更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
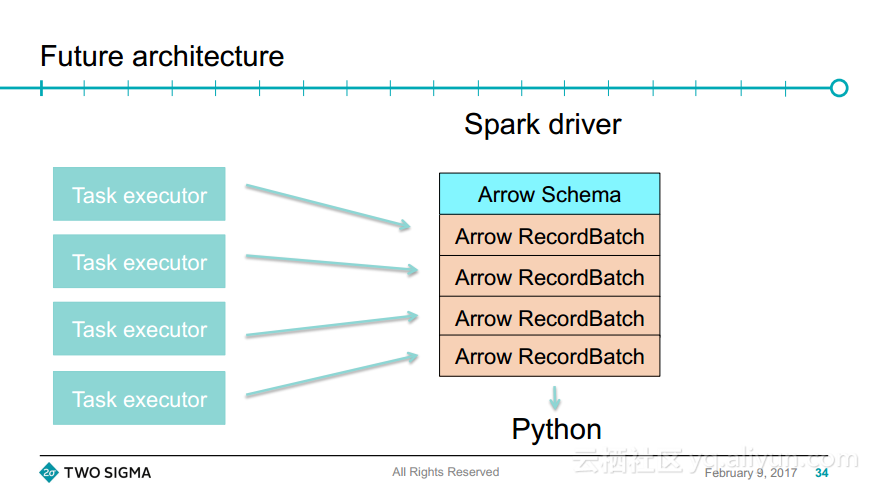
本讲义出自Wes McKinney在Spark Summit East 2017上的演讲,对于使用Python编程以及并行化和扩大数据处理方面,Spark已成为一个受欢迎和成功的框架,但是在很多案例中,使用PySpark的任务处理要比使用Scala编写的效率差,而且在Python环境与Spark主机之间推拉数据也将增加开销,本次演讲将验证和分析使用一些Python库进行序列化以及互操作性问题。