热门
一文解读:阿里云AI基础设施的演进与挑战
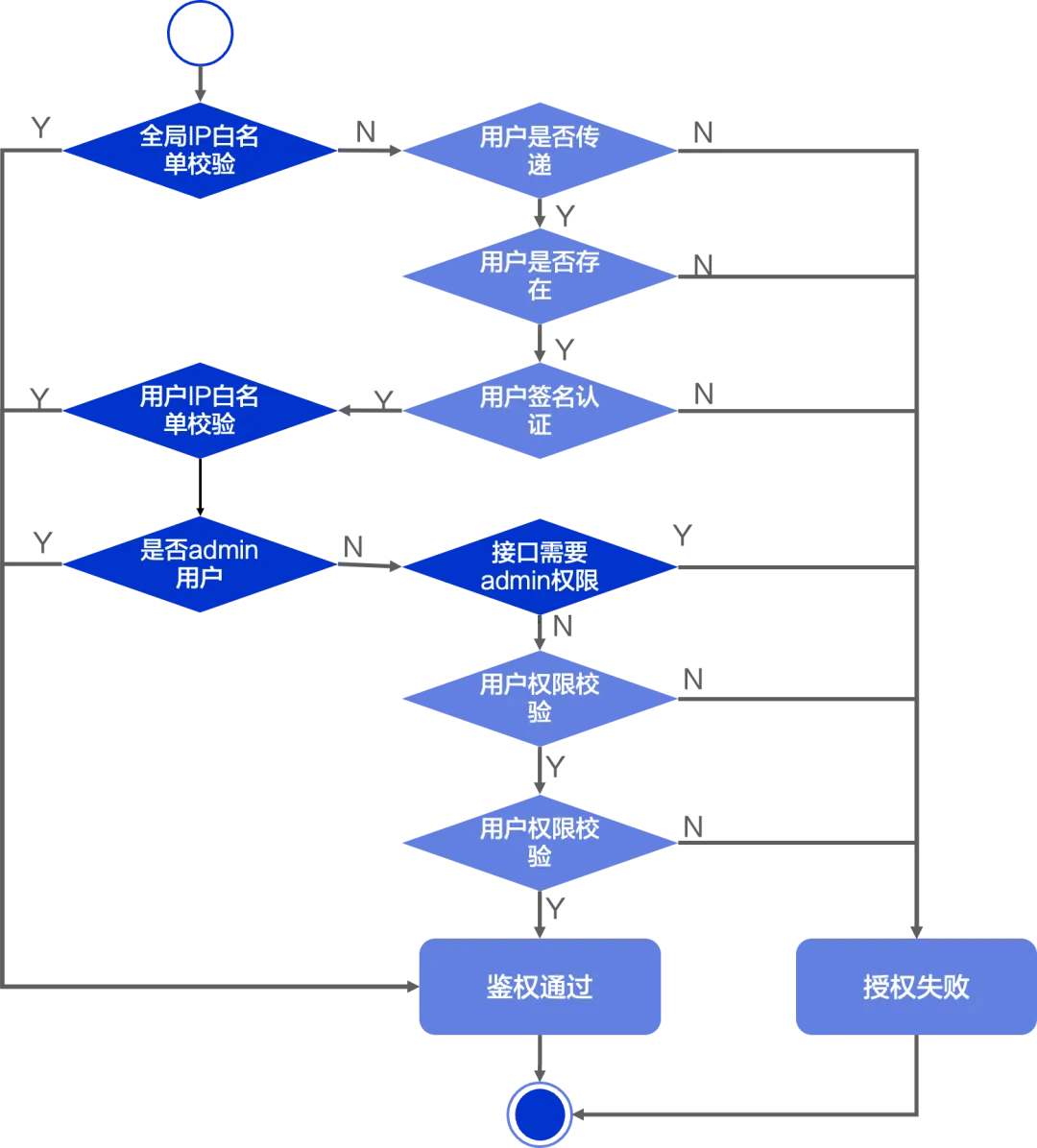
Apache RocketMQ ACL 2.0 全新升级
5月更文挑战赛火热启动,坚持热爱坚持创作!
