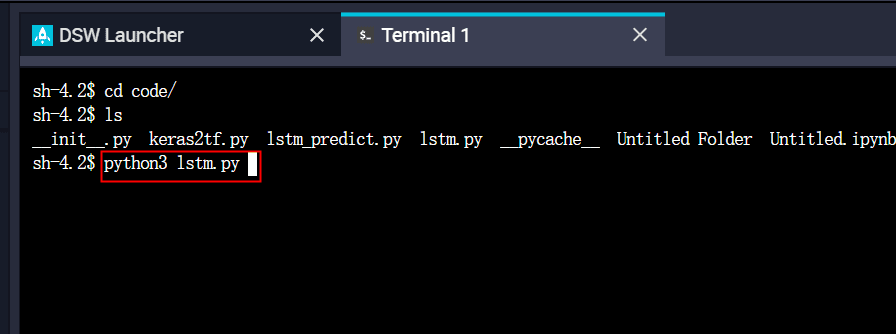
2、 训练完成并将模型转换成savemodel格式
训练完成后执行python3 keras2tf.py,将我们用keras训练号的模型转换成savemodel格式。
Keras2tf.py模型转换的代码参考文档:https://help.aliyun.com/document_detail/111030.html?spm=a2c4g.11186623.6.597.45056d37CkbuVw
代码如下:
import tensorflow as tf
def k2t():
with tf.device("/cpu:0"):
model = tf.keras.models.load_model('../model/h5_model') #keras生成的模型保存路径
tf.saved_model.simple_save(
tf.keras.backend.get_session(),
"../model/h5_savedmodel/", # 最后转换号的模型保存路径
inputs={"image": model.input}, # inputs的”image”这个名字需要记住,调用的时候会用到
outputs={"scores": model.output}
)
if __name__ == '__main__':
k2t()3、 模型部署至EAS
确保我们的eas已经购买过了,购买过请查看文档
(1).将我们的新生成的h5_savedmodel打包成.tar.gz,
(2)下载工具和后续上传参考文档https://help.aliyun.com/document_detail/111031.html?spm=a2c4g.11186623.6.598.46c635d5bonUkP
我们下载的是linux64对应的eascmd64,liunx中执行:wget 'http://eas-data.oss-cn-shanghai.aliyuncs.com/tools/eascmd64'
(3)将下载好的客户端eascmd64修改成可执文件,chmod 777 eascmd64
(4)在eascmd64目录下执行命令:./eascmd64 config –i myAccessKeyId -k myAccessKeySecret
执行成功后显示Configuration saved to: /home/admin/.eas/config
(5)再执行:./eascmd64 config –i myAccessKeyId -k myAccessKeySecret –e pai-eas.cn-beijing.aliyuncs.com
执行成功后显示Configuration saved to: /home/admin/.eas/config
(6)将tar.gz包上传,执行命令./eascmd64 upload h5.tar.gz –inner
执行成功后显示:
[OK] oss endpoint: [http://oss-cn-beijing-internal.aliyuncs.com]
[OK] oss target path: [oss://eas-model-beijing/1295715995194599/h5.tar.gz]
Succeed: Total num: 1, size: 6,359,719. OK num: 1(upload 1 files).上面的oss target path我们需要记住
(7)编写json文件,参考地址https://help.aliyun.com/document_detail/111031.html?spm=a2c4g.11186623.6.598.459c35d5TYzdsT
json文件内容如下: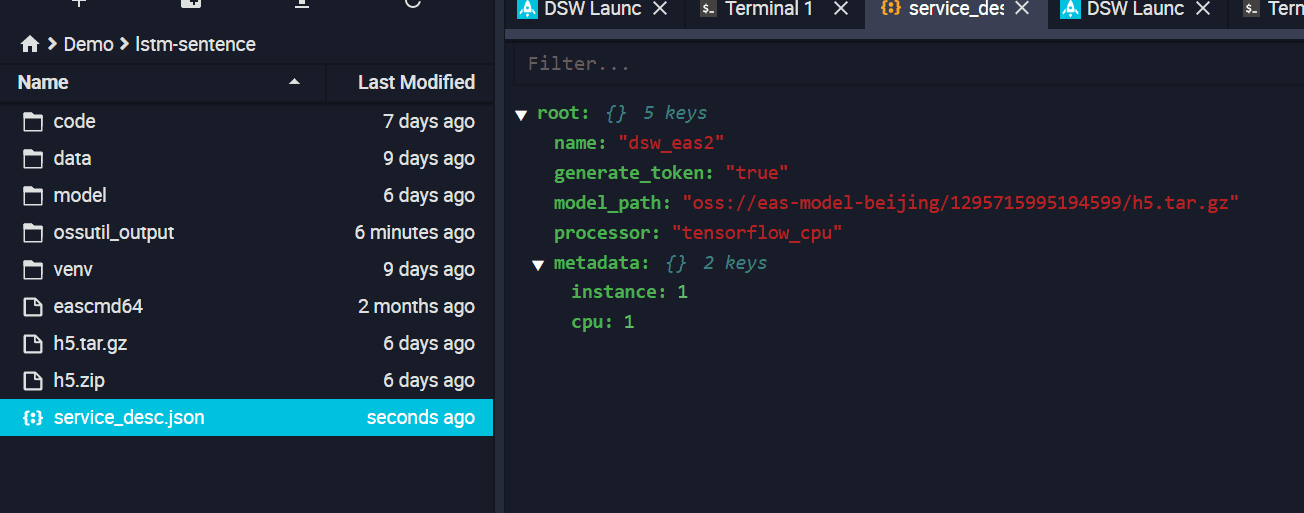
其中model_path就是我们步骤6返回的oss target path
(8)执行该json文件,将模型部署到eas
执行命令:./eascmd64 create service_desc.json
执行命令成功返回:
[RequestId]: 5B83E886-2C49-49BC-8440-325C7A3E8330
+-------------------+-----------------------------------------------------------------+
| Intranet Endpoint | http://pai-eas-vpc.cn-beijing.aliyuncs.com/api/predict/dsw_eas2 |
| Token | MWZkZWQyNTg4OGMxODY1NjMwZWJmNmIyNmRiMDcyZDdlOWUyOTY1ZQ== |
+-------------------+-----------------------------------------------------------------+
[OK] Fetching model from [oss://eas-model-beijing/1295715995194599/h5.tar.gz]
[OK] Fetching processor from [http://eas-data.oss-cn-shanghai.aliyuncs.com/paitensorflow_contrib
_batching_cpu_sdk2_1_12.tar.gz]
[OK] Creating api gateway
[OK] Building image [registry-vpc.cn-beijing.aliyuncs.com/eas/dsw_eas2_cn-beijing:v0.0.1-2019052
3073149]
[OK] Pushing image [registry-vpc.cn-beijing.aliyuncs.com/eas/dsw_eas2_cn-beijing:v0.0.1-20190523
073149]
[OK] Waiting [Total: 1, Pending: 1, Running: 0] beiji[OK] Waiting [Total: 1, Pending: 1, Running: 0]
[OK] Waiting [Total: 1, Pending: 1, Running: 0]
[OK] Waiting [Total: 1, Pending: 1, Running: 0]
[OK] Waiting [Total: 1, Pending: 1, Running: 0]
