热门
万字长文:一文彻底搞懂Elasticsearch中Geo数据类型查询、聚合、排序
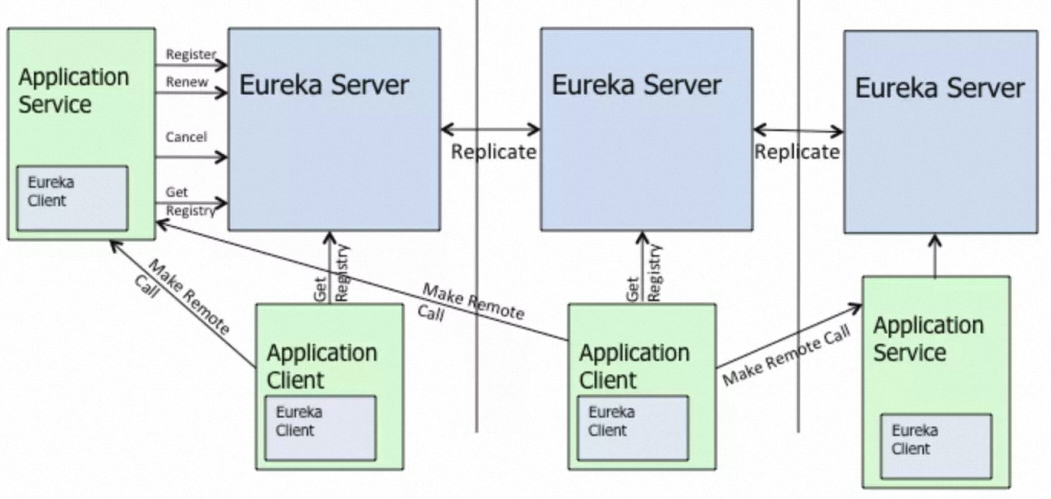
上一任留下的 Eureka,我该如何提升她的性能和稳定性(含数据比对)?
蚂蚁流场景状态演进和优化
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
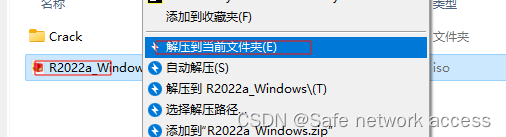
数学建模-Matlab R2022a安装步骤
