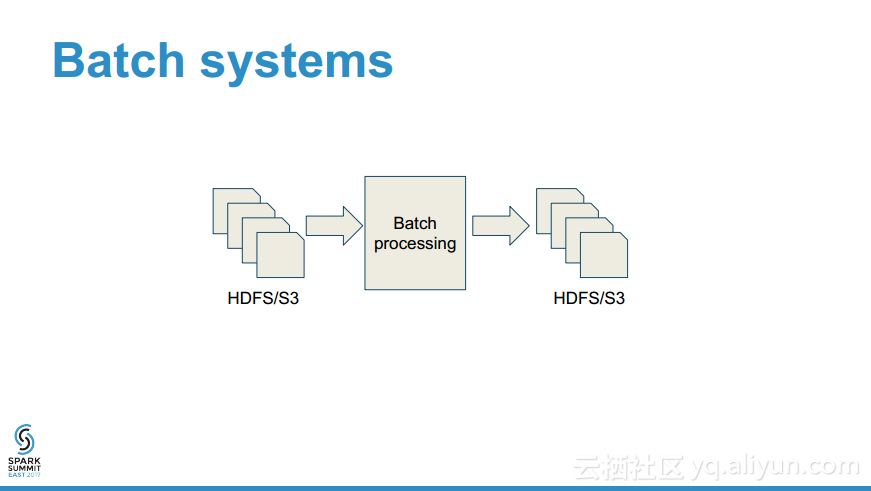
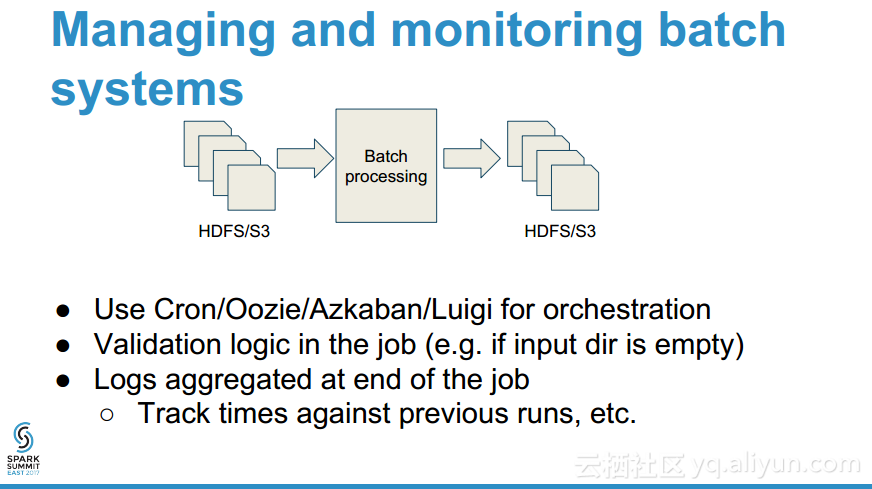
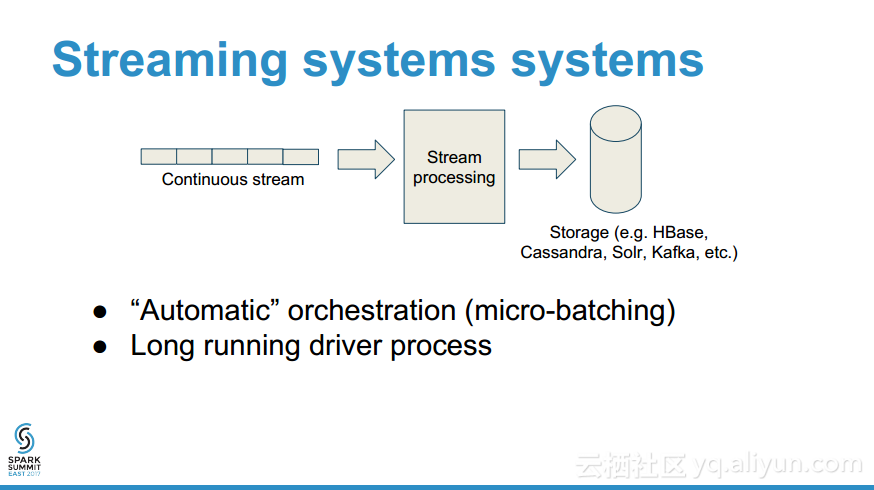
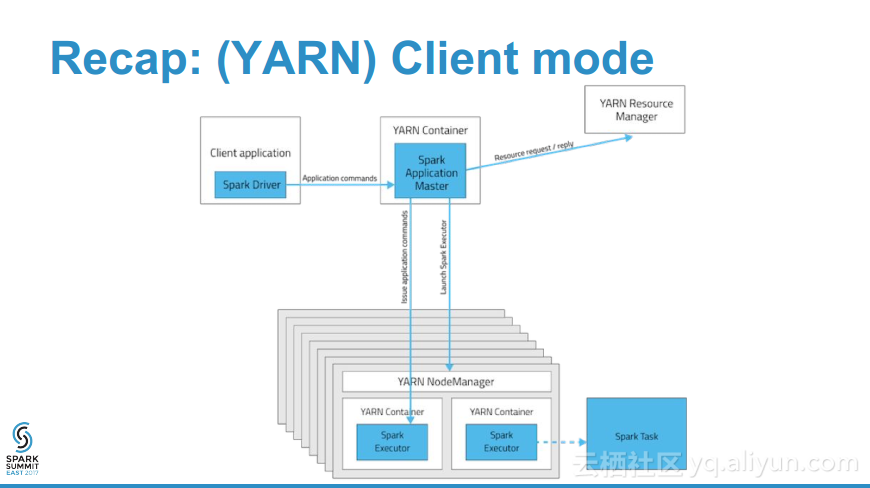
