上一篇已经介绍过Cassandra数据库的编译以及安装,本篇开始介绍Cassandra数据库的配置文件里的基本配置项,这些基本配置项会影响数据库的启动,以及数据库的运行性能,这边会分基本配置 和 调优配置进行分别介绍。
所有的配置都在cassandra的安装目录下面的conf里,conf目录下面有cassandra.yaml这个文件,所有的配置都可以通过修改这个文件而达到目的;
基本配置
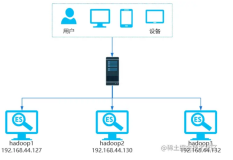
比较关键的几个配置有:cluster name,partitioner,snitch,以及seed nodes的配置。如上图,我们知道一个cassandra的集群是由多个节点组成的,每一个节点可以一个物理机,虚拟机,或者是一个进程等等,由这些节点组成了cassandra的集群。那么这个集群中的各个节点的cassandra.yaml里的cluster name,partitoner,snitch都至少需要保持一致才可以,seed nodes 虽然不强制需要保持一致,但是建议最好是一致的,而且我们生产环境也是保持一致的。
| 配置项名字 | 配置项解释 | 默认值 | 建议值 |
|---|---|---|---|
| cluster_name | 集群的名字,在逻辑上隔离各个集群 | Test Cluster | 可以区别集群的唯一名称 |
| num_tokens | vnode的使用方式,集群中的这个配置节点将会被分配的token的数量,如果这个token数量越多,那么这个节点将会存储更多的数据,如果集群的各个节点的硬件配置一样,那么建议该配置token数量都一致。如果这个配置项没有被配置的话,cassandra将会给这个节点分配默认的1个token,token的值由initial_token的配置确定。 | 256(默认配置) | 256 |
| initial_token | 非vnode使用方式,需要人工基于partitioner计算赋值,比如:如果是使用RandomPartitioner,那么就需要计算md5值,4个节点的话,每个节点的md5 token值,建议均分0-2^128 -1 这个区间 | 无 | 无 |
| seed_provider | seeds: 各个ip之间用,进行连接,seed 是可以选择集群中的某个或者某几个节点进行配置,所有的集群种的节点都会先和seed节点沟通,获取集群状态 | 需要基于集群ip做配置 | |
| partitioner | partitioner的意思就是允许你的partition key以何种方式在集群种放置,放置到哪个节点,而方式的方式会结合上面的num_tokens或者initial_token的配置来查找;也就是集群配置了RandomPartitioner的放置策略,然后一条记录在集群中会以md5方式进行计算其归属的节点,然后到对应节点进行读写 | org.apache.cassandra.dht.Murmur3Partitioner | 见下表 |
| endpoint_snitch | snitch的作用是:让cassandra知道你的网络拓扑;让cassandra可以放置副本:把机器归类为datacenter以及rack | SimpleSnitch | 见下面表 |
| listen_address | 本节点需要绑定的ip,这里address和下面的interface只能选一个去设置 | InetAddress.getLocalHost()函数获取的ip | |
| listen_interface | 网卡接口 | ||
| native_transport_port | cql绑定的端口 | 9042 | |
| rpc_address | cql的服务绑定的ip | 同listen_address | |
| storage_port | 内部节点间进行通信的端口,比如gossip协议 | 7000 | |
| ssl_storage_port | 与上述端口只能存一个,如果是在公网环境下建议用这个端口 | 7001 | |
| 数据存储相关 | |||
| data_file_directories | -存储数据的目录,如果是挂了多块磁盘的话,各个磁盘路径前加- ; | cassandra_home的目录下默认建data目录 | 基于自己的挂盘情况设置 |
| commitlog_directory | Commit log的配置目录,也就是wal 的目录,如果是hdd盘,建议与data目录分开 | cassandra_home下的data目录下的commitlog目录 | |
| disk_failure_policy | data disk failure的策略,当data数据盘出现磁盘故障的时候,我们的cassandra应该怎么做 | stop | 见下表 |
| commit_failure_policy | 当commitlog数据盘出现磁盘故障的时候,我们的cassandra应该怎么做 | stop | 见下表 |
Partitioner
| Partitioner名称 | 意义 |
|---|---|
| org.apache.cassandra.dht.Murmur3Partitioner | 使用murmur的hash算法进行值的计算具体算法含义可以自行谷歌 |
| org.apache.cassandra.dht.RandomPartitioner | 计算md5 的hash;Murmur3Partitioner比RandomPartitioner计算hash会快很多。 |
