前言
目前出行市场主要分为传统和新兴两个阵营:私家车、公共交通、出租车和长租车为传统出行提供服务,共享单车、网约车以及分时租赁共享汽车则是最近几年兴起的出行方式。
_图1 出行方式分析_
出行者往往是在成本和出行便捷之间权衡选择出行方式。从出行距离来看,在0~10公里以内,共享单车、网约车以及出租车兼具了低成本以及灵活性两个优势,所以往往是出行者的首选。超过100公里以上,私家车以及长租车则会显现其便捷性。但是在10~100公里之间,则存在一个出行服务真空市场。另外,在一二线城市中,10公里以上的出行需求还是非常大的,加上近几年国家的政策导向,国内出现了很多共享汽车租赁平台。按照罗兰贝格估算,2025年有600万辆分时租赁汽车,每辆车每天3-4单,日订单量约2000万单。这个行业还是具备很大的潜力。
本文主要介绍如何基于Tablestore的Timestream来快速实现共享汽车管理平台的数据存储。
需求分析

_图2 共享汽车管理平台需求_
对于出行者来说,使用共享汽车的流程主要是租车、用车以及还车:
- 租车:对车辆进行检索,比如说查询附近的空闲车辆,根据车型、续航进行过滤等;
- 用车:操作驾驶车辆,在这个过程中为了方便平台管理以及后续的订单计费,往往会对车辆的实时监控信息进行上传,比如说轨迹、时速、续航等信息;
- 还车:结束并且计算订单费用,后续提供订单检索以及相关信息查询,比如费用、轨迹、车辆等信息;
对共享汽车管理平台来说,其核心功能则是车辆管理和订单管理:
- 车辆管理:车辆的元信息和当前状态管理,提供给出行者查找满足需求的车辆,也方便平台进行车辆调度;另外,需要保存车辆轨迹信息,便于实现订单计费以及轨迹查询;
- 订单管理:对订单进行计费,以后提供给用户进行检索
另外,作为管理平台,还需要对订单以及车辆的业务数据进行分析,调度车辆来更好的满足出行者的需求,最大化车辆使用率,比如说什么区域出行需求很大,经常导致供不应求需要提供更多的车辆等。
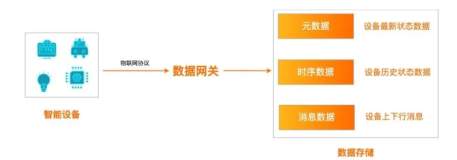
从上面的分析可以看到,共享汽车管理平台主要需要存储车辆和订单两部分数据,其中车辆包含了元信息(车牌、车型、颜色等)、行车轨迹、状态(车速、是否使用中等),订单则包含了车辆、用户、时间、状态等信息。下面对这些数据进行分析:
- 车辆元信息:数据量取决于车的数量,大概会有几十万~几千万的量,并且需要对这部分数据进行多条件检索;
- 车辆轨迹&状态:这部分数据的规模是非常大的,假设车辆行驶过程中10s上传一个监控点,那么平均每秒则会有几万~几百万的数据写入,一天下来十亿甚至百亿级的记录;这部分是典型的时序数据,为了降低存储成本,往往需要数据生命周期的管理;
- 订单:平均每天每辆车会3~6单,那么一天则会有百万甚至千万级的订单,数据量也是非常庞大的,另外,还需要实现复杂的数据检索能力;
从上面的分析可以看到,为了满足海量的订单以及车辆监控数据的存储需求,极高的写入吞吐、海量存储规模、可控的存储成本成为必须要解决的问题。
解决方案
传统解决方案

_图3 传统解决方案_
上面是共享汽车平台的传统解决方案,用MySQL来存储车辆基本信息,订单信息、轨迹以及状态数据由于数据规模比较大,其存储是经过流计算分析后写入到hbase中,在同步到solr提供数据检索能力。这个架构存在以下不足之处:
- 架构:使用多种数据存储产品,系统相对复杂,并且MySQL和HBase都需要全自主运维,复杂度很高;
- 规模&扩展性:MySQL无法支撑大规模的数据存储,并且为了满足数据多条件检索需求,可能需要创建多个索引,效率较低;
- 稳定性&数据可见延迟:轨迹、订单以及状态数据在经过流计算引擎分析之后才写入HBase最终同步到solr,整个链路非常长,稳定性有一定风险,并且数据经过流计算后才能写入到数据库中,可见性存在一定的延迟;
- 成本:MySQL/HBase均不是存储计算分离的产品,并且是按实例/机器购买,需要根据业务的峰值购买资源,成本较高;
在这个场景中,主要包含了三个数据存储需求:关系型数据、大规模时序数据以及大规模数据检索,在传统解决方案中,使用了三种不同的服务来满足业务需求,但Tablestore作为一款阿里自研的分布式NoSQL服务,提供多元索引支持丰富的查询需求,支撑超大规模的并发访问和低延迟的性能,可以很好的满足这三个需求。
基于Tablestore解决方案

_图4 基于Tablestore解决方案_
上图则是基于Tablestore的系统架构,数据直接写入到Tablestore,在通过通道服务将数据增量流出到函数计算进行事件监测,以及流到流计算系统进行后计算,再将计算之后的结果写回到表格存储中。相比传统架构,该架构有以下优势:
- 使用单一数据库满足业务需求,架构简单,全托管零运维;先存储后计算,数据可见延迟低
- 提供PB级的存储,每秒千万级的写入,以及千万级的元数据检索能力
- 提供完整的时序模型,实现车辆状态数据和元数据统一存储方式,降低开发使用成本