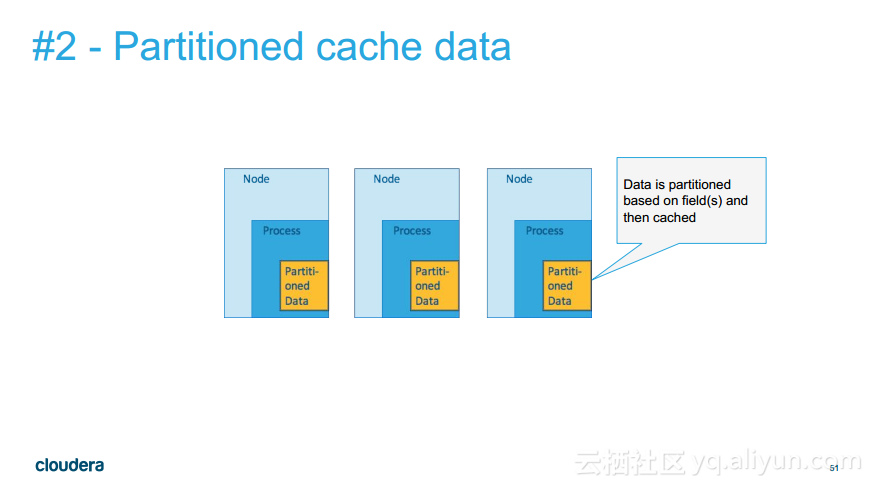
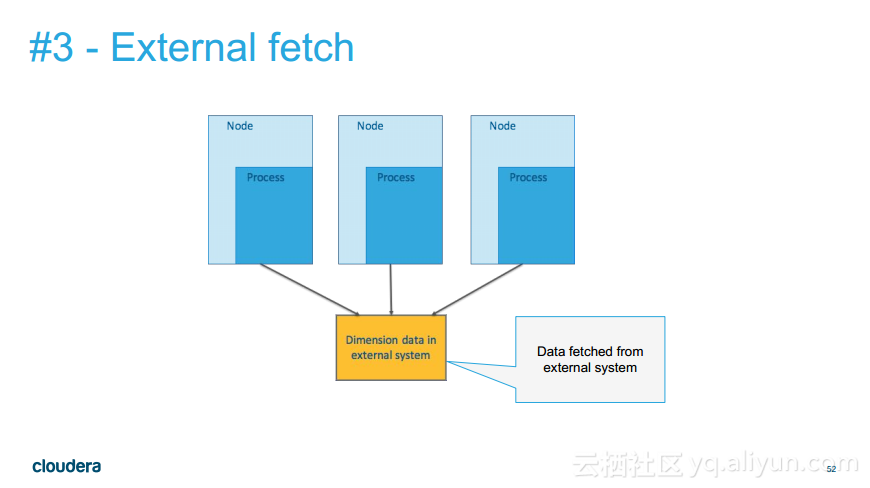
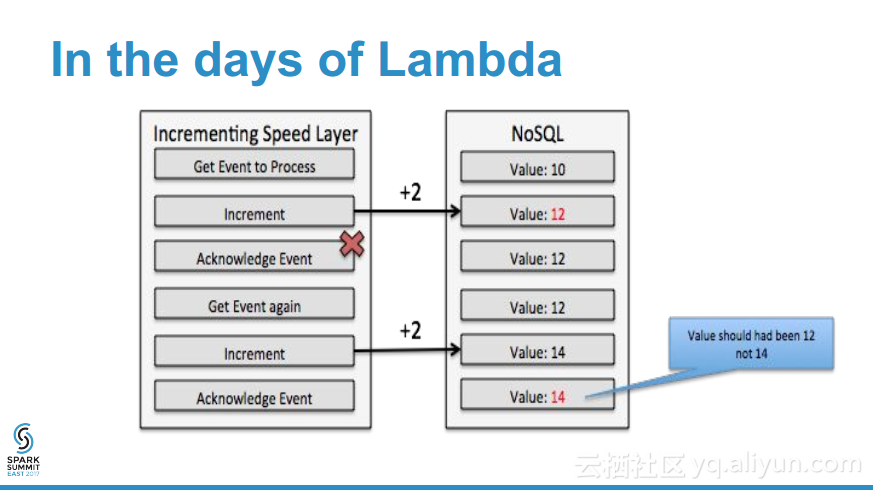
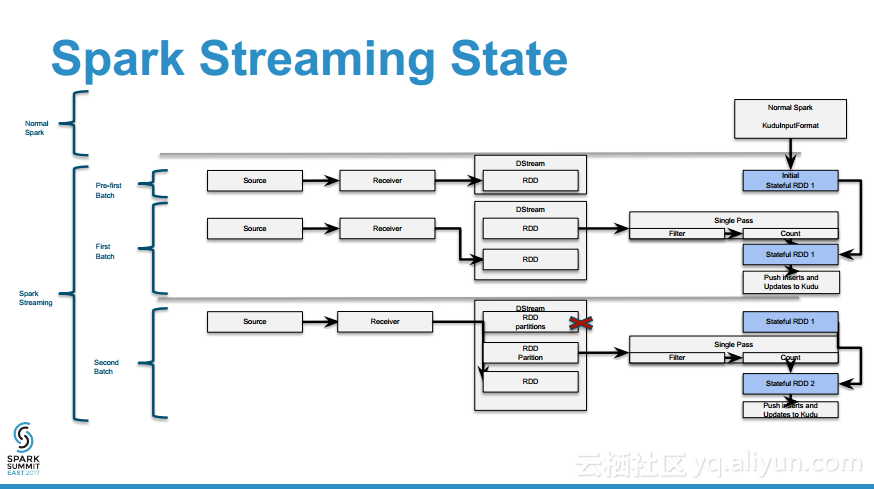
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