| org.apache.cassandra.dht.ByteOrderedPartitioner | 把key以原生的byte存储和下面的string 是大体一类,计算key性能比下面好一点点 |
| org.apache.cassandra.dht.OrderPreservingPartitioner | 所有的key的hash计算就是计算成一个UTF-8的字符串,但是这种方式只是可以提供较好的key排序操作。但是会造成一些key的倾斜,比如某些node的key存储量比别的node多; |
endpoint_snitch
| Snitch名称 | 意义 |
|---|---|
| SimpleSnitch | 没有机架感知的一种snitch,在多dc的环境下不适合部署,选择这种方式的话,那么副本策略:replication strategy 应该选择SimpleStrategy |
| GossipingPropertyFileSnitch | yaml里面写的是建议在生产环境部署的,本节点的dc以及rack信息在cassandra-rackdc.properties配置,别的节点可以通过gossip获取得到该节点的dc rack信息,这是一种机架感知的snitch,这里是只需要配置自己的节点信息 |
| PropertyFileSnitch | 一种机架感知snitch之一,需要在cassandra-rackdc.properties配置上所有的ip对应的机架 dc等信息;如果不配置就是认为是默认的dc1,rac1,一般副本策略建议是NetworkTopology Strategy |
| RackInferringSnitch | 认为使用这种snitch的都是在一直的网络环境中,主要是通过ip的二进制分组做比较,如果2个ip的第二个8bit的组的数字是一样的就认为是在一个dc下面,如果是第三个8bit组是一样的就认为是一个机架上。 |
| Ec2MultiRegionSnitch | 用于在公网环境下的多region下的snitch,这时候需要为公网环境下的端口开防火墙 |
| Ec2Snitch | 适用于aws的ec2的部署,在一个region下,region以及az的信息是通过ec2的api获取的,region被当做dc,az当做机架; |
failure_policy
| failure policy名称 | disk_failure_policy意义 | commit_failure_policy意义 |
|---|---|---|
| die | 当出现文件系统error或者单个sstable的error的实时,停止gossip交互client的请求以及kill jvm | 停止节点进程,kill jvm |
| stop_paranoid | 单个sstable出现error的时候,会停掉gossip交互,以及拒绝client请求;如果是启动的时候,会kill jvm | 无此配置 |
| stop | 如果出现fs问题的时候会停掉gossip交互以及拒绝client请求,但是节点可以接收jmx的观测;启动的时候出现error则会kill jvm | 停掉节点,但是节点可以接收jmx的观测 |
| best_effort | 暂停使用出现问题的磁盘,且尽可能的返回数据给用户,这就表明可能会出现造成读到过期数据,比如使用ONE这个一致性的时候 | 无此配置 |
| ignore | 忽略文件系统或者磁盘故障,让请求失败 | 忽略error,让comit 失败 |
| stop_commit | 让commit log操作失败,但是依旧提供读 |
注意
- 如果num_tokens不配置,而选择initial_token的话,需要手工的基于partitioner的规则去计算各个节点的inital_token值,这样的好处是可以人工控制各个节点的管理token范围,但是集群的各个节点建议均分所有的token存储范围,且扩容的时候建议成倍的扩容;num_tokens的好处是不需要手工计算和配置,缺点是每个token是随机计算的,实际上各个节点负责的这些token以及对应范围是不可控;
-
上面说了snitch 应该配合副本放置策略进行配合,这个放置规则主要是在建keyspace的时候设置的,这里我们简单的介绍写副本放置策略,也就是一个表他在集群中如果设置了多副本,比如3副本的话,这3个副本应该是怎么样的放置规则呢?在建表的时候比如如下语句
CREATE KEYSPACE test_keyspace WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '3'}
class可以有SimpleStrategy和NetworkTopologyStrategy,其中SimpleStrategy意思是:test_keyspace的副本的放置是在一个dc内部,摆放的规则是简单策略,一般是按照node的ip adress的顺序摆放;NetworkTopologyStrategy:副本会穿过多个dc进行摆放,详细的规则后续会介绍;
- Replication Factor:这是上面一条提到的副本因子,主要是表示副本数,也是在建表的时候会设置;
下一篇会介绍一些其他的配置,主要是和性能调优cassandra数据库相关的;比如cache的配置等;完事以后会介绍如果建表以及使用datastax的java-driver访问数据以及对应的数据模型;等等
欢迎加入我们的微信群:
钉钉群: