更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
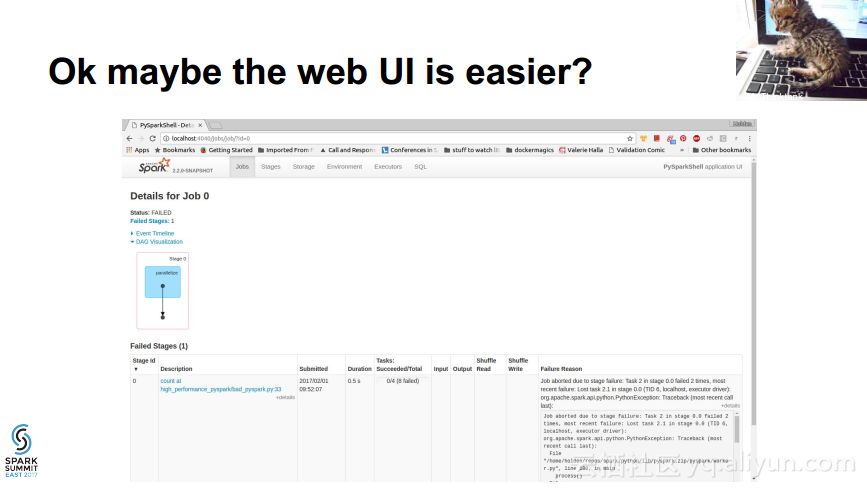
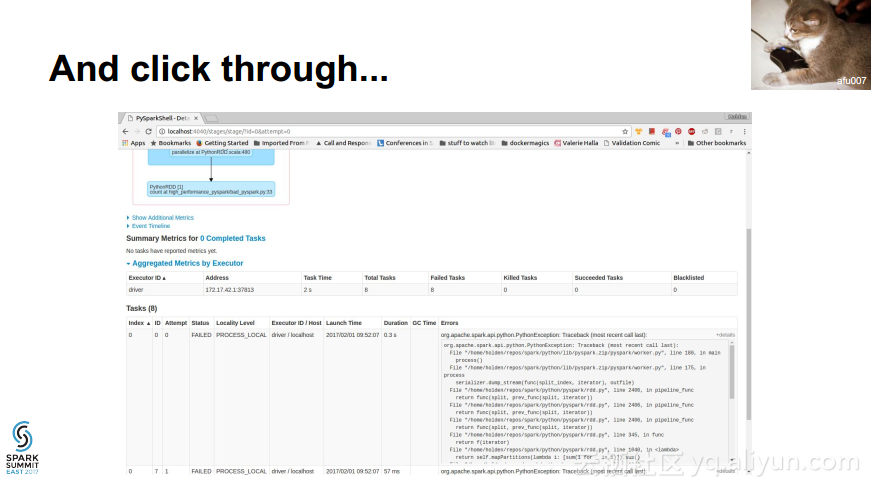
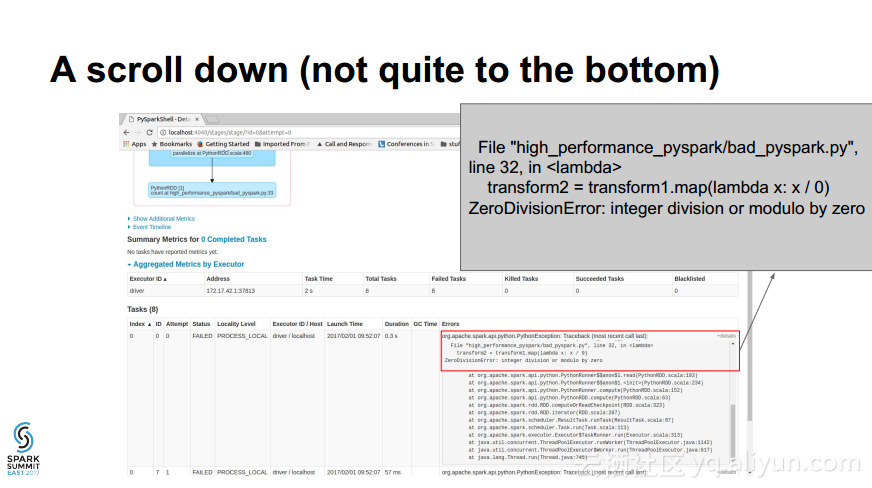
本讲义出自Holden Karau在Spark Summit East 2017上的演讲,主要介绍了如何对于Spark程序进行调试Debug,并介绍了登录时的对于Spark所支持的各种语言的不同选项以及常见的错误和如何对这些错误进行检测。