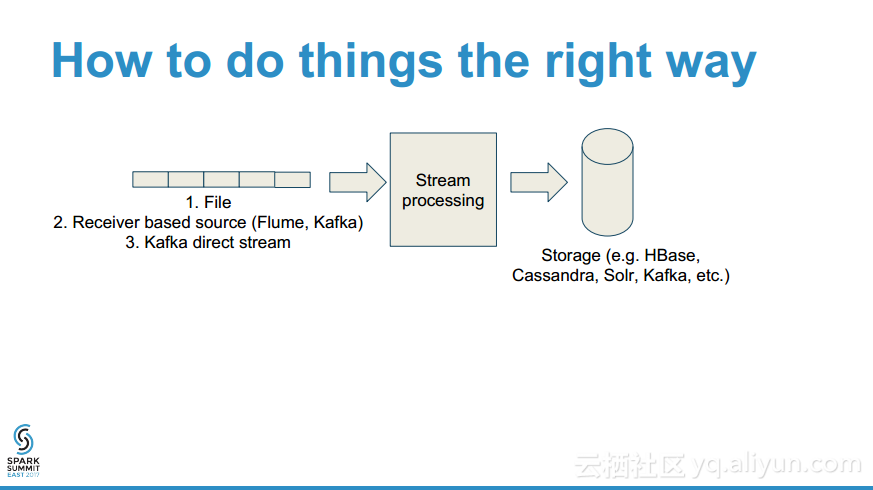
本讲义出自Mark Grover与Ted Malaska在Spark Summit East 2017上的演讲,如果你想开发一个非凡的流应用就不得不考虑以下的问题:
- 怎么管理补偿?
- 怎么管理状态?
