标签
PostgreSQL , 聚集存储 , cluster on index , brin , 轨迹数据 , 范围查询 , 线性相关性 , hbase , json , jsonb , hstore , key-value , text
背景
在现实生活中,人们的各种社会活动,会产生很多的行为数据,比如购物、刷卡、打电话、开房、吃饭、玩游戏、逛网站、聊天 等等。
如果可以把它当成一个虚拟现实(AR)的游戏,我们所有的行为都被记录下来了。
又比如,某些应用软件,在征得你的同意的情况下,可能会记录你的手机行为、你的运动轨迹等等,这些数据可能会不停的上报到业务数据库中,每条记录也许代表某个人的某一次行为。
全球人口非常多,每个人每时每刻都在产生行为数据的话,对于单个人的数据来说,他产生的第一条行为和他产生的第二条行为数据中间可能被其他用户的数据挤进来(如果是堆表存储的话,就意味着这两条数据不在一起,可能相隔好多条记录)。
行为、轨迹数据有啥用?
除了我们常说的群体分析(大数据分析)以外,还涉及到微观查询。
比如最近很火的《三生三世十里桃花》,天族也许会对翼族的首领(比如玄女)进行监控,微观查询他的所有轨迹。

又或者神盾局,对某些人物行为轨迹的明细跟踪和查询

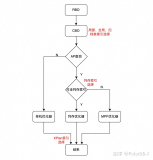
微观查询(行为、轨迹明细)的痛点
为了提升数据的入库速度,通常我们会使用堆表存储,堆表存储的最大特点是写入极其之快,通常一台普通服务器能做到GB/s的写入速度,但是,如果你要频繁根据用户ID查询他产生的轨迹数据的话,会涉及大量的离散IO。查询性能也许就不如写入性能了。
有哪些技术能降低离散IO、提升大范围轨迹数据查询的吞吐?
1. 聚集存储
比如按照用户ID来聚集存储,把每个人的数据按照他个人产生数据的顺序进行聚集存储(指物理介质),那么在根据用户ID进行查询时(比如一次查询出某人在某个时间段的所有行为,假设有1万条记录,那么聚集前也许要扫描10000个数据块,而聚集后也许只需要扫描几十个数据块)。
2. 行列变换
将轨迹数据根据用户ID进行聚合,存入单行,比如某人每天产生1万条轨迹数据,每天的轨迹数据聚合为一条。
聚合为一条后,扫描的数据块可以明显减少,提升按聚集KEY查询的效率。
3. index only scan
将数据按KEY组织为B数,但是B树叶子节点的相邻节点并不一定是物理相邻的,它们实际上是通过链表连接的,所以即使是INDEX ONLY SCAN,也不能保证不产生离散IO,反而基本上都是离散IO。只是扫描的数据块总数变少了。
所以这个场景,index only scan并不是个好主意哦。
对于以上三种方法,任何一种都只能针对固定的KEY进行数据组织,所以,如果你的查询不仅仅局限于用户ID,比如还有店铺ID,商品ID等其他轨迹查询维度,那么一份数据不可避免的也会产生离散IO。
此时,你可以使用存储换时间,即每个查询维度,各冗余一份数据,每份数据选择对应的聚集列(比如三份冗余数据,分别对应聚集列:用户ID、商品ID、店铺ID)。
PostgreSQL 聚集存储
PostgreSQL 的表使用的是堆存储,插入时根据FSM和空间搜索算法寻找合适的数据块,记录插入到哪个数据块是不受控制的。
对于数据追加型的场景,表的数据文件会不断扩大,在文件末尾扩展数据块来扩展存储空间。
FSM算法参考
src/backend/storage/freespace/README
那么如何让PostgreSQL按照指定KEY聚集存储呢,PostgreSQL 提供了一个SQL语法cluster,可以让表按照指定索引的顺序存储。
PS,这种方法是一次性的,并不是实时的。
Command: CLUSTER
Description: cluster a table according to an index
Syntax:
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]
这种方法很适用于行为、轨迹数据,为什么这么说呢?
