更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
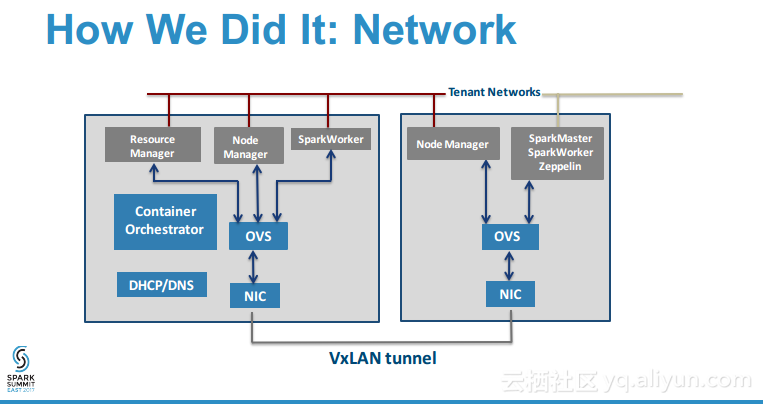
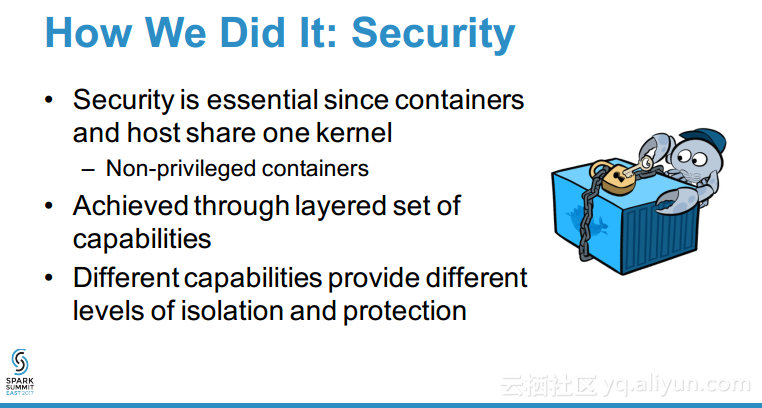
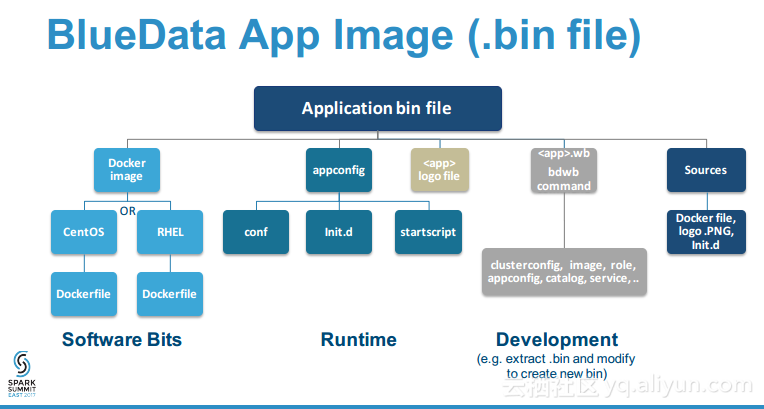
本讲义出自Tom Phelan在Spark Summit East 2017上的演讲,主要介绍了在Spark集群上部署分布式大数据应用程序面对的容器生命周期管理、智能调度优化资源利用率、网络配置和安全以以及性能等诸多挑战,Tom Phelan探讨了如何实现高可用性的分布式大数据应用和数据中心主机,并分享了学到的经验教训,并对于如何在一个可靠的、可伸缩的、高性能的环境将大数据应用程序容器化给出了一些提示。