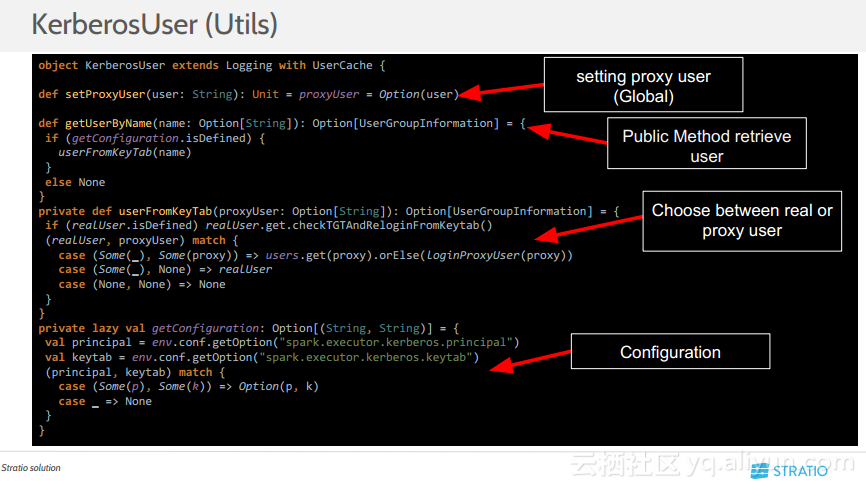
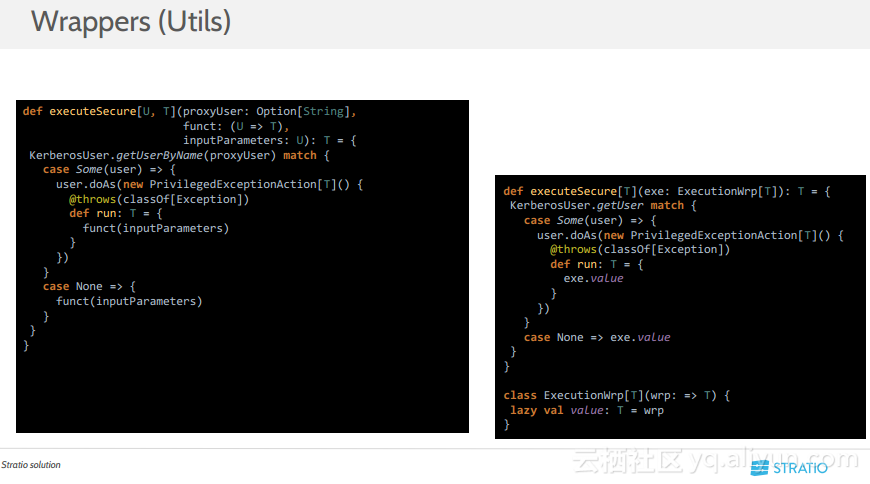
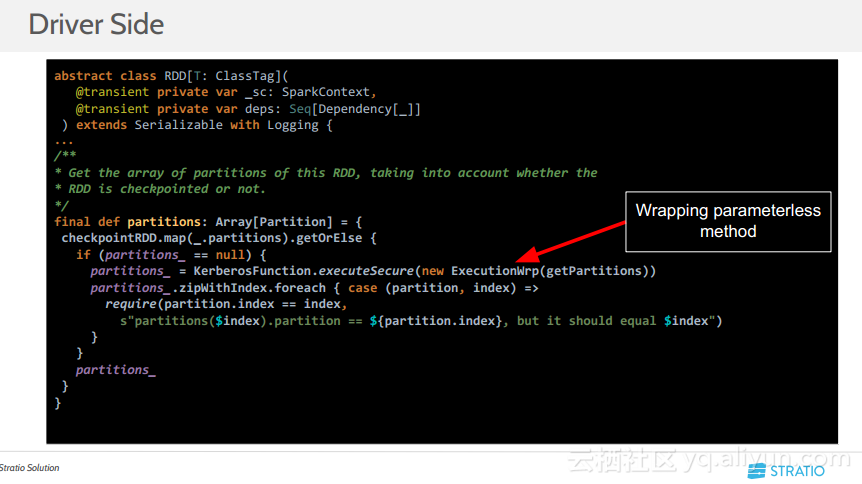
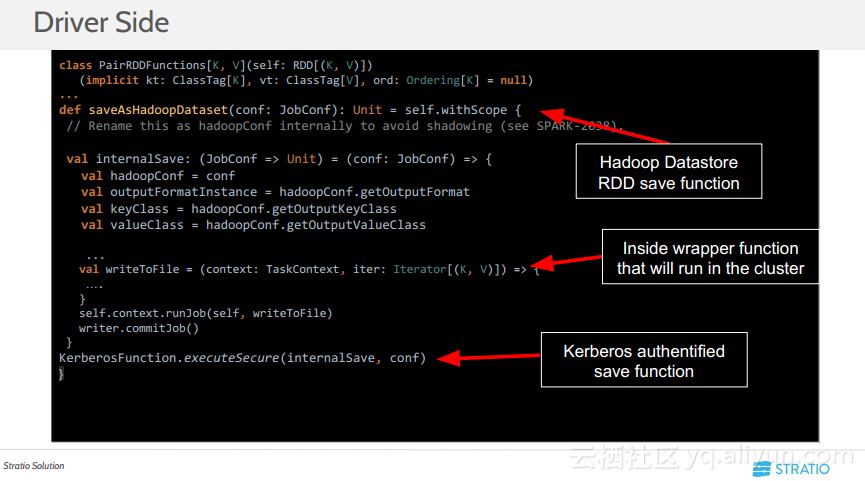
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
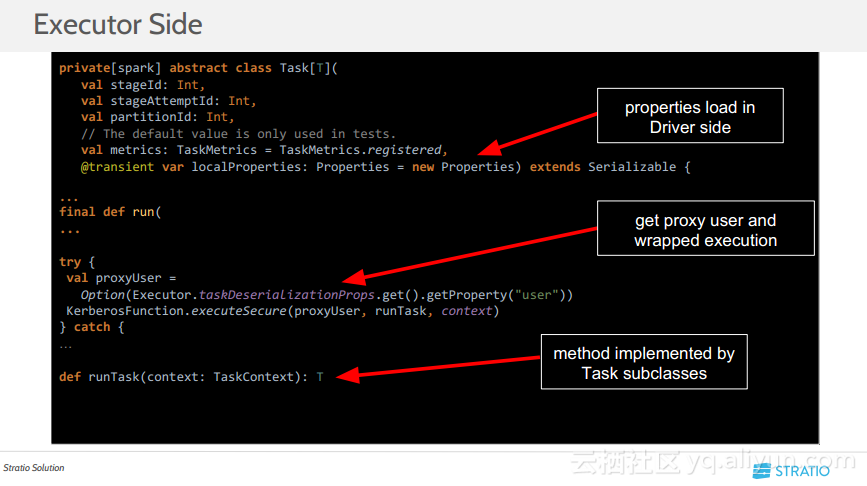
本讲义出自Abel Rincon与Jorge Lopez-Malla在Spark Summit East 2017上的演讲,主要介绍了Spark作为主流的大规模并行处理框架,HDFS作为最受欢迎的大数据存储技术,两者之间的结合通常是大数据的常见用例,本讲义分享了如何使得两种技术同处于安全的环境中,另外随着BI技术适应大数据环境,要求几个用户能够同时与集群进行交互,如何保证环境的安全也是一个挑战。