首先这种数据有时间维度,另一方面这种数据通常有被跟踪对象的唯一标识,例如用户ID,这个标识即后期的查询KEY。
我们可以对这类数据按被跟踪对象的唯一标识HASH后分片,打散到多个数据库或分区表。
同时在每个分区表,再按时间维度进行二级分区,比如按小时分区。
每个小时对前一个小时的数据使用cluster,对堆表按被跟踪对象的唯一标识进行聚集处理。
查询时,按被跟踪对象的唯一标识+时间范围进行检索,扫描的数据块就非常少(除了当前没有聚集处理的数据)。
这种方法即能保证数据插入的高效,也能保证轨迹查询的高效。
PostgreSQL BRIN 聚集数据 块级索引
我们通常所认知的除了BTREE,HASH索引,还有一种块级索引BRIN,是针对聚集数据(流式数据、值与物理存储线性相关)的一种轻量级索引。
比如每连续的128个数据块,计算它们的统计信息(边界值、最大、最小值、COUNT、SUM、NULL值个数等)。
这种索引非常小,查询性能也非常高。
有几篇文档介绍BRIN
《PostgreSQL 物联网黑科技 - 瘦身几百倍的索引(BRIN index)》
《PostgreSQL 9.5 new feature - BRIN (block range index) index》
PostgreSQL 行列变换
除了聚集存储,还有一种提升轨迹查询效率的方法。行列变换。
比如每个被跟踪对象,一天产生1万条记录,将这1万条数据聚合为一条。查询时效率也非常高。
但是问题来了,这种方法不适合除了时间条件以外,还有其他查询条件的场景。譬如某个用户某个时间段内,在某个场所(这个是新增条件)的消费记录。
这显然需要一个新的索引来降低数据扫描。
排除这个需求,如果你只有被跟踪ID+时间 两个维度的查询需求,那么使用行列变换不失为一种好方法。
如何实施行列变换
PostgreSQL支持多种数据类型,包括 表类型,复合类型,数组、hstore、JSON。
表类型 - 在创建表时,自动被创建,指与表结构一致的数据类型。
复合类型 - 用户可以根据需要自己定义,比如定义一个复数类型 create type cmp as (c1 float8, c2 float8);
数组 - 基于基本类型的一维或者多维数组,表类型也支持数组,可用于行列变换,将多条记录存储为一个数组。
hstore - key-value类型,可以有多个KV组。
json - 无需多言。
行列变换后,我们留几个字段:
被跟踪ID,时间段(时间范围类型tsrange),合并字段(表数组、HSTORE、JSON都可以)
聚集、行列变换 测试
同一份数据,测试离散、聚集、行列变换后的性能。
堆表 - 离散存储
1. 构造1万个ID,每个ID一万条记录,总共1亿记录,全离散存储。
create unlogged table test(id int, info text, crt_time timestamp);
insert into test select generate_series(1,10000), md5(id::text), clock_timestamp() from generate_series(1,10000) t(id);
postgres=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+--------------------+-------+----------+---------+-------------
public | test | table | postgres | 7303 MB |
2. 创建btree索引
set maintenance_work_mem ='32GB';
create index idx_test_id on test using btree (id);
postgres=# \di+
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+------------------+-------+----------+--------------------+---------+-------------
public | idx_test_id | index | postgres | test | 2142 MB |
3. 通过查询物理行号、记录,确认离散度
select ctid,* from test where id=1;
postgres=# select ctid,* from test where id=1;
ctid | id | info | crt_time
--------------+----+----------------------------------+----------------------------
(0,1) | 1 | c4ca4238a0b923820dcc509a6f75849b | 2017-02-19 21:26:49.270193
(93,50) | 1 | c81e728d9d4c2f636f067f89cc14862c | 2017-02-19 21:26:49.301129
(186,99) | 1 | eccbc87e4b5ce2fe28308fd9f2a7baf3 | 2017-02-19 21:26:49.330993
(280,41) | 1 | a87ff679a2f3e71d9181a67b7542122c | 2017-02-19 21:26:49.360924
(373,90) | 1 | e4da3b7fbbce2345d7772b0674a318d5 | 2017-02-19 21:26:49.390941
... ...
