更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
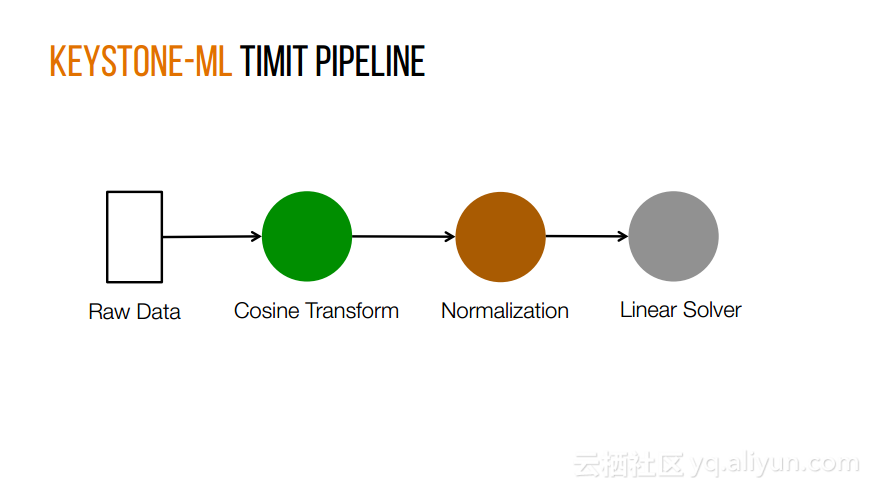
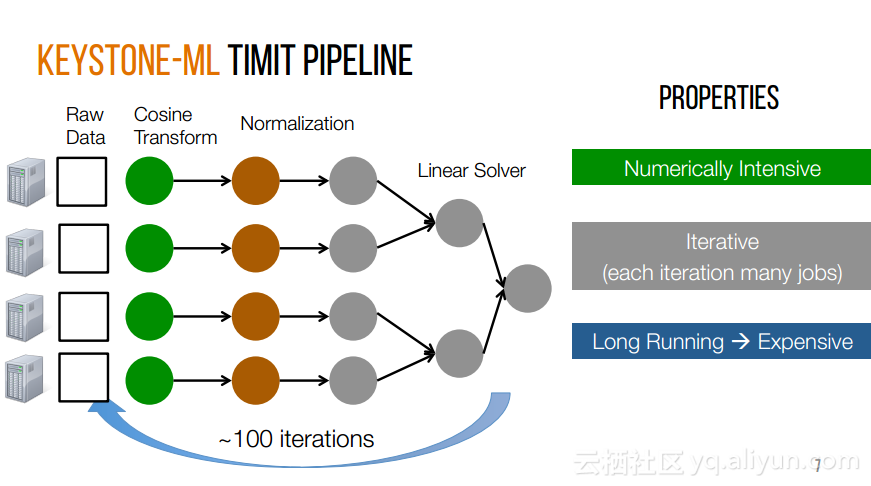
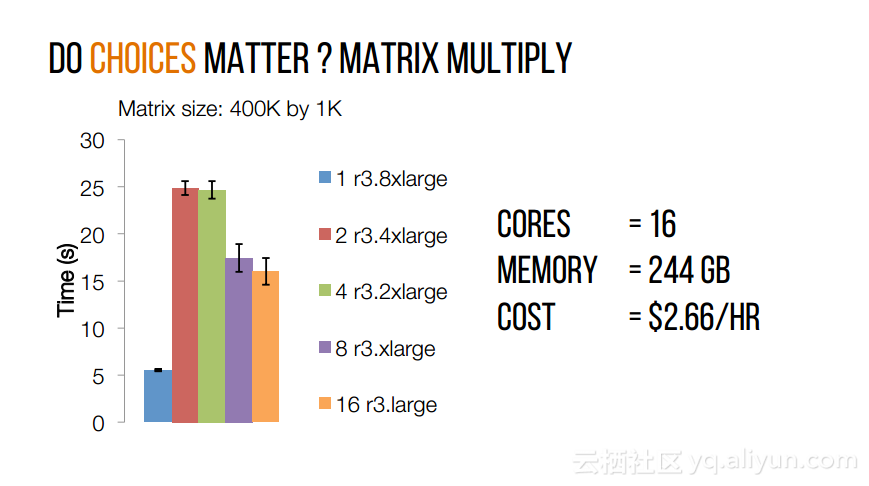
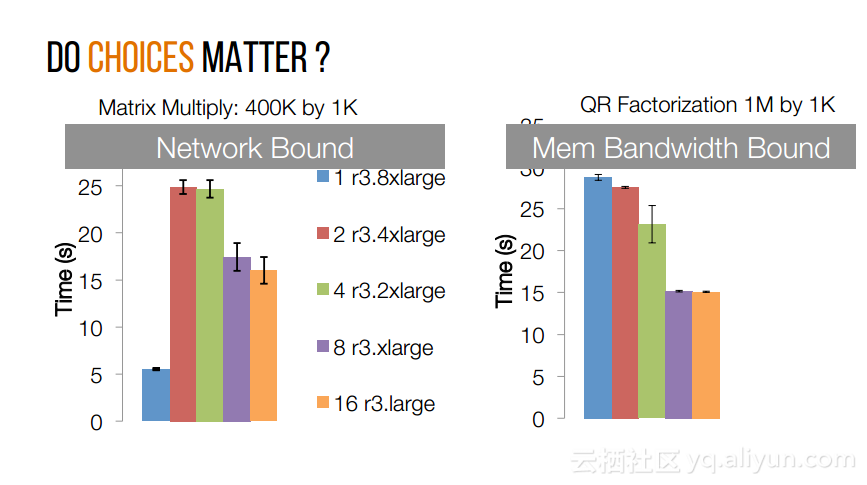
