地址 360大厦A座
花了一下午时间,总要有所收获,本人正在负责公司小kafka集群,所以对kafka相关课题比较关心,也有收获,Flink还未入坑,这里并没有Flink相关的收获。
美团
-
介绍了现状,Kafka集群在数据平台中的功能,通过介绍得知,其负责数据传输
- 一类是日志数据,业务日志和用户行为,一类是DB数据,应该是二进制流。
- 下游接入的是离线计算,实时计算,日志中心和OLAP。
- 入流峰值,3千万/s
-
然后介绍了高吞吐方面的优化
-
二次开发:Disk层面的Rebalance,解决了以下痛点:
- broker分配依据是Partition数,不够精细,会产生数倾斜。
- 新加入节点不会Rebalance
- Flink实时入仓,这个没懂。
- 硬件选型:与计算密集型混部,充分利用磁盘资源;JBOD最大化利用率;引入大CacheRaid卡,进一步增加缓存。
- 新缓存架构探索:FlashCache.
-
-
最后介绍了超大集群:1000+broker,40kTopics
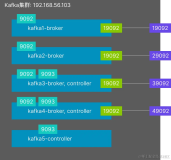
- 由于controller的瓶颈问题,集群规模一般不超过200broker,比如京东。
- 找到瓶颈,做了controller与broker分离,并集群化,提高其管理能力,解决大集群瓶颈问题。
- 建立了region隔离机制。(看来大集群还是要分割)
- 增加了SafeMode机制,中心节点不可用时集群仍能工作。
- 总结,目前阶段对我直接有用的(1)硬件选型和规划(2)普通集群瓶颈在哪,避免过大。
京东
- 现状:56个集群,broker1530,topic15699,分区460301
-
产品化:
- 跨机房灾备:mirror maker同步数据,就近消费,跨机房容灾靠dns切换域名。
- 读写分离:分别建立生产者集群和消费者集群,来解决消费者横向扩展问题和生产消费干扰的问题。(这个方案很新颖,是否合理呢?)
- 安全认证改进:去keytab,去jaas,Keberos认证,增加域名认证。
- 周边功能完善:集群管理、运维管理、权限管理、用户认证;监控,挤压监控、实时大屏;SDK封装、消息查询工具、样本提取过滤工具、运营报表
-
探索:
- 性能测试,挖掘:crc32优化,服务端解压缩问题,v1和v2协议性能对比
- 全链路域名化:对跨机房灾备,对用户访问透明有非常大的好处。
- Kafka on K8S vs 与实时计算服务器混部
- 总结:觉得京东还是做了些有意义的工作,没有过度定制kafka,尊重生态,改进生态。很多建议和经验放到小公司也可以得到借鉴。