postgres=# select ctid,* from test where id=10000;
ctid | id | info | crt_time
--------------+-------+----------------------------------+----------------------------
(93,49) | 10000 | c4ca4238a0b923820dcc509a6f75849b | 2017-02-19 21:26:49.301121
(186,98) | 10000 | c81e728d9d4c2f636f067f89cc14862c | 2017-02-19 21:26:49.330985
(280,40) | 10000 | eccbc87e4b5ce2fe28308fd9f2a7baf3 | 2017-02-19 21:26:49.360917
(373,89) | 10000 | a87ff679a2f3e71d9181a67b7542122c | 2017-02-19 21:26:49.390933
4. 轨迹查询执行计划,使用最优查询计划
postgres=# explain (analyze,verbose,timing,costs,buffers) select * from test where id=1; -- 优化器选择bitmapscan , 减少离散扫描。但是引入了ctid SORT。
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on public.test (cost=111.74..12629.49 rows=9816 width=45) (actual time=6.682..28.631 rows=10000 loops=1)
Output: id, info, crt_time
Recheck Cond: (test.id = 1)
Heap Blocks: exact=10000
Buffers: shared hit=10031
-> Bitmap Index Scan on idx_test_id (cost=0.00..109.29 rows=9816 width=0) (actual time=4.074..4.074 rows=10000 loops=1)
Index Cond: (test.id = 1)
Buffers: shared hit=31
Planning time: 0.119 ms
Execution time: 29.767 ms
(10 rows)
postgres=# set enable_bitmapscan =off;
SET
postgres=# explain (analyze,verbose,timing,costs,buffers) select * from test where id=1; -- 本例使用index scan更合适
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------
Index Scan using idx_test_id on public.test (cost=0.57..12901.82 rows=9816 width=45) (actual time=0.054..18.771 rows=10000 loops=1)
Output: id, info, crt_time
Index Cond: (test.id = 1)
Buffers: shared hit=10031
Planning time: 0.116 ms
Execution time: 19.674 ms
(6 rows)
5. 测试查询性能qps、吞吐
postgres=# alter role postgres set enable_bitmapscan = off;
ALTER ROLE
$ vi test.sql
\set id random(1,10000)
select * from test where id=:id;
$ pgbench -M prepared -n -r -P 1 -f ./test.sql -c 64 -j 64 -T 100000
... ...
progress: 181.0 s, 1156.0 tps, lat 55.612 ms stddev 9.957
progress: 182.0 s, 1157.9 tps, lat 55.365 ms stddev 9.855
progress: 183.0 s, 1160.1 tps, lat 55.057 ms stddev 8.635
progress: 184.0 s, 1147.0 tps, lat 55.596 ms stddev 9.151
progress: 185.0 s, 1162.0 tps, lat 55.287 ms stddev 8.545
progress: 186.0 s, 1156.0 tps, lat 55.463 ms stddev 9.733
progress: 187.0 s, 1154.0 tps, lat 55.568 ms stddev 9.753
progress: 188.0 s, 1161.0 tps, lat 55.240 ms stddev 9.108
... ...
1150其实已经很高,输出的吞吐达到了1150万行/s。
6. TOP
top - 21:43:59 up 93 days, 8:01, 3 users, load average: 64.94, 26.52, 11.48
Tasks: 2367 total, 68 running, 2299 sleeping, 0 stopped, 0 zombie
Cpu(s): 92.3%us, 6.7%sy, 0.0%ni, 0.1%id, 0.0%wa, 0.0%hi, 0.9%si, 0.0%st
Mem: 529321828k total, 241868480k used, 287453348k free, 2745652k buffers
Swap: 0k total, 0k used, 0k free, 212241588k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9908 digoal 20 0 4677m 42m 1080 S 713.5 0.0 14:09.44 pgbench -M prepared -n -r -P 1 -f ./test.sql -c 64 -j 64 -T 100000
10005 digoal 20 0 41.9g 8.0g 8.0g R 88.0 1.6 1:40.42 postgres: postgres postgres 127.0.0.1(51375) SELECT
10006 digoal 20 0 41.9g 8.0g 8.0g R 88.0 1.6 1:40.94 postgres: postgres postgres 127.0.0.1(51376) SELECT
... ...
堆表 - 聚集存储
使用 cluster test using (idx_test_id); 即可将test表转换为以ID字段聚集存储。但是为了测试方便,我还是新建了2张聚集表。
聚集存储 BTREE 索引
1. 同一份数据,按照ID聚集存储,并创建btree索引。
create unlogged table cluster_test_btree (like test);
insert into cluster_test_btree select * from test order by id;
set maintenance_work_mem ='32GB';
