更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
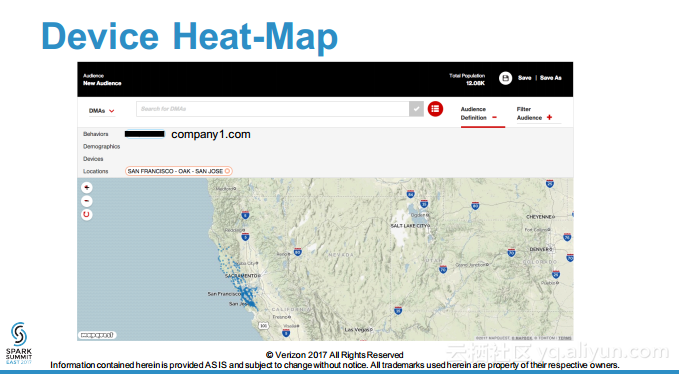
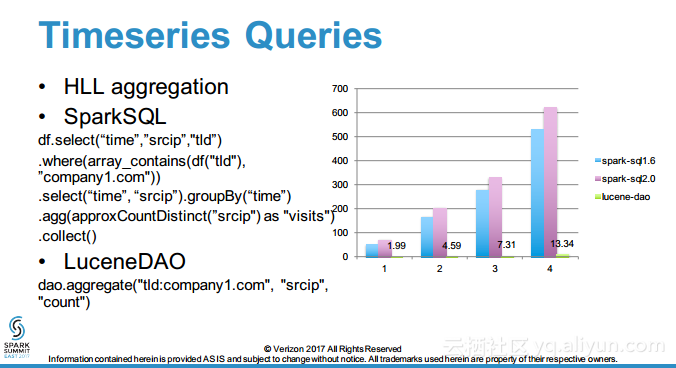
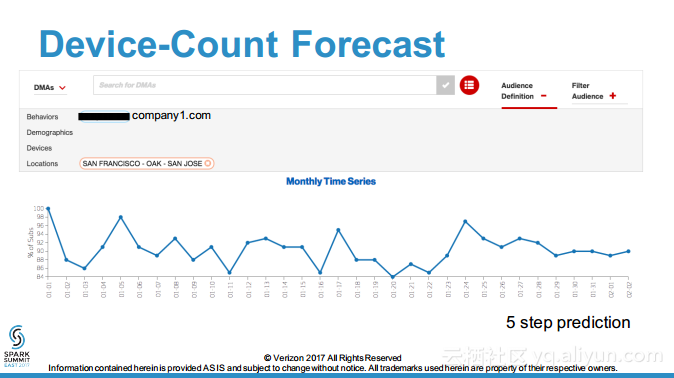
本讲义出自Debasish Das在Spark Summit East 2017上的演讲,主要介绍了对于LuceneDAO进行的扩展,允许其从文档术语的观点来使用时间戳进行搜索和时间过滤,演讲中展示了对于一整套查询生成的API,核心观点是通过理解如何使得 Lucene能够意识到在Spark中时间意识是非常重要的,进而构建交互式分析查询处理和时间序列预测算法。