一、背景
GTID的原理这篇文章不再展开,有兴趣的同学可以关注之前的GTID原理,GTID实战,GTID运维实战文章。
如果每个实例的GTID相同,那么可以大概率说明数据的一致性。
所以,我们要保证slave的GTID一定是master的子集,因为基于复制原理,slave一般是延后master的。
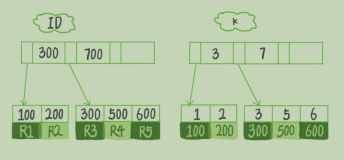
于是,我们就实现了一个监控,如果slave不是master的子集,那么告警出来,截图如下:

上图列出的GTID就是有问题的,不是master的子集。
一开始,这么做主要是处于自己的洁癖,以及对规范的强要求和依赖。
后来有好多小朋友跟我说,这个监控没有任何意义:
1) slave切换下,就不一致了
2) 即便不是子集,在slave进行了操作,比如:flush 等操作,只要不影响数据一致性,也没关系的
balabala好多类似的理由。
当时,我也没有太好的利用说服,只能自己负责的业务默默遵从。
后来再仔细想想GTID的原理,结合实战,对这个监控有了新的认识
二、故障复现和原理剖析
- 先简单说说结论:
如果candidate master的非子集GTID对应的binlog日志被purge了,那么MHA切换的时候,会导致从库IO线程失败。
报错如下:
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log:
'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1,
but the master has purged binary logs containing GTIDs that the slave requires.'
- 故障复现的步骤:
- candidate master: flush slow logs; --产生一些非子集的gtid event
- candidate master: purge binary logs to xx --将刚刚产生的非子集gtid所在的binlog给删除掉
- master : 模拟切换
- 报错产生
- 原理剖析:

a) 当备选master晋升为new master时,其他的实例会获取cm_uuid:1这个gtid
b)如果cm_uuid:1 已经被purge了,那么就会报错 。
- 回到开头,为什么说这个监控价值一个亿呢?
- 如果slave没有业务,其实问题不大。
- 如果slave 有业务呢,现在很多架构是读写分离的,如果不能及时修复主从关系,那么延迟的数据造成的损失就不能简简单单的钱来衡量了。
三、解决方案
- 方案其实很简单: 巡检出问题,修复问题,最终一定要保证slave是master的子集。
- 如果修复gtid呢:如果确定slave上的gtid不影响数据的一致性,那么可以手动reset gtid来修复即可。
四、Q&A
Q1: 通过在slave 设置 read_only 可以避免吧。
A1: 因为flush 命令,是可以绕过read only并产生binlog的。
Q2:假如从库start slave失败,我也可以手动修复吧。
A2:
如果只是切换一次,我相信你可以,如果切换5次,10次呢。
如果只是今天早slave操作了,你姑且可以记住。如果是半年前的操作呢?你怎么确定这个日志是可以skip的?
Q3:从库的binlog怎么会被purge呢?
A3:这个一般互联网公司的binlog日志,在线不会保留太长时间,保留1个月已经算是谢天谢地了。 即便不是人为的purge,也会通过expire_logs来删掉的。
这个原理非常简单,但是 越简单的事情 却 不容易做到。