create index idx_cluster_test_btree_id on cluster_test_btree using btree (id);
2. 索引大小、轨迹查询执行计划、查询效率
postgres=# \di+ idx_cluster_test_btree_id
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+---------------------------+-------+----------+--------------------+---------+-------------
public | idx_cluster_test_btree_id | index | postgres | cluster_test_btree | 2142 MB |
(1 row)
postgres=# explain (analyze,verbose,timing,costs,buffers) select * from cluster_test_btree where id=1;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------
Index Scan using idx_cluster_test_btree_id on public.cluster_test_btree (cost=0.57..328.54 rows=10724 width=45) (actual time=0.054..4.259 rows=10000 loops=1)
Output: id, info, crt_time
Index Cond: (cluster_test_btree.id = 1)
Buffers: shared hit=125
Planning time: 0.118 ms
Execution time: 5.147 ms
(6 rows)
3. 通过查询物理行号、记录,确认已按ID聚集存储
postgres=# select ctid,* from cluster_test_btree where id=1 limit 10;
ctid | id | info | crt_time
--------+----+----------------------------------+----------------------------
(0,1) | 1 | 5f5c19fa671886b5f7f205d541157c1f | 2017-02-19 21:55:07.095403
(0,2) | 1 | d69bc0b1aeafcc63c7d99509a65e0492 | 2017-02-19 21:55:07.157631
(0,3) | 1 | 9f5506939986201d55a4353ff8b4028e | 2017-02-19 21:55:07.188382
(0,4) | 1 | 81930c54e08b6d26d9638dd2e4656dc1 | 2017-02-19 21:55:07.126702
(0,5) | 1 | d4fcc05bd8205c41fbe4f2645bf0c6b8 | 2017-02-19 21:55:07.219671
(0,6) | 1 | 4fc8ed929e539525e3590f1607718f97 | 2017-02-19 21:55:07.281092
(0,7) | 1 | 69b4fa3be19bdf400df34e41b93636a4 | 2017-02-19 21:55:07.250614
(0,8) | 1 | 0602940f23884f782058efac46f64b0f | 2017-02-19 21:55:07.467121
(0,9) | 1 | 812649f8ed0e2e1d911298ec67ed9e61 | 2017-02-19 21:55:07.498825
(0,10) | 1 | 966bc24f56ab8397ab2303e8e4cdb4c7 | 2017-02-19 21:55:07.436237
(10 rows)
postgres=# select ctid,* from cluster_test_btree where id=2 limit 10;
ctid | id | info | crt_time
---------+----+----------------------------------+----------------------------
(93,50) | 2 | 05d8cccb5f47e5072f0a05b5f514941a | 2017-02-19 21:55:07.033735
(93,51) | 2 | a5329a91ef79db75900bd9cab3d96e43 | 2017-02-19 21:55:07.003142
(93,52) | 2 | 1299c1b7a9e0c2bf41af69c449464a49 | 2017-02-19 21:55:06.971847
(93,53) | 2 | 1b932eaf9f7c0cb84f471a560097ddb8 | 2017-02-19 21:55:07.064405
(93,54) | 2 | 9e740b84bb48a64dde25061566299467 | 2017-02-19 21:51:43.819157
(93,55) | 2 | 9e406957d45fcb6c6f38c2ada7bace91 | 2017-02-19 21:51:43.878693
(93,56) | 2 | 532b81fa223a1b1ec74139a5b8151d12 | 2017-02-19 21:51:43.848905
(93,57) | 2 | 45cef8e5b9570959bd9feaacae2bf38d | 2017-02-19 21:51:41.754017
(93,58) | 2 | e1021d43911ca2c1845910d84f40aeae | 2017-02-19 21:51:41.813908
(93,59) | 2 | 2da6cc4a5d3a7ee43c1b3af99267ed17 | 2017-02-19 21:51:41.843867
(10 rows)
4. 测试查询性能qps、吞吐
$ vi test.sql
\set id random(1,10000)
select * from cluster_test_btree where id=:id;
$ pgbench -M prepared -n -r -P 1 -f ./test.sql -c 64 -j 64 -T 100000
... ...
progress: 127.0 s, 1838.1 tps, lat 34.972 ms stddev 7.326
progress: 128.0 s, 1849.0 tps, lat 34.539 ms stddev 6.933
progress: 129.0 s, 1854.9 tps, lat 34.441 ms stddev 6.694
progress: 130.0 s, 1839.1 tps, lat 34.768 ms stddev 6.888
progress: 131.0 s, 1838.0 tps, lat 34.773 ms stddev 6.710
progress: 132.0 s, 1848.0 tps, lat 34.729 ms stddev 6.647
progress: 133.0 s, 1866.0 tps, lat 34.404 ms stddev 5.923
... ...
