更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
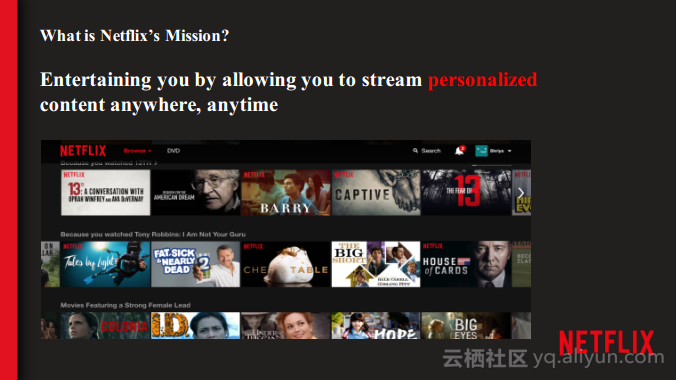
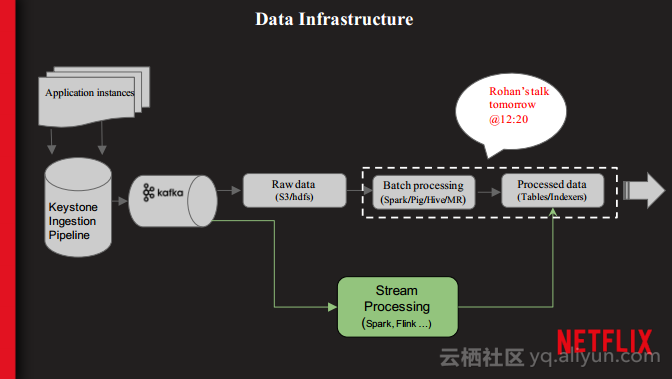
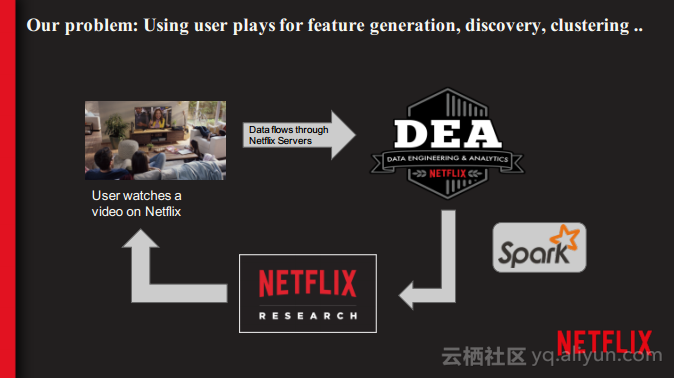
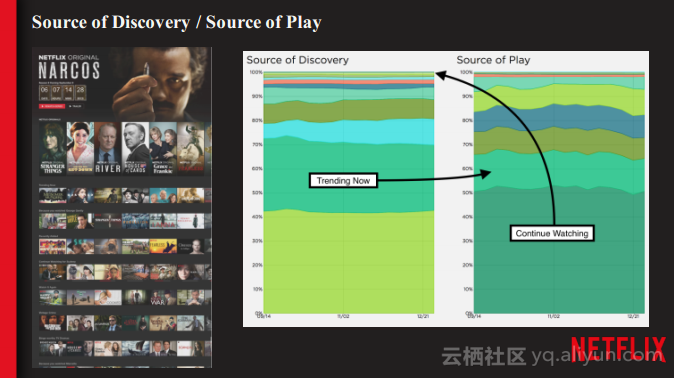
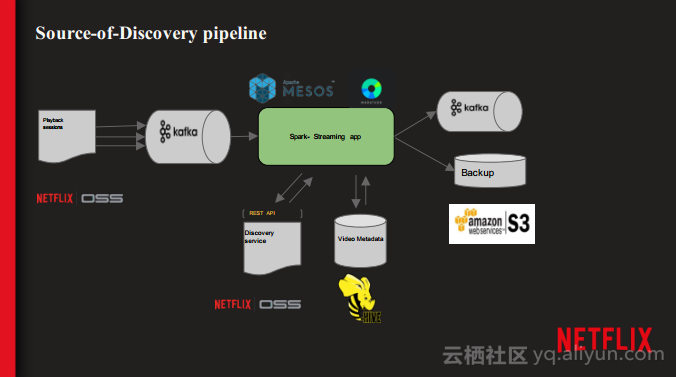
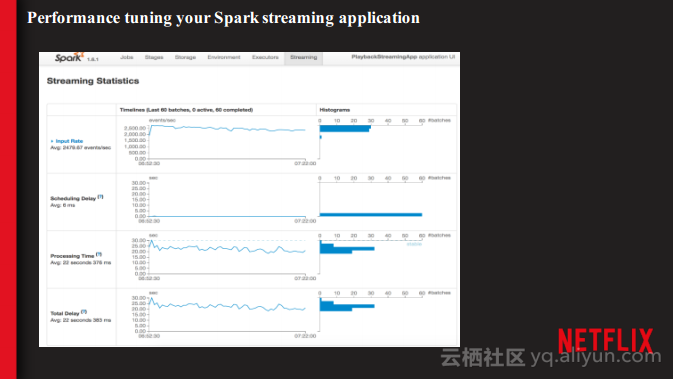
本讲义出自Shriya Arora在Spark Summit East 2017上的演讲,主要介绍了NETFLIX使用Spark处理个性化数据集空间的经验,并分享了使用流处理大规模的个性化数据集的案例,对于从批处理到流计算的转型意识以及这一过程中必须要面对的技术挑战。