更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
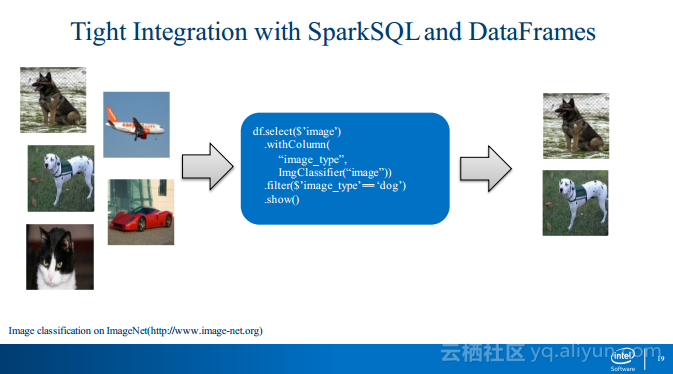
本讲义出自Jiao Wang与Yiheng Wang在Spark Summit East 2017上的演讲,在今天的互联网应用和新兴智能系统中,人工智能扮演着非常重要的角色,这驱动着需求的扩展以及分布式大数据分析能力与深度学习的能力的提升。在演讲中Jiao Wang与Yiheng Wang分享了Intel以及用户使用开源的Apache Spark分布式深度学习库BigDL构建的大数据机器学习应用。