更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
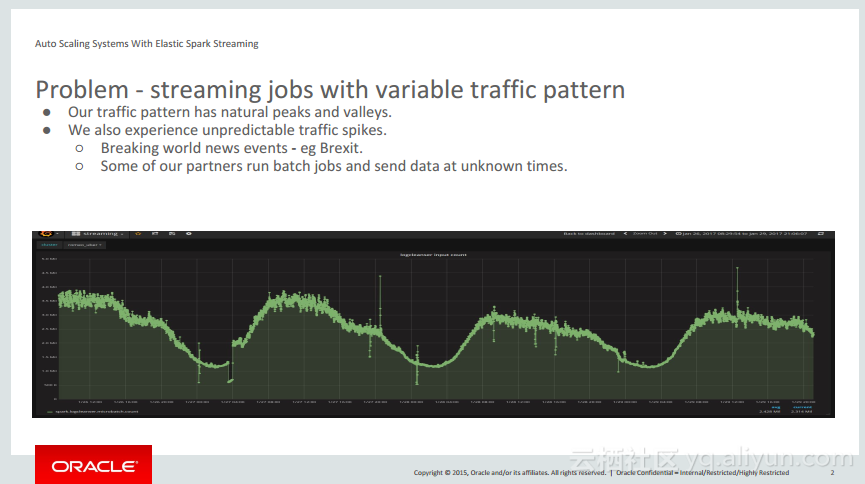
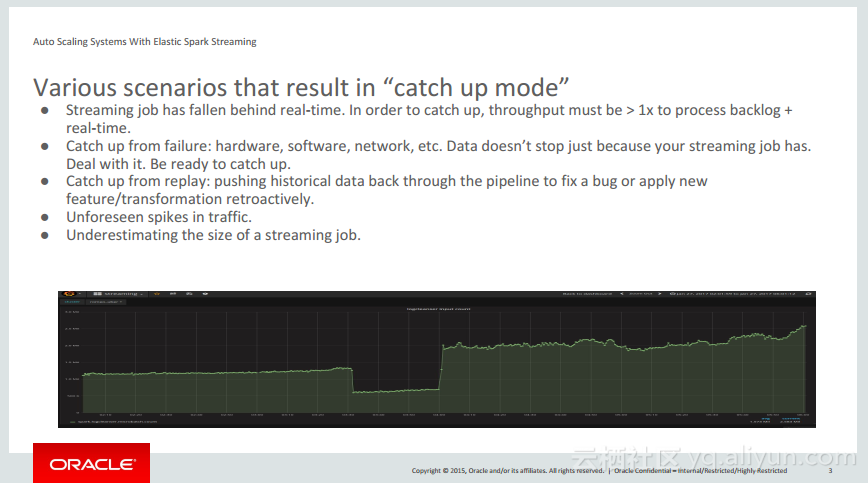
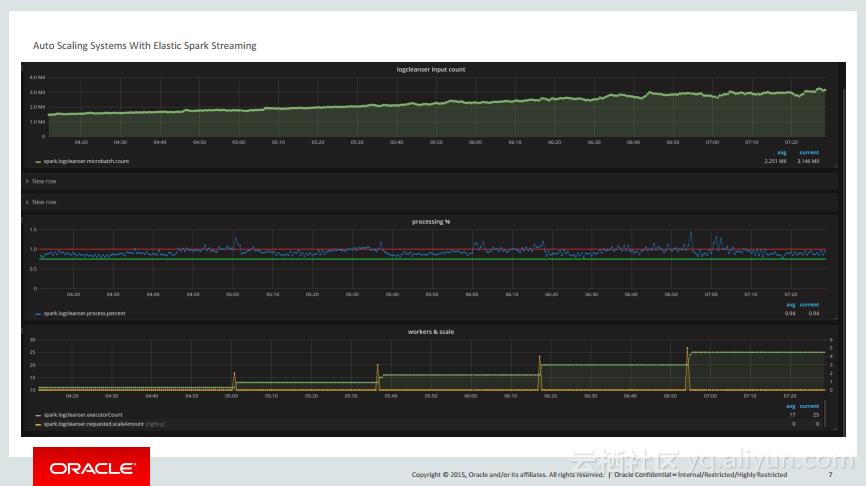
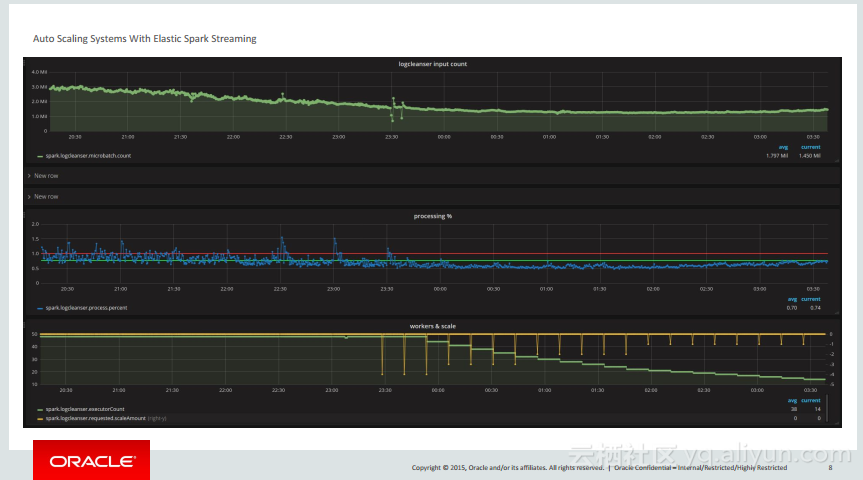
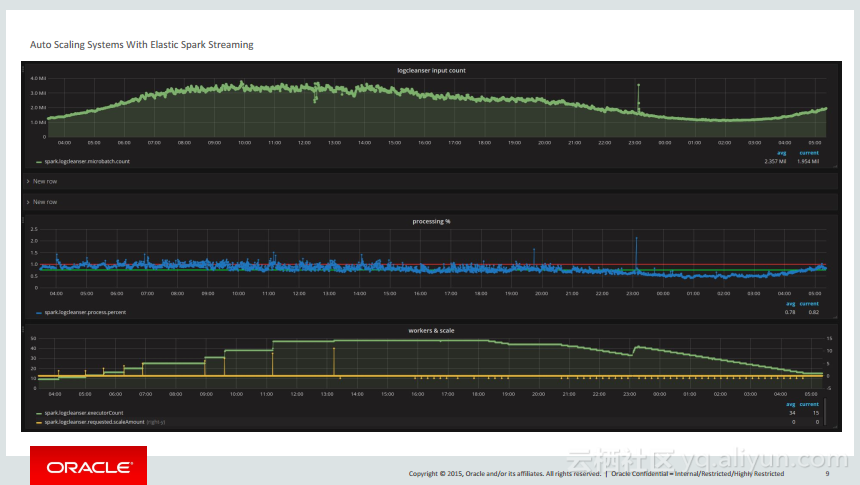
本讲义出自PhuDuc Nguyen在Spark Summit East 2017上的演讲,主要介绍了不支持开箱即用的在不中断实时Spark Streaming任务的同时能够添加或删除节点的功能。并介绍了Elastic Spark Streaming任务能够自动调整对于数据流的体积和流量的需求。