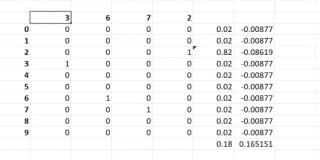
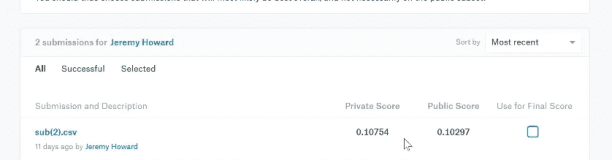
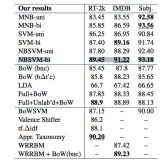
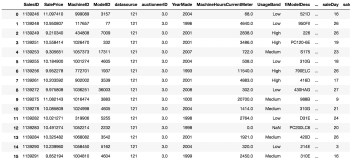
强化学习是对英文Reinforced Learning的中文翻译,它的另一个中文名称是“增强学习”。相对于有监督学习和无监督学习,强化学习是一个相对独特的分支;前两者偏向于对数据的静态分析,后者倾向于在动态环境中寻找合理的行为决策。
强化学习的行为主体是一个在某种环境中独立运行的Agent(可以理解为“机器人”), 其可以通过训练获得在该环境中的最佳行为模式。强化学习被看成是最接近人工智能的一个机器学习领域。
思考:为什么说强化学习是最接近人工智能的一个机器学习领域?
1. 五个要素
强化学习的场景由两个对象构成,它们是:
- 智能代理(Agent):是可以采取一系列行动以达到某种目标的控制器,可以形象的将其理解为机器人大脑。比如自动驾驶的控制器、打败李世石的AlphaGo。
- 环境(Environment):是Agent所能感知和控制的世界模型。对自动驾驶来说,Environment就是Agent所能感知到的路况和车本身的形式- 能力,对AlphaGo来说,Environment包括棋盘上的每种状态和行棋规则。
这两个对象其实定义了机器人和其所能感知到的世界。而就像人类能在自己的世界中行走、享受阳光,机器人也可以通过三种方式与其所在的环境交互:
- 状态(State):是任意一个静态时刻Agent能感知到的Environment情况,相当于某一时刻人类五官能感知到的一切。
- 行为(Action):是Agent能在Environment中执行的行为,对应于人类四肢所能做的所有事。
- 反馈(Reward):是Agent执行某个/某些Action后获得的结果。Reward可以是正向的或者是负向的,相当于人类感受到的酸甜苦辣。
以上五种强化学习要素的关系如图1-12所示,它们在一起构建起了强化学习的应用场景。

图1-12 强化学习场景
另外,在强化学习中Reward有时是延时获得的。即Agent在做出某个Action后不会马上获得Reward,而需要在一系列Action之后才能获得。每个任务最终获的Reward被称为value。比如在围棋环境中,只有结果是胜是败才对之前的所有Action给出最终的value。
延迟获得value的本质分析的是一系列相关行为共同发生的作用,也是强化学习与有监督学习最主要的一个不同点。试想如果每一个Action都可以获得一个相应的Reward,那么Reward就退化成了有监督学习中的label(标签)。
2. 两种场景与算法
具备上述五个要素的强化学习可以用来解决两类问题:
- 状态预测问题:用马尔可夫过程估计在任一时刻各种状态发生的可能性,其中蒙特卡洛模拟(Monte Carlo Method)是一类重要方法。
- 控制问题:如何控制Agent以获得最大Reward。其算法可以分成两类:
- 基于策略的学习(Policy-based):基于概率分布学习行为的可能性,根据可能性选择执行的动作,可学习连续值或离散值类型行为。典型算法是Policy Gradients。
- 基于价值学习(Value-based):直接基于Reward学习行为结果,只能学习离散类型行为,包括算法Q-learning、Sarsa。
另外,还有个别算法兼具Policy-Based和Value-Based特点,比如Actor-Critic。
不得不承认的是,虽然强化学习是更智能的机器学习分支,但目前产品级应用还比较少,多集中在游戏娱乐和简单工业控制。本书将在第6章介绍隐马尔可夫模型,第7章介绍以马尔可夫收敛定理为基础的蒙特卡洛推理,在第10章详细学习各类强化学习控制问题。
从机器学习,到深度学习
从深度学习,到强化学习
从强化学习,到深度强化学习
从优化模型,到模型的迁移学习
一本书搞定!