更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
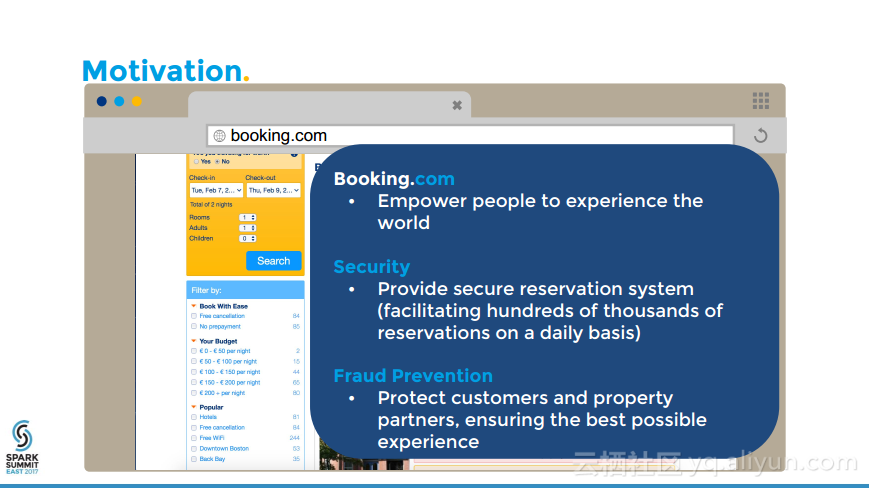
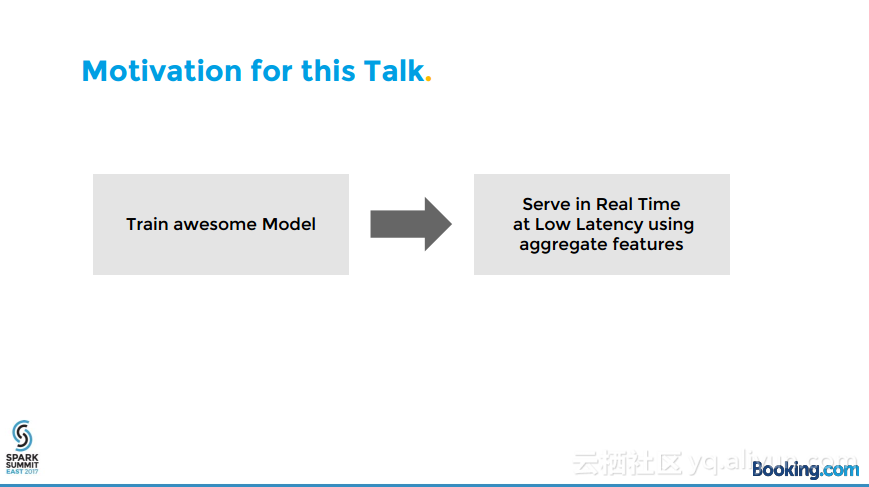
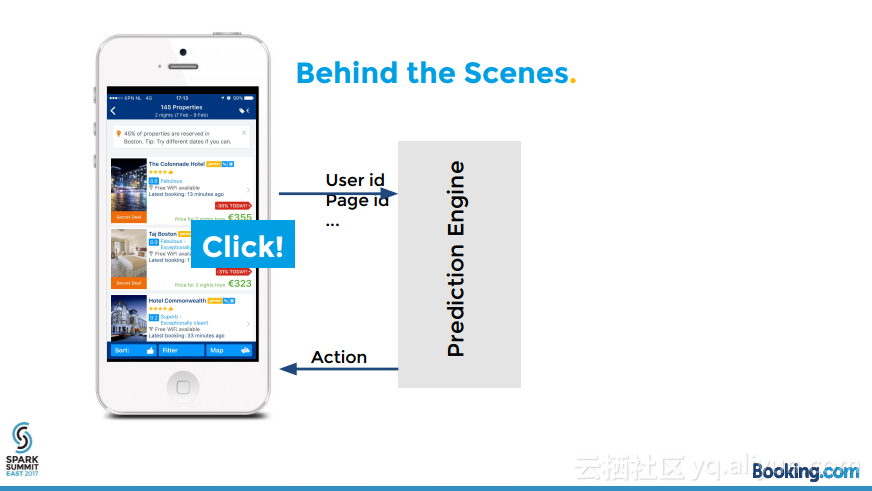
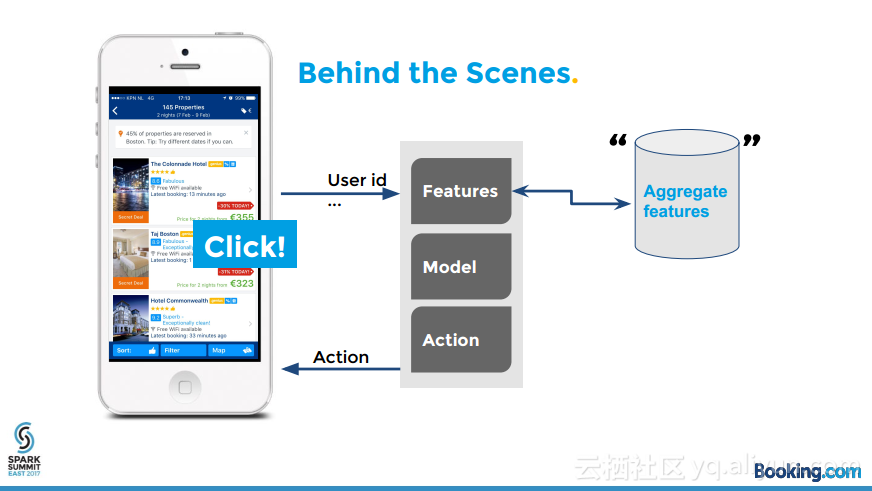
本讲义出自Kees Jan de Vries在Spark Summit East 2017上的演讲,骗子总试图使用盗取来的信用卡购买商品,预定机票和酒店等,这伤害了持卡人的信任和供应商在世界各地的业务,本讲义介绍了使用开源大数据软件:Spark, Spark ML, H2O, Hive, Esper等构建的实时防欺诈引擎,并介绍了面对的挑战。