5. TOP
top - 22:11:30 up 93 days, 8:29, 3 users, load average: 69.59, 34.15, 18.39
Tasks: 2366 total, 67 running, 2299 sleeping, 0 stopped, 0 zombie
Cpu(s): 91.9%us, 7.8%sy, 0.0%ni, 0.2%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 529321828k total, 233261056k used, 296060772k free, 2756952k buffers
Swap: 0k total, 0k used, 0k free, 204198120k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
27720 digoal 20 0 4677m 46m 1056 S 1082.7 0.0 18:23.07 pgbench -M prepared -n -r -P 1 -f ./test.sql -c 64 -j 64 -T 100000
27735 digoal 20 0 41.9g 2.6g 2.6g R 82.5 0.5 1:16.90 postgres: postgres postgres [local] SELECT
27795 digoal 20 0 41.9g 2.8g 2.8g R 82.2 0.6 1:21.54 postgres: postgres postgres [local] SELECT
聚集存储 BRIN 索引
1. 同一份数据,按照ID聚集存储,并创建brin索引。
create unlogged table cluster_test_brin (like test);
insert into cluster_test_brin select * from test order by id;
set maintenance_work_mem ='32GB';
create index idx_cluster_test_brin_id on cluster_test_brin using brin (id) with (pages_per_range=128); -- 可以自行调整,本例1万条记录约占据83个数据块,128还是比较合适的值。
alter role postgres reset enable_bitmapscan ;
2. 索引大小、轨迹查询执行计划、查询效率
postgres=# \di+ idx_cluster_test_brin_id
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+--------------------------+-------+----------+-------------------+--------+-------------
public | idx_cluster_test_brin_id | index | postgres | cluster_test_brin | 232 kB |
(1 row)
postgres=# explain (analyze,verbose,timing,costs,buffers) select * from cluster_test_brin where id=1;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on public.cluster_test_brin (cost=115.61..13769.87 rows=10724 width=45) (actual time=7.467..11.458 rows=10000 loops=1)
Output: id, info, crt_time
Recheck Cond: (cluster_test_brin.id = 1)
Rows Removed by Index Recheck: 3696
Heap Blocks: lossy=128
Buffers: shared hit=159
-> Bitmap Index Scan on idx_cluster_test_brin_id (cost=0.00..112.93 rows=10724 width=0) (actual time=7.446..7.446 rows=1280 loops=1)
Index Cond: (cluster_test_brin.id = 1)
Buffers: shared hit=31
Planning time: 0.111 ms
Execution time: 12.361 ms
(11 rows)
bitmapscan 隐含了ctid sort,所以启动时间就耗费了7.4毫秒。
如果brin未来支持index scan,而非bitmapscan,可以压缩这部分时间,批量查询效率达到和精确索引btree不相上下。
扫描的数据块数量比非聚集存储少了很多。
3. 通过查询物理行号、记录,确认已按ID聚集存储
postgres=# select ctid,* from cluster_test_brin where id=1 limit 10;
ctid | id | info | crt_time
--------+----+----------------------------------+----------------------------
(0,1) | 1 | 5f5c19fa671886b5f7f205d541157c1f | 2017-02-19 21:55:07.095403
(0,2) | 1 | d69bc0b1aeafcc63c7d99509a65e0492 | 2017-02-19 21:55:07.157631
(0,3) | 1 | 9f5506939986201d55a4353ff8b4028e | 2017-02-19 21:55:07.188382
(0,4) | 1 | 81930c54e08b6d26d9638dd2e4656dc1 | 2017-02-19 21:55:07.126702
(0,5) | 1 | d4fcc05bd8205c41fbe4f2645bf0c6b8 | 2017-02-19 21:55:07.219671
(0,6) | 1 | 4fc8ed929e539525e3590f1607718f97 | 2017-02-19 21:55:07.281092
(0,7) | 1 | 69b4fa3be19bdf400df34e41b93636a4 | 2017-02-19 21:55:07.250614
(0,8) | 1 | 0602940f23884f782058efac46f64b0f | 2017-02-19 21:55:07.467121
(0,9) | 1 | 812649f8ed0e2e1d911298ec67ed9e61 | 2017-02-19 21:55:07.498825
(0,10) | 1 | 966bc24f56ab8397ab2303e8e4cdb4c7 | 2017-02-19 21:55:07.436237
(10 rows)
postgres=# select ctid,* from cluster_test_brin where id=2 limit 10;
ctid | id | info | crt_time
---------+----+----------------------------------+----------------------------
(93,50) | 2 | 05d8cccb5f47e5072f0a05b5f514941a | 2017-02-19 21:55:07.033735
(93,51) | 2 | a5329a91ef79db75900bd9cab3d96e43 | 2017-02-19 21:55:07.003142
(93,52) | 2 | 1299c1b7a9e0c2bf41af69c449464a49 | 2017-02-19 21:55:06.971847
(93,53) | 2 | 1b932eaf9f7c0cb84f471a560097ddb8 | 2017-02-19 21:55:07.064405
(93,54) | 2 | 9e740b84bb48a64dde25061566299467 | 2017-02-19 21:51:43.819157
(93,55) | 2 | 9e406957d45fcb6c6f38c2ada7bace91 | 2017-02-19 21:51:43.878693
(93,56) | 2 | 532b81fa223a1b1ec74139a5b8151d12 | 2017-02-19 21:51:43.848905
(93,57) | 2 | 45cef8e5b9570959bd9feaacae2bf38d | 2017-02-19 21:51:41.754017
(93,58) | 2 | e1021d43911ca2c1845910d84f40aeae | 2017-02-19 21:51:41.813908
(93,59) | 2 | 2da6cc4a5d3a7ee43c1b3af99267ed17 | 2017-02-19 21:51:41.843867
(10 rows)
4. 测试查询性能qps、吞吐
$ vi test.sql
\set id random(1,10000)
select * from cluster_test_brin where id=:id;
$ pgbench -M prepared -n -r -P 1 -f ./test.sql -c 64 -j 64 -T 100000
... ...