- 如何让Spark Streaming工作能够从失败中恢复?能够避免一些失败吗?
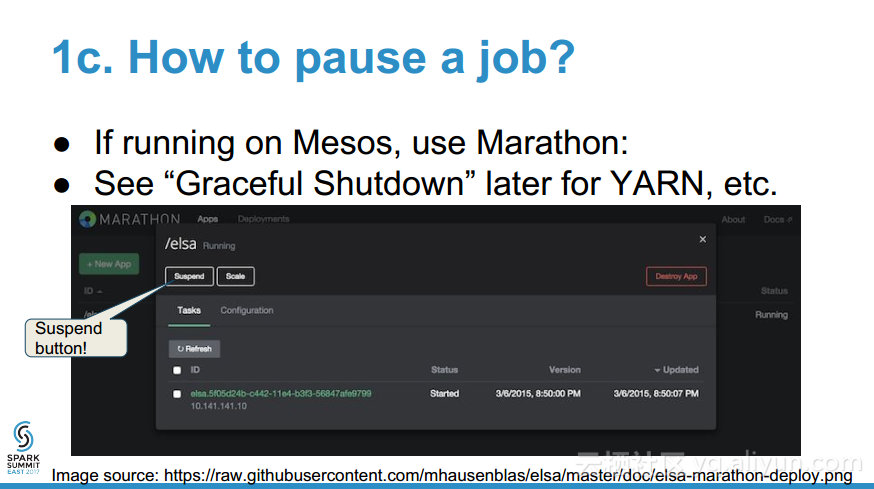
- 如何优雅地关闭流的工作?
- 如何监控和管理流的工作吗?
- 怎样才能更好地在流中管理DAG?
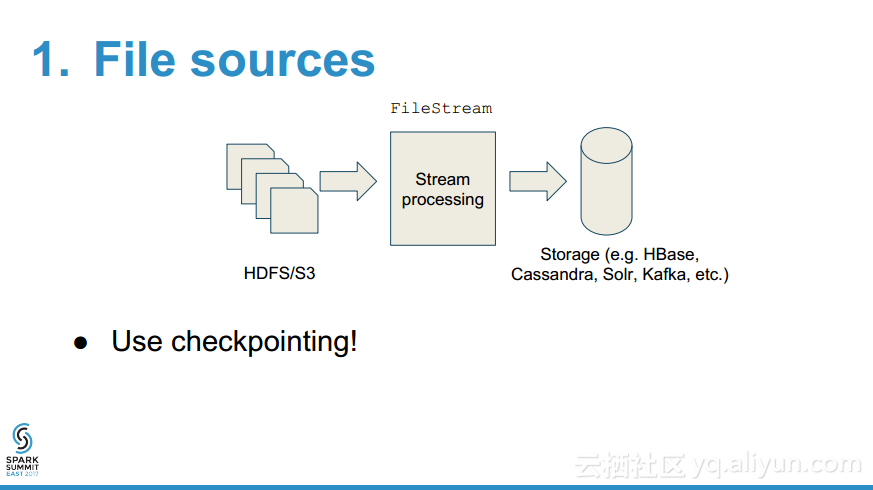
- 什么时候使用检查点,什么时候不用?