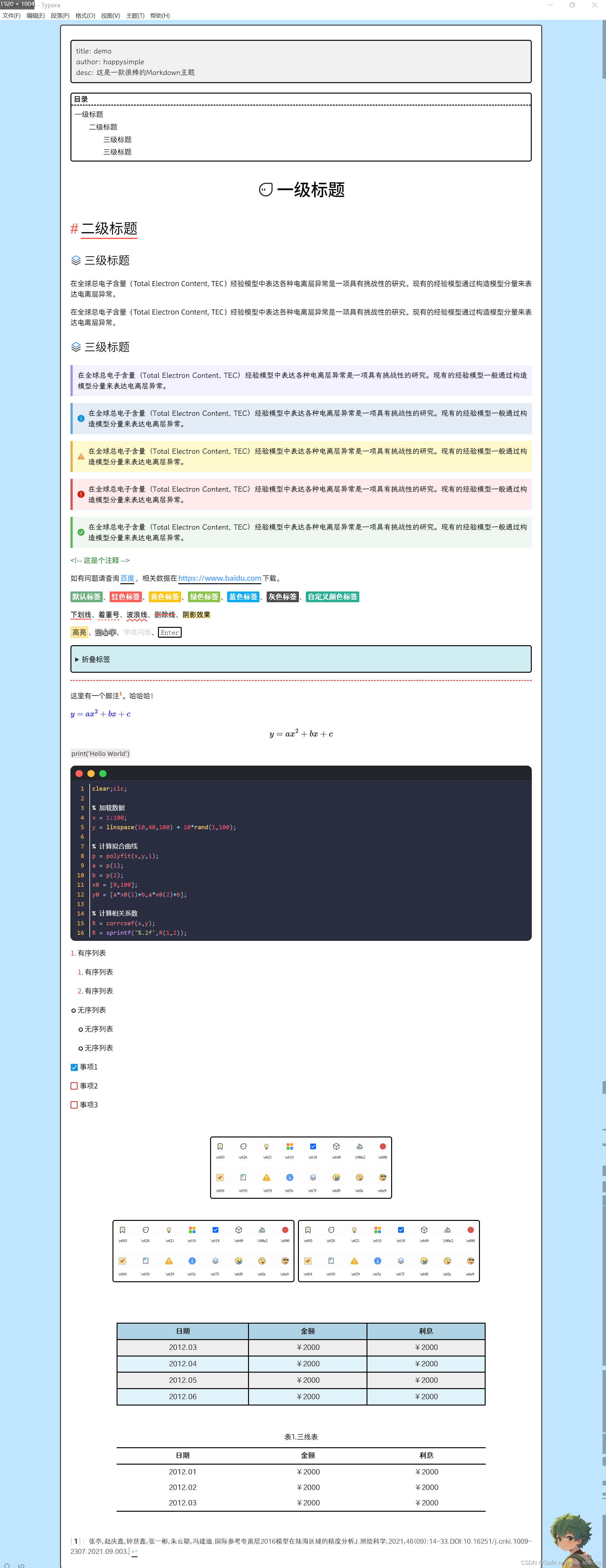
Typora更换主题Happysimple
01.Typora1.7.6安装以及更换主题方法
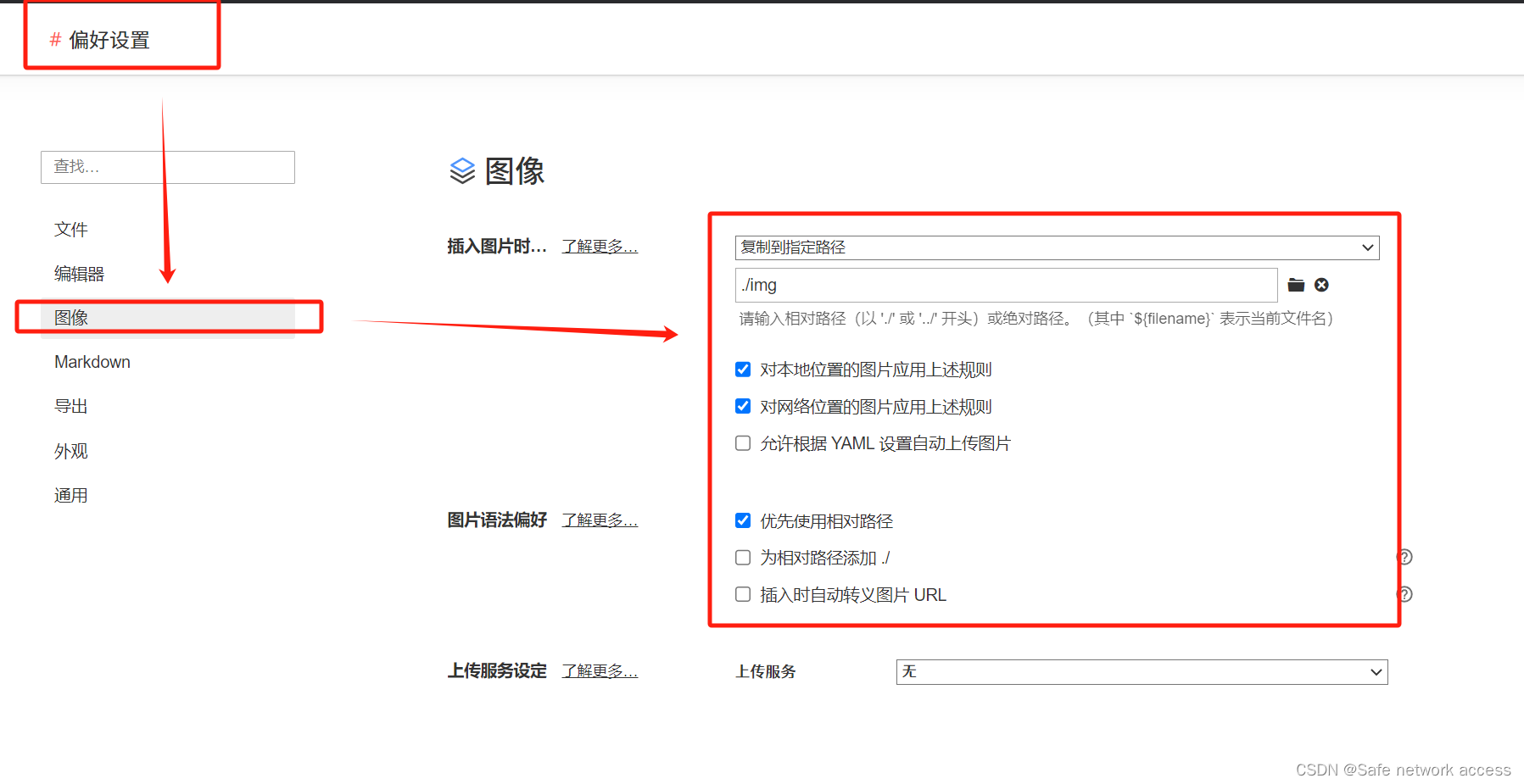
Typora设置 “图片自动保存到文档对应目录下” 的方法(亲测有效)
1.1计算机和编成语言
1.1 计算机硬件基础知识
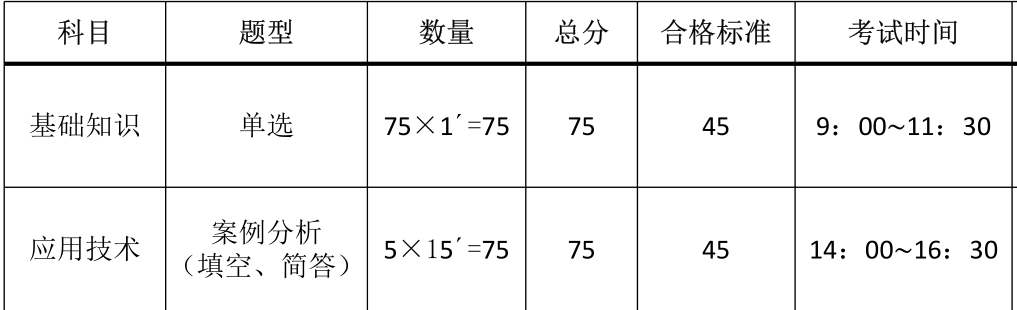
0.考试介绍
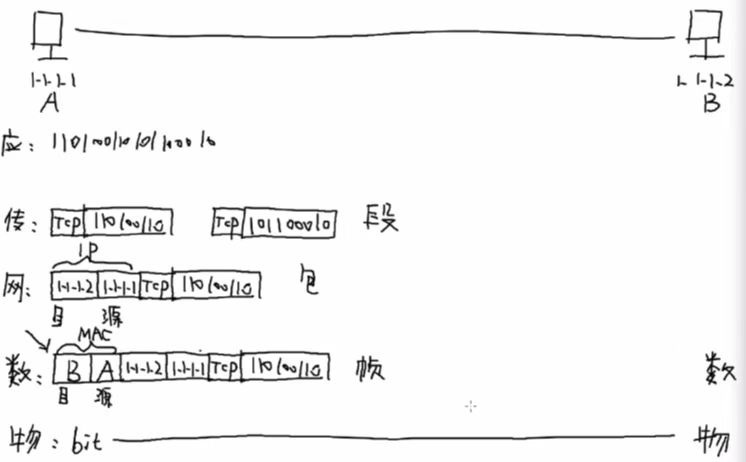