progress: 198.0 s, 1161.0 tps, lat 55.246 ms stddev 10.578
progress: 199.0 s, 1158.0 tps, lat 55.201 ms stddev 10.542
progress: 200.0 s, 1160.0 tps, lat 55.294 ms stddev 9.898
progress: 201.0 s, 1133.0 tps, lat 56.063 ms stddev 9.988
progress: 202.0 s, 1149.0 tps, lat 55.974 ms stddev 10.166
progress: 203.0 s, 1156.0 tps, lat 55.076 ms stddev 9.668
progress: 204.0 s, 1145.0 tps, lat 56.078 ms stddev 11.279
... ...
5. TOP
top - 22:22:28 up 93 days, 8:40, 2 users, load average: 67.27, 34.03, 22.74
Tasks: 2362 total, 69 running, 2293 sleeping, 0 stopped, 0 zombie
Cpu(s): 94.3%us, 5.6%sy, 0.0%ni, 0.1%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 529321828k total, 240541544k used, 288780284k free, 2759436k buffers
Swap: 0k total, 0k used, 0k free, 211679508k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
34823 digoal 20 0 4678m 28m 1060 S 672.2 0.0 14:29.74 pgbench -M prepared -n -r -P 1 -f ./test.sql -c 64 -j 64 -T 100000
34861 digoal 20 0 41.9g 3.3g 3.3g R 89.5 0.6 1:53.75 postgres: postgres postgres [local] SELECT
34866 digoal 20 0 41.9g 3.2g 3.2g R 89.5 0.6 1:50.73 postgres: postgres postgres [local] SELECT
堆表 - 行列变换 (array, jsonb)
1. 同一份数据,按照ID聚合为单行数组的存储。
其他还可以选择jsonb , hstore。
create unlogged table array_row_test (id int, ar test[]);
set work_mem ='32GB';
set maintenance_work_mem ='32GB';
insert into array_row_test select id,array_agg(test) from test group by id;
create index idx_array_row_test_id on array_row_test using btree (id) ;
2. 索引大小、轨迹查询执行计划、查询效率
postgres=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+--------------------+-------+----------+---------+-------------
public | array_row_test | table | postgres | 4543 MB |
public | cluster_test_brin | table | postgres | 7303 MB |
public | cluster_test_btree | table | postgres | 7303 MB |
public | test | table | postgres | 7303 MB |
postgres=# \di+ idx_array_row_test_id
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+-----------------------+-------+----------+----------------+--------+-------------
public | idx_array_row_test_id | index | postgres | array_row_test | 248 kB |
(1 row)
postgres=# explain (analyze,verbose,timing,costs,buffers) select * from array_row_test where id=1;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------
Index Scan using idx_array_row_test_id on public.array_row_test (cost=0.29..2.90 rows=1 width=22) (actual time=0.030..0.031 rows=1 loops=1)
Output: id, ar
Index Cond: (array_row_test.id = 1)
Buffers: shared hit=1 read=2
Planning time: 0.205 ms
Execution time: 0.063 ms
(6 rows)
3. 行列变换后的数据举例
postgres=# select ctid,* from array_row_test where id=1;
....
(40,66) | 1 | {"(1,c4ca4238a0b923820dcc509a6f75849b,\"2017-02-19 21:49:50.69805\")","(1,c81e728d9d4c2f636f067f89cc14862c,\"2017-02-19 21:49:50.728135\")","(1,eccbc87e4b5ce2fe28308fd9f2a7baf3,\"2017-02-19 21:49:50.7581\")","(1,a87ff679a
2f3e71d9181a67b7542122c,\"2017-02-19 21:49:50.787969\")",.....
postgres=# select id, (ar[1]).id, (ar[1]).info, (ar[1]).crt_time from array_row_test where id=1;
id | id | info | crt_time
----+----+----------------------------------+---------------------------
1 | 1 | c4ca4238a0b923820dcc509a6f75849b | 2017-02-19 21:49:50.69805
(1 row)
4. 测试查询性能qps、吞吐
$ vi test.sql
\set id random(1,10000)
select * from array_row_test where id=:id;
$ pgbench -M prepared -n -r -P 1 -f ./test.sql -c 64 -j 64 -T 100000
... ...
progress: 133.0 s, 668.0 tps, lat 96.340 ms stddev 17.262
progress: 134.0 s, 667.0 tps, lat 97.162 ms stddev 18.090
progress: 135.0 s, 660.7 tps, lat 97.272 ms stddev 18.852
progress: 136.0 s, 670.3 tps, lat 95.921 ms stddev 18.195
progress: 137.0 s, 646.0 tps, lat 96.839 ms stddev 18.015
progress: 138.0 s, 655.0 tps, lat 97.890 ms stddev 17.992
progress: 139.0 s, 667.0 tps, lat 96.570 ms stddev 21.196
... ...