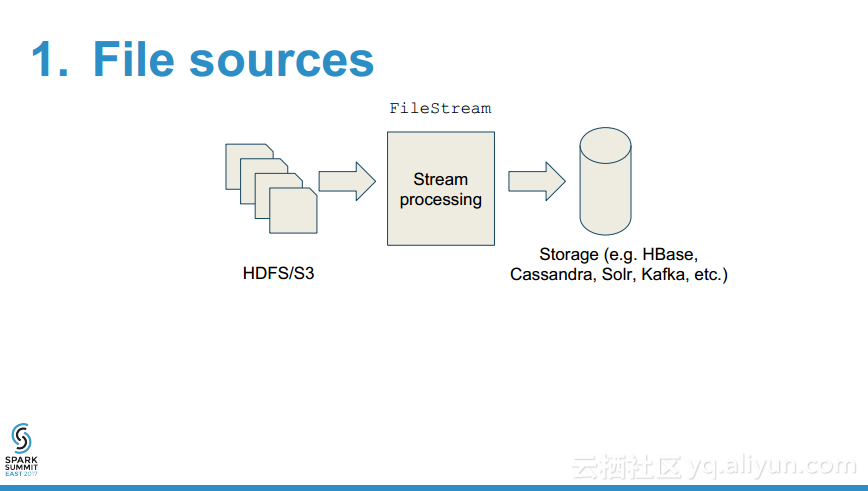
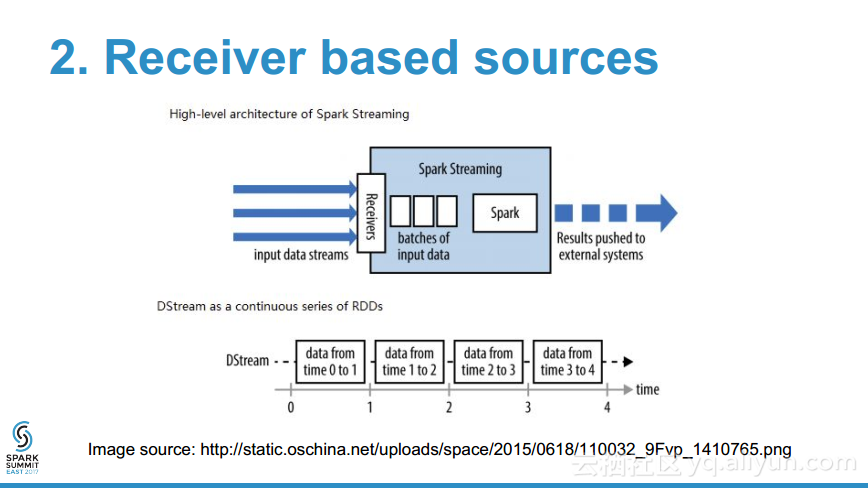
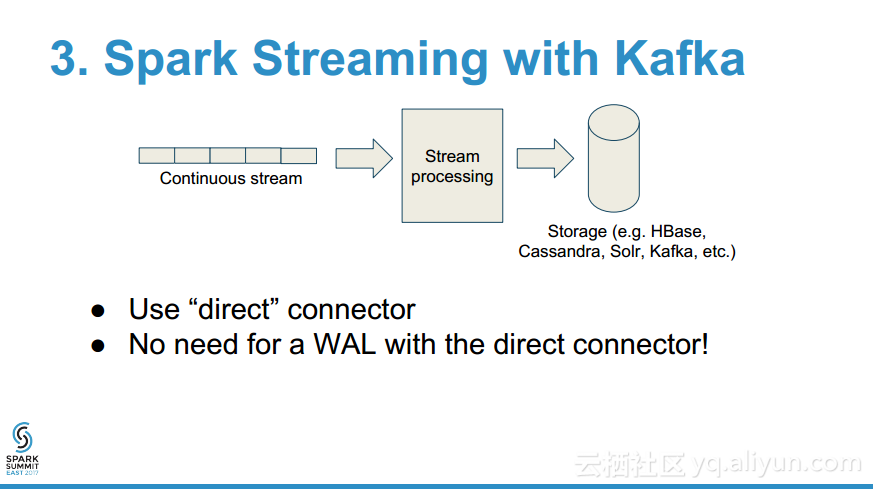