2.H3CNE-网络参考模型
1.H3CNE-计算机网络概述
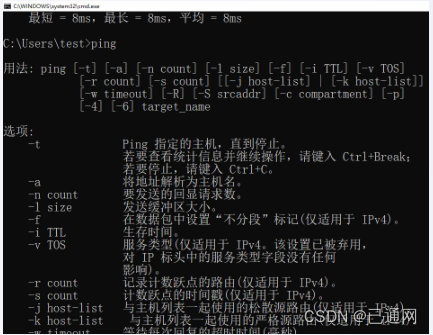
新华三命令行基础
HCL(新华三模拟器)如何连接CRT及改界面颜色
CRT的安装步骤。学不会来打我
19.系统知识-数字证书
18.系统知识-Linux常用命令
17.AD域和LDAP协议
16.系统知识-Windows的常用命令
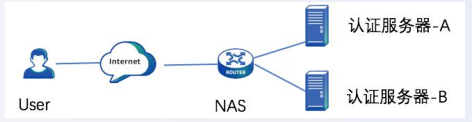
15.网络协议-Radius协议
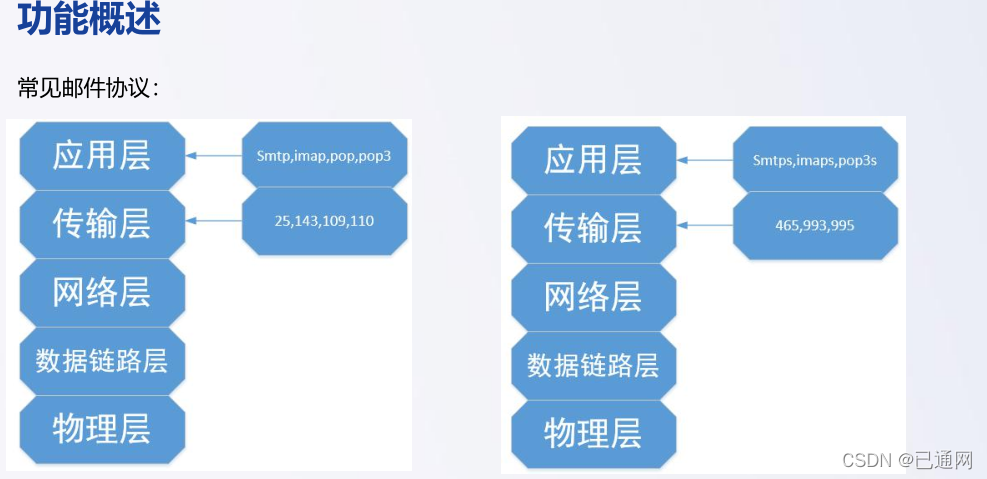
14.网络协议-邮件协议
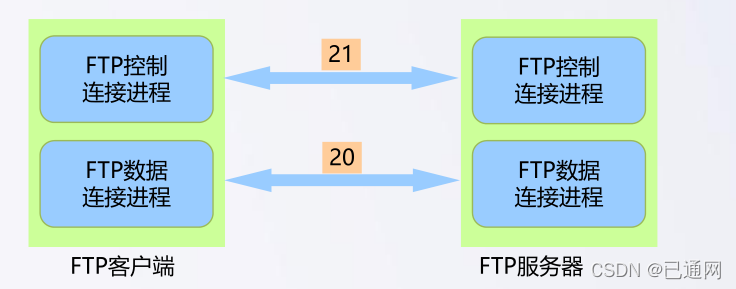
13.网络协议-FTP协议
IPv6实验
DHCP中继实验
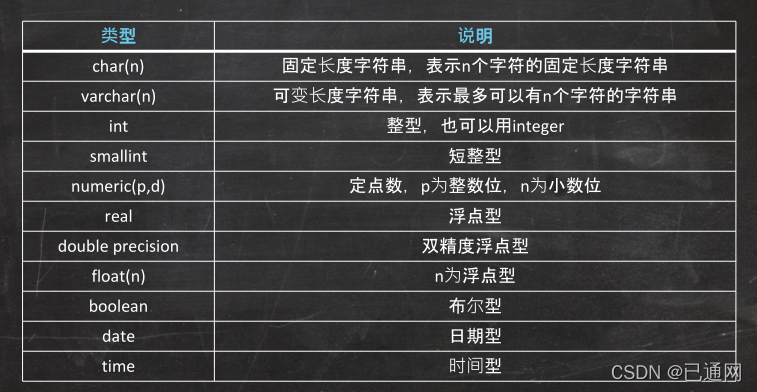
8.1SQL概述与数据库定义
7.6Armstrong公理系统
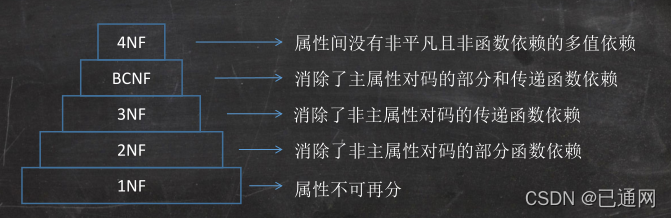
7.5规范化
7.4关系数据库设计基础知识
6.数据库技术基础