5. TOP
top - 23:05:05 up 93 days, 9:23, 3 users, load average: 28.26, 10.03, 9.97
Tasks: 2365 total, 69 running, 2296 sleeping, 0 stopped, 0 zombie
Cpu(s): 58.7%us, 40.9%sy, 0.0%ni, 0.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 529321828k total, 278064448k used, 251257380k free, 2774244k buffers
Swap: 0k total, 0k used, 0k free, 249425004k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1234 digoal 20 0 4742m 57m 1060 S 108.2 0.0 0:30.89 pgbench -M prepared -n -r -P 1 -f ./test.sql -c 64 -j 64 -T 100000
1361 digoal 20 0 41.9g 236m 230m R 100.0 0.0 0:28.01 postgres: postgres postgres [local] SELECT
1270 digoal 20 0 41.9g 233m 230m R 99.3 0.0 0:28.02 postgres: postgres postgres [local] SELECT
TOP可以看出,test 表 array 存储的效率并不高,你也许可以尝试一下JSON或者hstore,可能更好。
perf top -ag
samples pcnt function DSO
_______ _____ _______________________________ ___________________________________
107022.00 21.0% _spin_lock [kernel.kallsyms]
67193.00 13.2% array_out /home/digoal/pgsql10/bin/postgres
55955.00 11.0% record_out /home/digoal/pgsql10/bin/postgres
21401.00 4.2% pglz_decompress /home/digoal/pgsql10/bin/postgres
19150.00 3.8% clear_page_c_e [kernel.kallsyms]
16093.00 3.2% AllocSetCheck /home/digoal/pgsql10/bin/postgres
15998.00 3.1% __memset_sse2 /lib64/libc-2.12.so
14778.00 2.9% array_isspace /home/digoal/pgsql10/bin/postgres
10105.00 2.0% AllocSetAlloc /home/digoal/pgsql10/bin/postgres
试试jsonb
postgres=# create unlogged table jsonb_row_test (id int, jb jsonb);
CREATE TABLE
postgres=# set work_mem ='32GB';
SET
postgres=# set maintenance_work_mem ='32GB';
SET
postgres=# insert into jsonb_row_test select id,jsonb_agg(test) from test group by id;
create index idx_jsonb_row_test_id on jsonb_row_test using btree (id) ;
public | array_row_test | table | postgres | 4543 MB |
public | cluster_test_brin | table | postgres | 7303 MB |
public | cluster_test_btree | table | postgres | 7303 MB |
public | jsonb_row_test | table | postgres | 4582 MB |
public | idx_jsonb_row_test_id | index | postgres | jsonb_row_test | 248 kB |
$ vi test.sql
\set id random(1,10000)
select * from jsonb_row_test where id=:id;
$ pgbench -M prepared -n -r -P 1 -f ./test.sql -c 64 -j 64 -T 100000
... ...
progress: 70.0 s, 1263.0 tps, lat 50.403 ms stddev 8.996
progress: 71.0 s, 1243.9 tps, lat 51.317 ms stddev 8.989
progress: 72.0 s, 1287.2 tps, lat 49.906 ms stddev 9.093
progress: 73.0 s, 1267.0 tps, lat 50.506 ms stddev 9.212
progress: 74.0 s, 1227.0 tps, lat 52.532 ms stddev 9.383
progress: 75.0 s, 1248.0 tps, lat 50.941 ms stddev 9.405
progress: 76.0 s, 1303.1 tps, lat 49.079 ms stddev 7.944
progress: 77.0 s, 1265.9 tps, lat 50.837 ms stddev 9.926
progress: 78.0 s, 1304.0 tps, lat 48.952 ms stddev 8.413
progress: 79.0 s, 1317.1 tps, lat 48.582 ms stddev 7.886
... ...