- 弹性资源,存储自动扩容,计算自动扩展,自动热点处理,高效负载均衡
- 数据生命周期管理、冷热数据分层、按量付费、存储计算分离等功能,有效降低成本
- 完整计算生态:无缝对接流计算、即席计算以及离线计算,形成数据闭环
如何实现
前面分析过在共享汽车管理平台中,核心数据包含了车辆元数据、轨迹&状态数据,以及订单数据。其中订单数据的实现可以参考:《基于Tablestore打造亿量级订单管理解决方案》。
另外,车辆元数据、轨迹&状态数据的存储适用于用Timestream模型来快速高效的实现。Timestream是表格存储推出的最新数据模型,这个模型针对时序数据、轨迹数据、溯源数据,定义了一套简单清晰易用的API,细节可以参考《Tablestore Timestream:为海量时序数据存储设计的全新数据模型》。
模型映射
车辆元数据,顾名思义,就是Timestream模型中的元数据(Meta),车辆轨迹&状态数据则是Timestream的Data数据点。
从上面的Timestream介绍文章可知,Timestream拥有几个核心概念,分别是:Name, Tag, Attribute, Timestamp, Point(Fields)。我们罗列一个表格,展示怎么将车辆的相关数据映射到Timestream的模型中,如图所示:
图5 数据模型映射
- 分类(Name)+标识符(Tag): 这两个字段唯一确定一辆车,包含平台信息、车辆ID;
- 元数据(Attribute): 车辆的相关属性,车辆的一些属性信息,比如车型、车牌号、颜色、乘坐人数等;
- 最新状态数据(Attribute): 如标题,车辆最新的状态,比如上面的‘地点’信息,我们可以创建Geo的索引,可以根据地理信息的查询;
- 时间(Timestamp): 状态/轨迹数据的发生时间;
- 轨迹、时速、状态: 具体的状态数据,上面只是三个示例,实际上可以支持非常多的字段,由业务决定;
接下来我们通过一个可以运行的Demo,向大家展示怎么使用Timestream API快速实现车辆轨迹、状态管理功能。
功能实现
功能列表
写入
- 车辆接入平台,以及元数据更新,将车辆的相关元数据存储至Timestream,并更新其轨迹&状态数据
- 车辆运行轨迹与状态持久化,便于后续进行订单轨迹查询,以及后台实时进行分析,比如说订单是否出现异常
查询
- 检索附近的空闲车辆
- 根据车型和续航等条件进行车辆检索
- 车辆轨迹重放
依赖
<dependency>
<groupId>com.aliyun.openservices</groupId>
<artifactId>tablestore</artifactId>
<version>4.11.2</version>
</dependency>Meta表的创建
对于一些固定且有特殊索引需求的字段,我们在创建Meta表的时候需要单独指定,比如续航、地理信息、状态数据等。
以下示例只是给了部分元数据字段,用户可以根据自己的需求设置更多的索引字段。
public void createMetaTable() {
db.createMetaTable(Arrays.asList(
new AttributeIndexSchema("地区", AttributeIndexSchema.Type.KEYWORD),
new AttributeIndexSchema("车型", AttributeIndexSchema.Type.KEYWORD),
new AttributeIndexSchema("车牌", AttributeIndexSchema.Type.KEYWORD),
new AttributeIndexSchema("颜色", AttributeIndexSchema.Type.KEYWORD),
new AttributeIndexSchema("座位", AttributeIndexSchema.Type.LONG),
new AttributeIndexSchema("续航", AttributeIndexSchema.Type.LONG),
new AttributeIndexSchema("状态", AttributeIndexSchema.Type.KEYWORD),
new AttributeIndexSchema("当前位置", AttributeIndexSchema.Type.GEO_POINT)
));
}Data表的创建
这个比较简单,只需要设定表名即可。因为我们是Schema Free的体系,不需要预先指定列,在写入的时候指定即可。
public void createDataTable() {
db.createDataTable(dataTableName);
}数据写入
- 车辆元数据写入
车辆元数据写入包含两个部分,第一个是车辆接入平台时,将完整的信息写入;第二个是后续状态数据发生变化时,按需更新元数据中的最新状态。