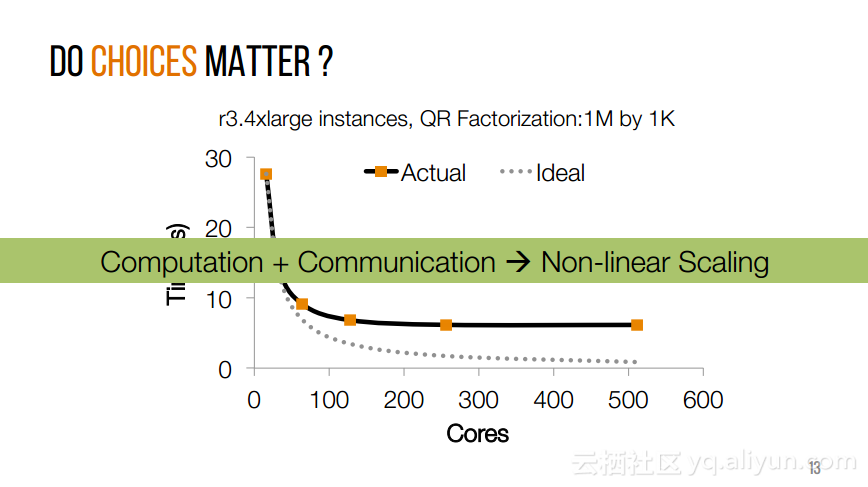
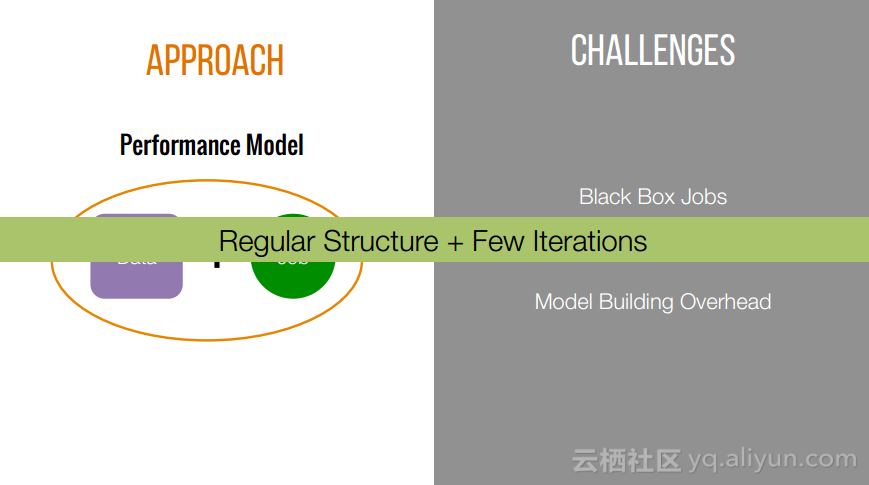
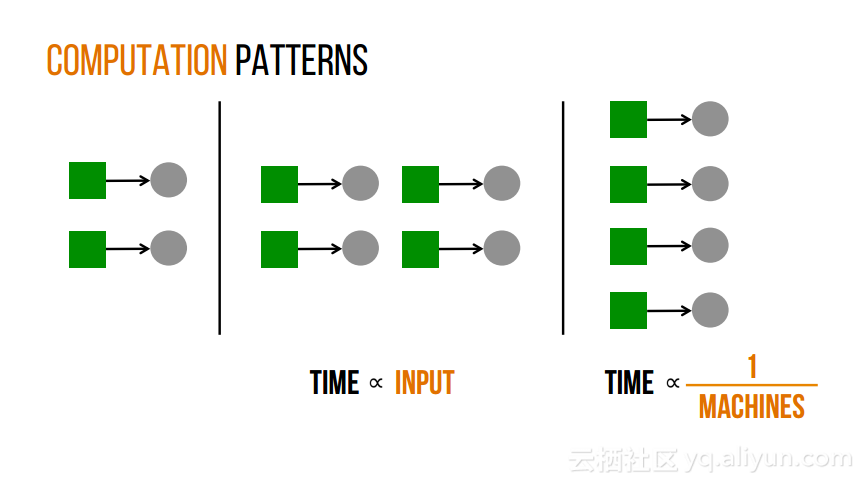
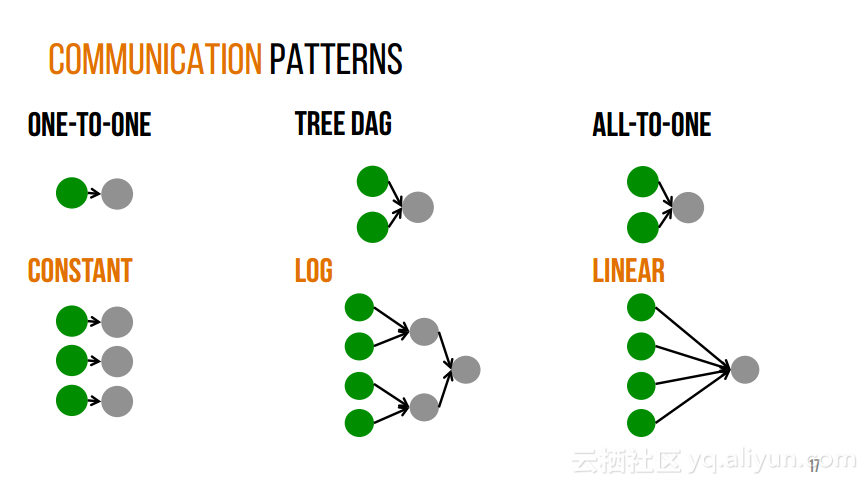
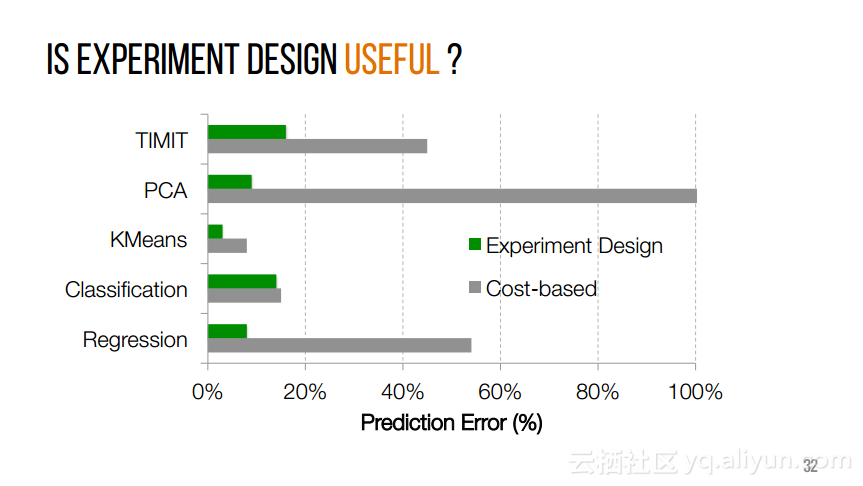
本讲义出自Shivaram Venkataraman在Spark Summit East 2017上的演讲,近期使用Spark进行机器学习,基因组学和科学分析呈现增长的趋势,然而将这些应用部署在云计算平台上是有一定挑战性的,而应对上述挑战的关键在于有能力预测的应用程序在保持高性能的状态下所需要的资源配置,这样就可以自动选择最优配置。本讲义主要介绍了Ernest——性能预测大规模分析的框架。