[OK] Waiting [Total: 1, Pending: 0, Running: 1]
[OK] Running [Total: 1, Pending: 0, Running: 1]
[OK] Service is running现在去查看我们的eas服务,可以看到刚才创建的dsw_eas2模型
4、 API调用该模型
本案例使用的是python2.7调用该模型,建议不要试用python3.x,因为在做签名认证的sdk本平台暂时只提供了2.7版本的。调用的时候是在本地调用的,而不是dsw中。
在调用之前先用python2.7安装个包,执行命令:pip install http://eas-data.oss-cn-shanghai.aliyuncs.com/sdk/pai_tf_predict_proto-1.0-py2.py3-none-any.whl
在本地址python2调用eas的sdk下载对应的sdk,放在项目中。调用的Demo文件内容如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from urlparse import urlparse
from com.aliyun.api.gateway.sdk import client
from com.aliyun.api.gateway.sdk.http import request
from com.aliyun.api.gateway.sdk.common import constant
from pai_tf_predict_proto import tf_predict_pb2
def predict(url, app_key, app_secret, request_data):
cli = client.DefaultClient(app_key=app_key, app_secret=app_secret)
body = request_data
url_ele = urlparse(url)
host = 'http://' + url_ele.hostname
path = url_ele.path
req_post = request.Request(host=host, protocol=constant.HTTP, url=path, method="POST", time_out=6000)
req_post.set_body(body)
req_post.set_content_type(constant.CONTENT_TYPE_STREAM)
stat, header, content = cli.execute(req_post)
return stat, dict(header) if header is not None else {}, content
def demo():
# 以下三行的信息均可在EAS管控台的服务列表,点击服务名称查看
# # 请求数据可以参考阿里云EAS官方文档「通用processor服务请求数据构造」章节,根据自己的模型类型进行请求数据构造并序列化之后再进行请求
app_key = '自己的appkey'
app_secret = '自己的secret'
url = 'http://自己的path'
# data_list数据是“总的感觉前言不搭后语,浪费了银子,呜呜。”在训练时生成的w2dic字典的映射,也是进入模型的数据,可以执行原来代码中的lstm_predict.py就会输出相应的数据
data_list = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 57, 11, 358, 473, 148, 214, 15, 1707, 173, 213, 14, 1634, 1499, 113, 1867, 47, 14, 2383, 2383, 37]
# 请求数据可以参考阿里云EAS官方文档「通用processor服务请求数据构造」章节,根据自己的模型类型进行请求数据构造并序列化之后再进行请求
request = tf_predict_pb2.PredictRequest()
request.signature_name = 'serving_default'
request.inputs['image'].dtype = tf_predict_pb2.DT_FLOAT # 与模型中inputs.type对应 注意:此时的image是和模型转换成savemodel时起的名称一样的
request.inputs['image'].array_shape.dim.extend([1, 150]) # 与模型中inputs.shape对应
request.inputs['image'].float_val.extend(data_list) # data
# 将pb序列化成string进行传输
request_data = request.SerializeToString()
stat, header, content = predict(url, app_key, app_secret, request_data)
if stat != 200:
print 'Http status code: ', stat
print 'Error msg in header: ', header['x-ca-error-message'] if 'x-ca-error-message' in header else ''
print 'Error msg in body: ', content
else:
response = tf_predict_pb2.PredictResponse()
response.ParseFromString(content)
print(response)
if __name__ == '__main__':
demo()
调用结果如下:
outputs {
key: "scores"
value {
dtype: DT_FLOAT
array_shape {
dim: 1
dim: 2
}
float_val: 0.999844312668
float_val: 0.000148816339788
}
}我们的float_val值分别时我们的数据在预测时的情感分布,取下标大的值拿到对应的情感标签(可在训练时目标变量的对应的下标找),此时最大的数值下表为0,对应的因该是negative。
实验总结
本次模型训练的代码是python3,调用的时候是python2造成一定的麻烦,建议写模型时使用python2。模型的写作和调用本人都是放在本地进行的,训练和部署实在pai平台上,训练快捷,部署方便。