public void writeMeta() {
TimestreamIdentifier identifier = new TimestreamIdentifier.Builder("*滴")
.addTag("ID", carNo)
.build();
// 插入车辆信息
TimestreamMeta meta = new TimestreamMeta(identifier)
.addAttribute("地区", "杭州")
.addAttribute("车型", "奇瑞EQ1")
.addAttribute("车牌", "浙AD75138")
.addAttribute("颜色", "白")
.addAttribute("座位", 4)
.addAttribute("续航", 120)
.addAttribute("当前位置", getRandomLocation())
.addAttribute("状态", "闲置");
metaWriter.put(meta);
// 更新车辆元数据的最新状态
meta = new TimestreamMeta(identifier)
.addAttribute("当前位置", getRandomLocation())
.addAttribute("状态", "使用中");
metaWriter.update(meta);
}- 车辆状态&轨迹数据写入
public void writeData() {
TimestreamIdentifier identifier = new TimestreamIdentifier.Builder("*滴")
.addTag("ID", carNo)
.build();
TimestreamDataTable dataWriter = db.dataTable(dataTableName);
Point point = new Point.Builder(1546272000, TimeUnit.SECONDS)
.addField("位置", "30.1457580736,120.0563192368")
.addField("车速", 30)
.addField("续航", 100)
.build();
dataWriter.asyncWrite(identifier, point);
}数据查询
- 检索附近的空闲车辆
这里根据车辆平台、地区、当前位置,以及状态的状态检索可用的车辆。
Filter filter = and(
Name.equal("*滴"),
Attribute.equal("地区", "杭州"),
Attribute.inGeoDistance("位置", "30.1457580736,120.0563192368", 1000),
Attribute.equal("状态", "闲置")
);
Iterator<TimestreamMeta> iter = metaTable.filter(filter).fetchAll();
while (iter.hasNext()) {
TimestreamMeta m = iter.next();
System.out.println(m);
}- 根据车型和续航检索车辆
Filter filter = and(
Name.equal("*滴"),
Attribute.equal("地区", "杭州"),
Attribute.equal("车型", "奇瑞EQ1"),
Attribute.inRange("续航", 200, Long.MAX_VALUE),
Attribute.equal("状态", "闲置")
);
Iterator<TimestreamMeta> iter = metaTable.filter(filter).fetchAll();
while (iter.hasNext()) {
TimestreamMeta m = iter.next();
System.out.println(m);
}- 查询车辆在某个时间段内的轨迹
TimestreamIdentifier identifier = new TimestreamIdentifier.Builder("*滴")
.addTag("ID", carNo)
.build();
Iterator<Point> iter = dataTable.get(identifier).select("位置").fetchAll();
while (iter.hasNext()) {
Point p = iter.next();
System.out.println(p);
}Demo
https://ots.console.aliyun.com/index#/cn-hangzhou/demo/shareCar
欢迎加入
如果您对表格存储、时序模型感兴趣,对模型使用有疑问、想探讨,欢迎加入【表格存储公开交流群】,群号:11789671。