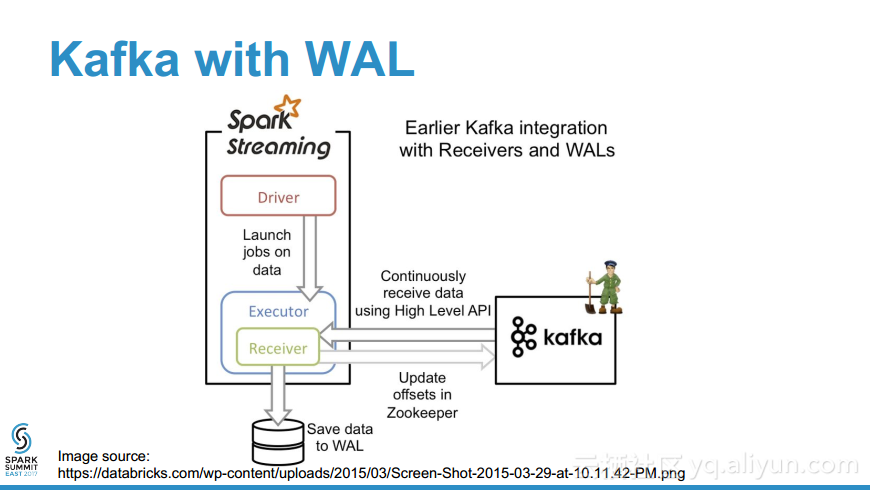
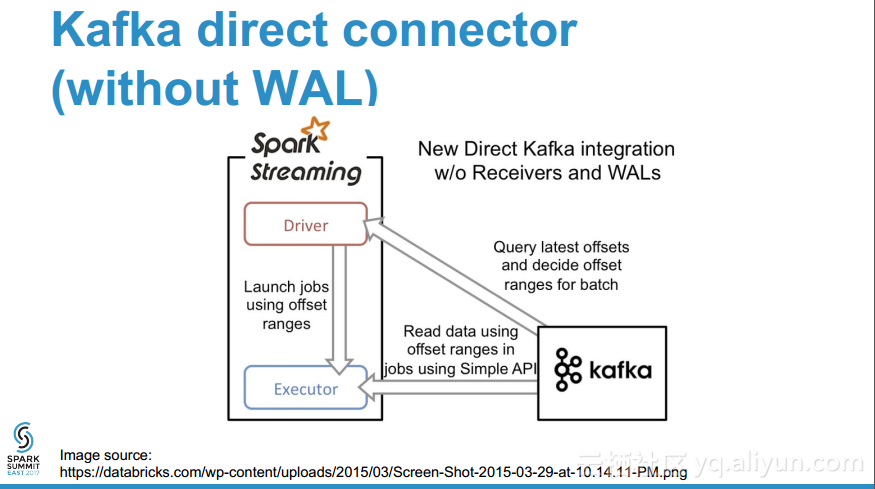
- 为什么在流数据源时需要WAL?