更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
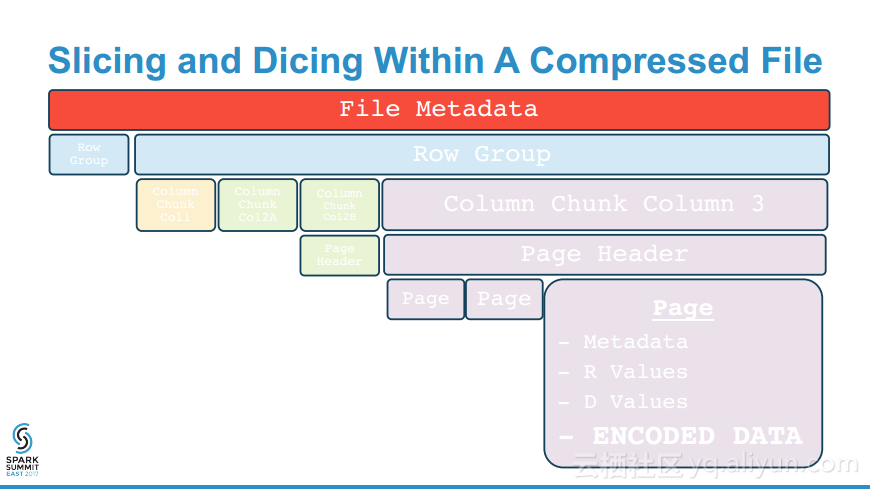
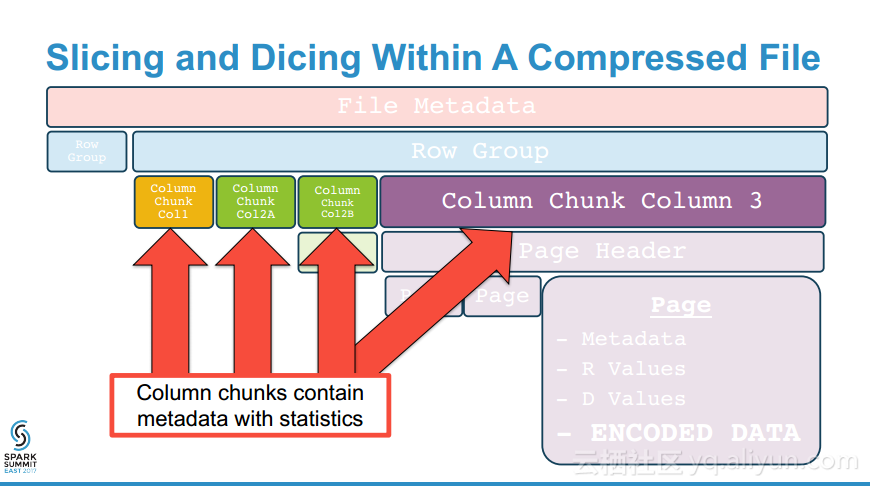
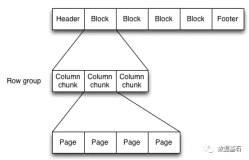
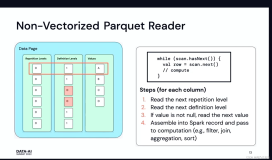
本讲义出自Emily Curtin and Robbie Strickland在Spark Summit East 2017上的演讲,主要介绍了使用Spark + Parquet构建的非常之快、存储高效、查询也高效的数据湖以及与之相匹配的一系列工具。演讲分享了Parquet是如何工作的以及如何从Tungsten得改进并使得SparkSQL可以利用这样的设计克服分布式分析中的两大瓶颈:通信成本和数据解码,并提供快速查询的。