TOP
... ...
top - 23:36:51 up 93 days, 9:54, 3 users, load average: 24.53, 8.29, 7.87
Tasks: 2367 total, 68 running, 2298 sleeping, 1 stopped, 0 zombie
Cpu(s): 72.5%us, 27.3%sy, 0.0%ni, 0.1%id, 0.1%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 529321828k total, 282957188k used, 246364640k free, 2783884k buffers
Swap: 0k total, 0k used, 0k free, 254291420k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
22333 digoal 20 0 4742m 74m 1060 S 288.2 0.0 1:15.78 pgbench -M prepared -n -r -P 1 -f ./test.sql -c 64 -j 64 -T 100000
22461 digoal 20 0 41.9g 397m 393m R 96.1 0.1 0:25.33 postgres: postgres postgres [local] SELECT
22413 digoal 20 0 41.9g 391m 388m R 95.4 0.1 0:25.32 postgres: postgres postgres [local] SELECT
... ...
perf
samples pcnt function DSO
_______ _____ _______________________________ ___________________________________
141697.00 20.9% escape_json /home/digoal/pgsql10/bin/postgres
81266.00 12.0% pglz_decompress /home/digoal/pgsql10/bin/postgres
33469.00 4.9% _spin_lock_irqsave [kernel.kallsyms]
31359.00 4.6% JsonbIteratorNext /home/digoal/pgsql10/bin/postgres
26631.00 3.9% AllocSetAlloc /home/digoal/pgsql10/bin/postgres
25430.00 3.8% _spin_lock_irq [kernel.kallsyms]
24923.00 3.7% memcpy /lib64/libc-2.12.so
20437.00 3.0% clear_page_c_e [kernel.kallsyms]
15921.00 2.3% appendBinaryStringInfo /home/digoal/pgsql10/bin/postgres
性能比拼图
| 存储格式 | 按KEY查询轨迹 TPS | 输出吞吐 | CPU利用率 | 索引大小 | 表大小 |
|---|---|---|---|---|---|
| 离散存储 | 1155 | 1155 万行/s | 99.8% | 2.1 GB | 7.3 GB |
| 聚集存储 BTREE索引 | 1840 | 1840 万行/s | 99.8% | 2.1 GB | 7.3 GB |
| 聚集存储 BRIN索引 | 1155 | 1155 万行/s | 99.8% | 232 KB | 7.3 GB |
| 行列变换 array | 660 | 660 行/s | 99.8% | 248 KB | 4.5 GB |
| 行列变换 jsonb | 1255 | 1255 行/s | 99.8% | 248 KB | 4.5 GB |
聚集存储后的好处
聚集存储后,我们看到,按聚集列搜索数据时,需要扫描的数据块更少了,查询效率明显提升。
对于聚集列,不需要创建BTREE精确索引,使用BRIN索引就可以满足高性能的查询需求。节约了大量的空间,同时提升了数据的写入效率。
聚集存储还可以解决另一个问题,比如潜在的宽表需求(例如超过1万个列的宽表,通过多行来表示,甚至每行的数据结构都可以不一样,例如通过某个字段作为行头,来表示行的数据结构)。
PostgreSQL 内核级聚集存储
在内核层面实现聚集存储,而不是通过cluster来实现。
数据插入就不能随便找个有足够剩余空间的PAGE了,需要根据插入的聚集列的值,找到对应的PAGE进行插入。
所以它可能依赖一颗以被跟踪对象ID为KEY的B树,修改对应的fsm算法,在插入时,找到对应ID的PAGE。
不过随着数据的不断写入,很难保证单个ID的所有值都在连续的物理空间中。总会有碎片存在的。
还有一点,如果采样预分配的方式,一些不活跃的ID,可能会浪费一些最小单元的空间(比如最小单元是1PAGE)。
小结
按KEY聚集存储解决了按KEY查询大量数据的IO放大(由于离散存储)问题,例如轨迹查询,微观查询。
对于PostgreSQL用户来说,目前,你可以选择行列变换,或者异步聚集存储的方式来达到同样的目的。
行列变换,你可以使用表级数组,或者JSONB来存储聚集后的记录,从效率来看JSONB更高,而值得优化的有两处代码pglz_decompress, escape_json。
对于异步聚集,你可以选择聚集KEY,分区KEY(通常是时间)。异步的将上一个时间段的分区,按KEY进行聚合。
PostgreSQL 聚集表的聚集KEY,你可以选择BRIN索引,在几乎不失查询效率的同时,解决大量的存储空间。
不管使用哪种方式,一张表只能使用一种聚集KEY(s),如果有多个聚集维度的查询需求,为了达到最高的查询效率,你可存储多份冗余数据,每份冗余数据采用不同的聚集KEY。
将来,PostgreSQL可能会在内核层面直接实现聚集存储的选项。你也许只需要输入聚集KEY,最小存储粒度、等参数,就可以将表创建为聚集表。
将来,PostgreSQL brin索引可能会支持index scan,而不是目前仅有的bitmap scan。
参考
《PostgreSQL 物联网黑科技 - 瘦身几百倍的索引(BRIN index)》
《PostgreSQL 9.5 new feature - BRIN (block range index) index》