7.2 关系运算
7.1关系数据库概述
SE-Hybrid 实验
H3CNE题库(带答案版)
OSPF 实验
RIP实验
训练shell常用脚本练习(三)
深度学习赋能智能监控:图像识别技术的革新与应用
【C++成长记】C++入门 | 类和对象(下) |Static成员、 友元
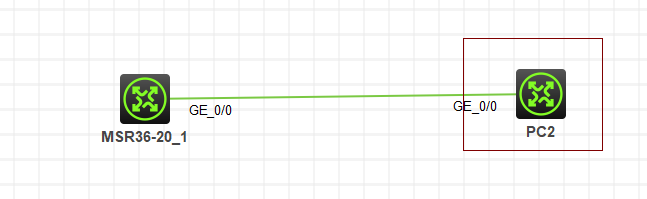
静态路由实验
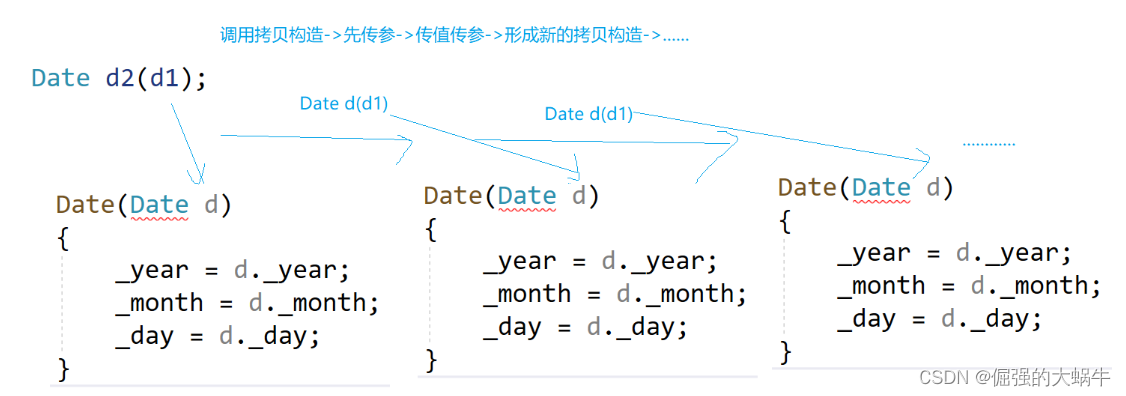
