更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
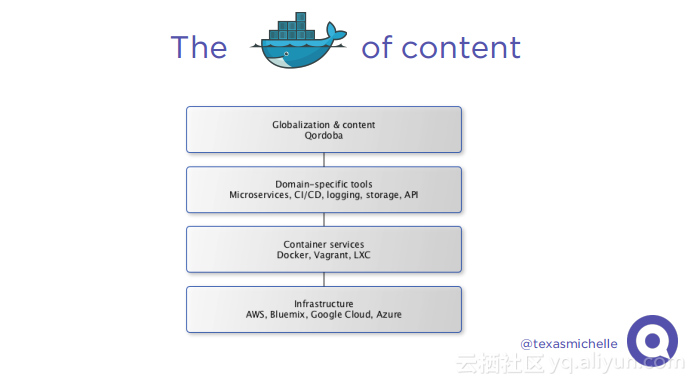
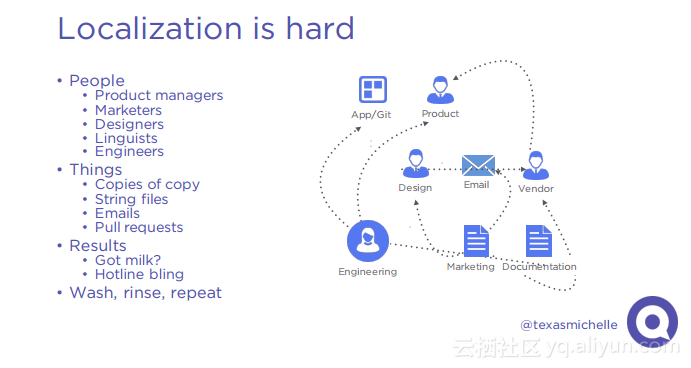
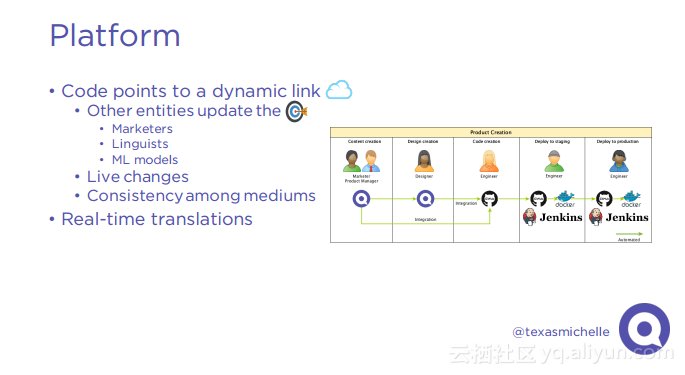
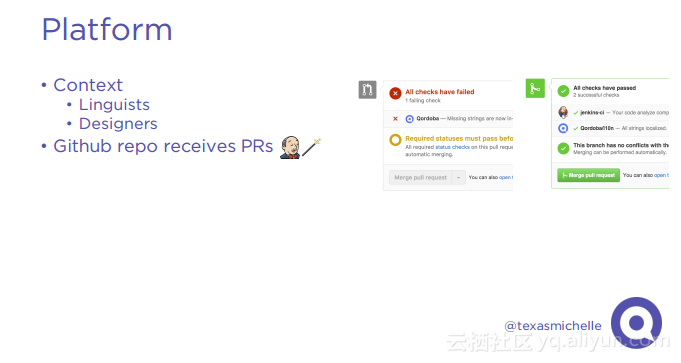
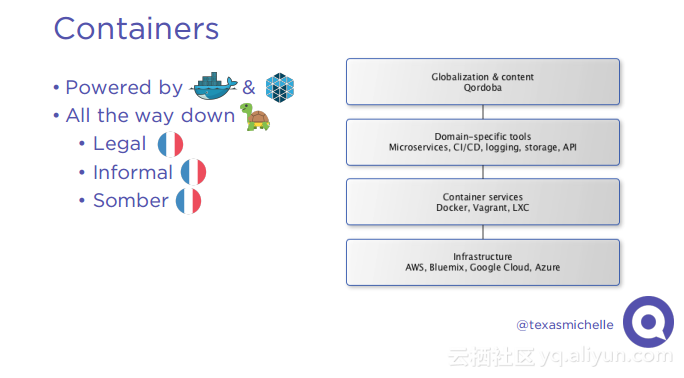
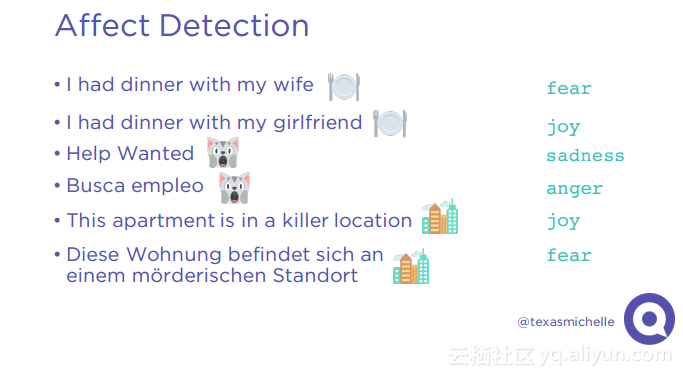