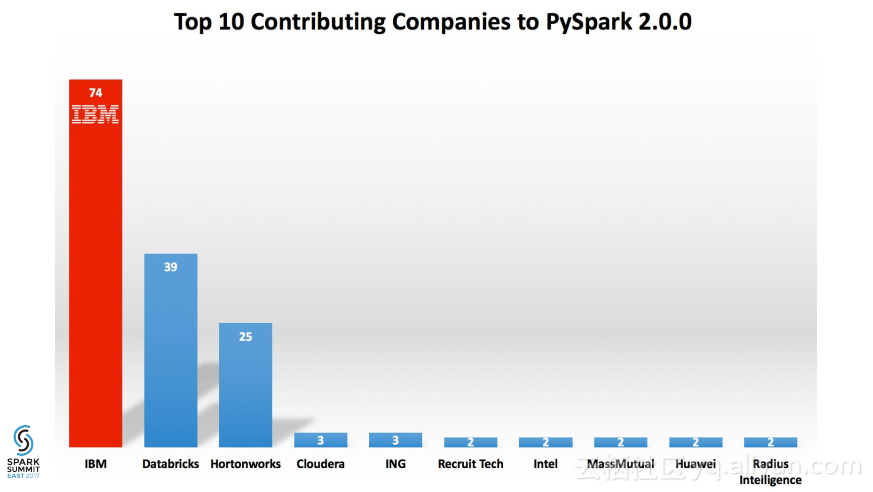





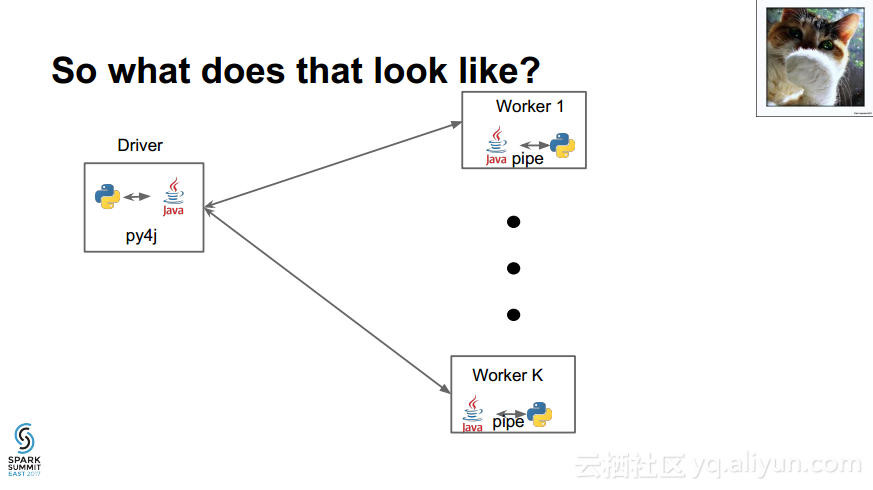


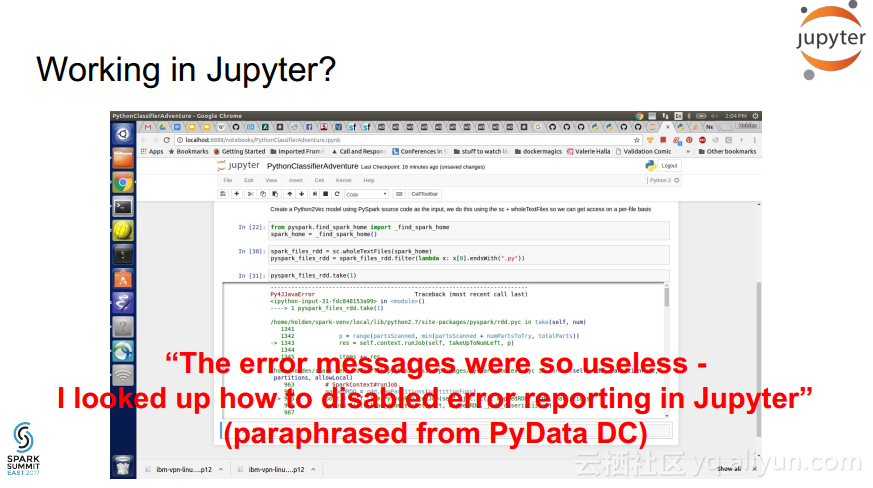
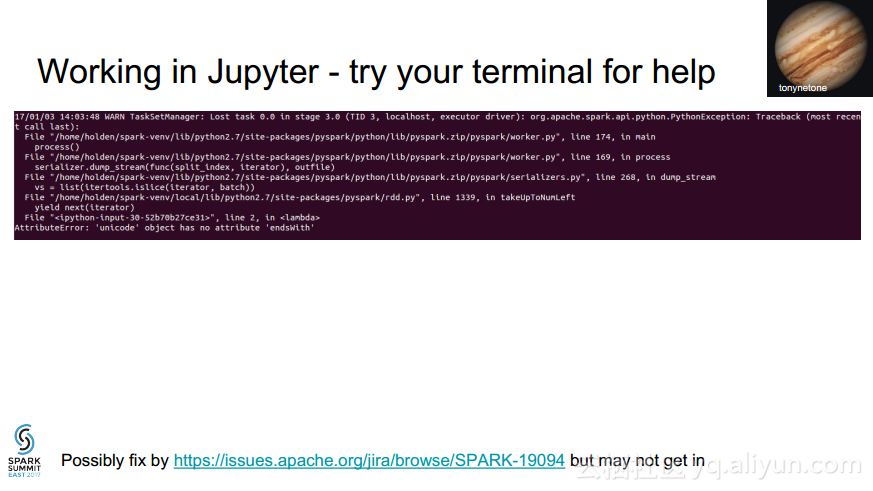

























更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
本讲义出自Holden Karau在Spark Summit East 2017上的演讲,主要介绍了如何对于Spark程序进行调试Debug,并介绍了登录时的对于Spark所支持的各种语言的不同选项以及常见的错误和如何对这些错误进行检测。