【C++成长记】C++入门 | 类和对象(中) |拷贝构造函数、赋值运算符重载、const成员函数、 取地址及const取地址操作符重载
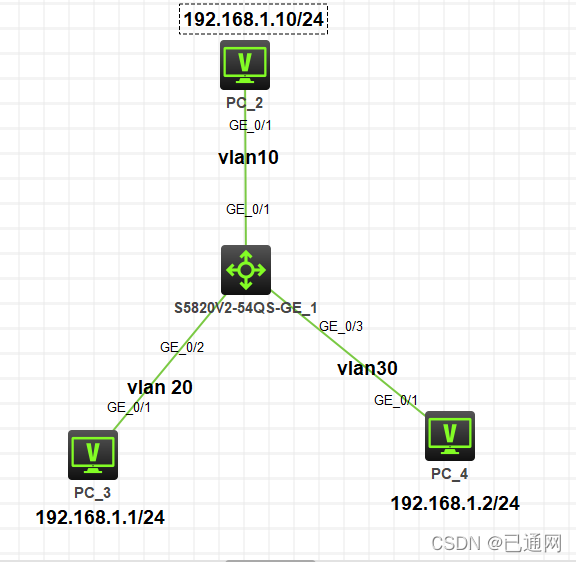
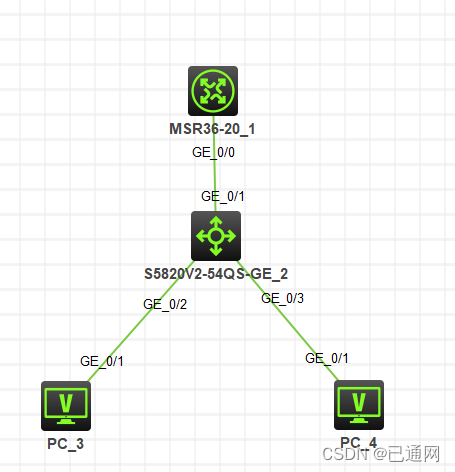
三层交换实验
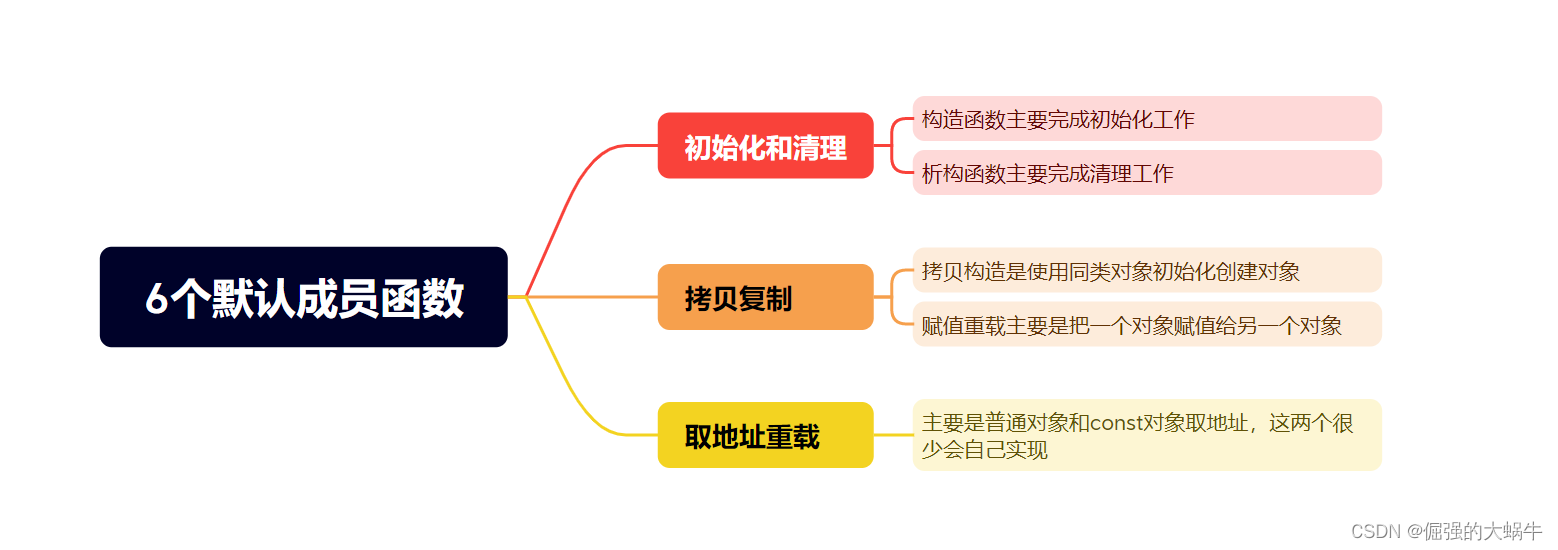
【C++成长记】C++入门 | 类和对象(中) |类的6个默认成员函数、构造函数、析构函数
单臂路由实验
Python中的os模块
DHCP实验-动态主机配置协议
浅谈顺序表基本操作