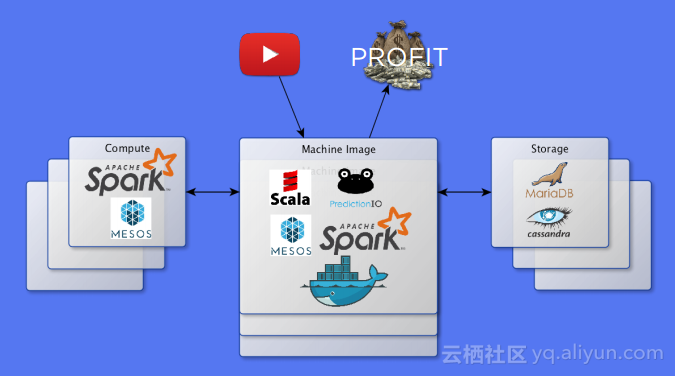
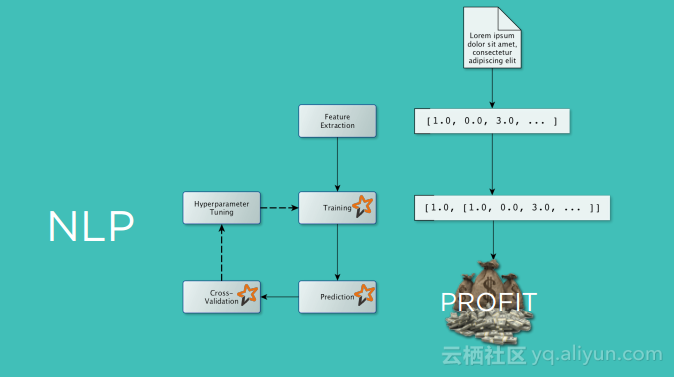
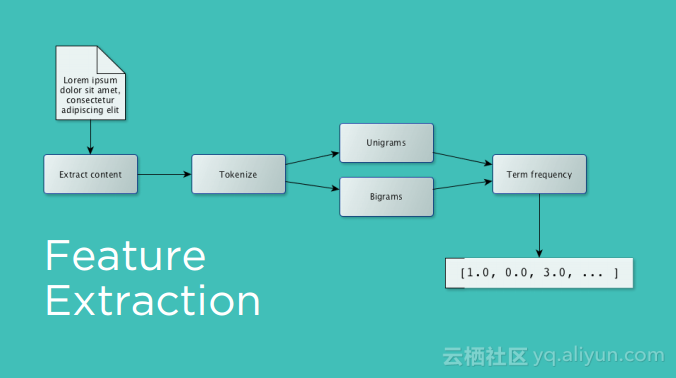
本讲义出自Michelle Casbon在Spark Summit East 2017上的演讲,为了建立一个全球的用户群,一个产品需要支持多种语言环境,这带来挑战是在不同语言环境下对于字符进行本地化,Qordoba为了应对这些挑战,使用了高度可扩展的机器学习和自动化计数,使用Scala和Akka作为编排层,Apache Cassandra和MariaDB作为存储层,Spark进行自然语言处理,Kafka作为消息总线。