案例分析|线程池相关故障梳理&总结
给技术新人的ODPS优化建议
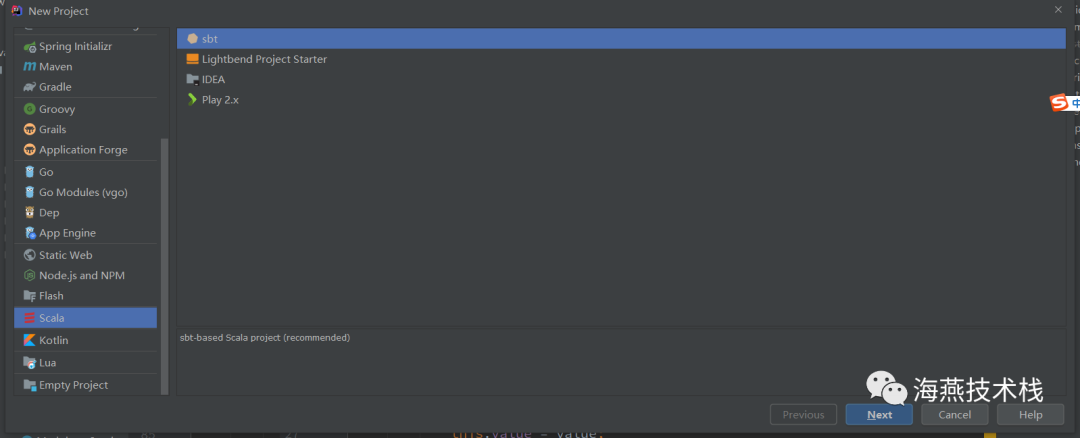
运行第一个scala程序
平衡二叉树的插入和删除(从现在开始摆脱旋转)
二叉树---前,中,后序遍历做题技巧(前,中,后,层次,线索二叉树)
软考之业务处理系统的特点
构建高效自动化运维系统:基于容器技术的持续集成与持续部署(CI/CD)实践
第五十八练 堆排序实现
Vue3.0监听器watch与watchEffect
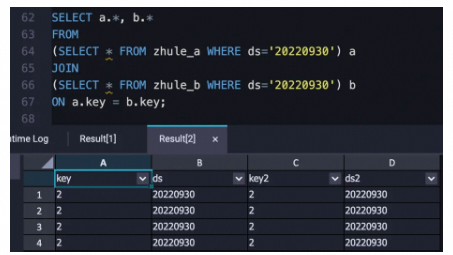
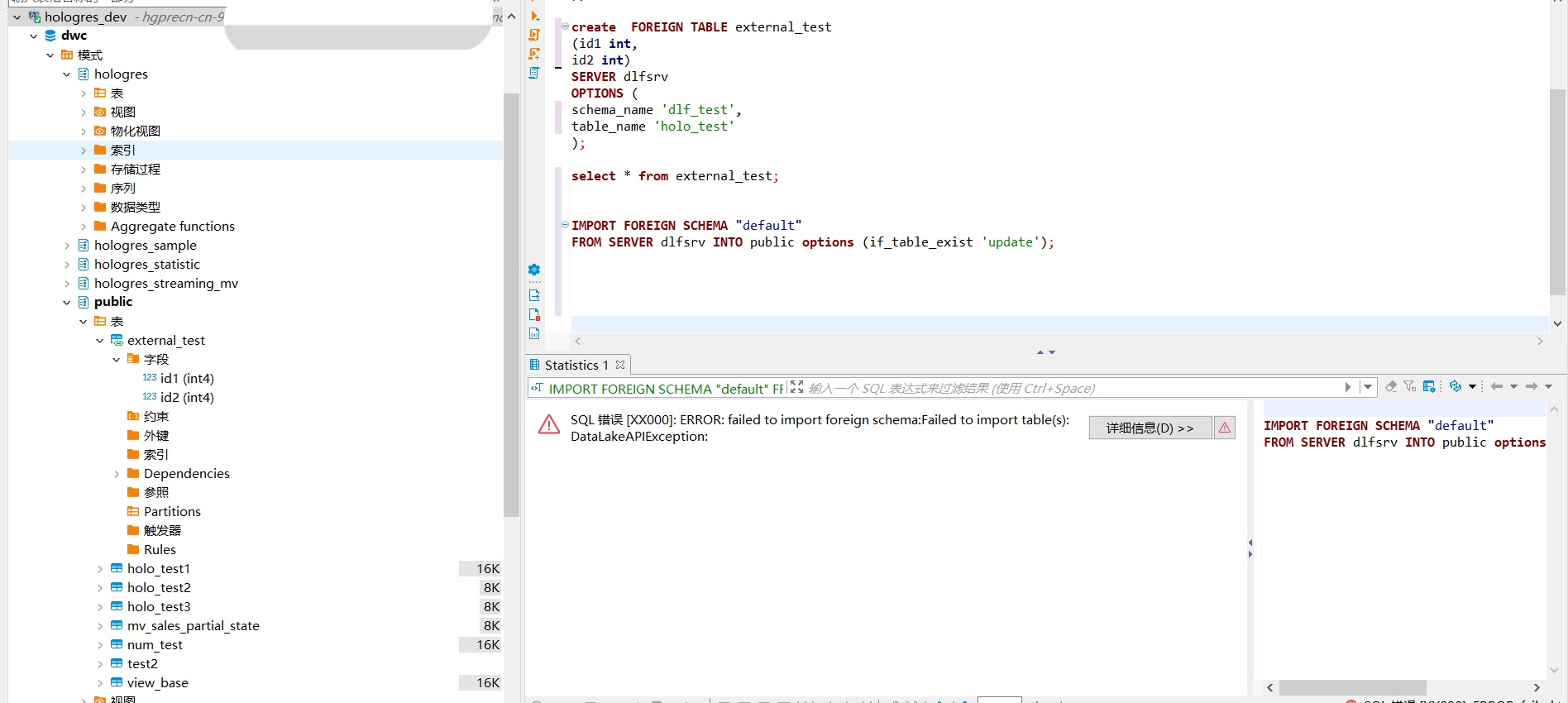
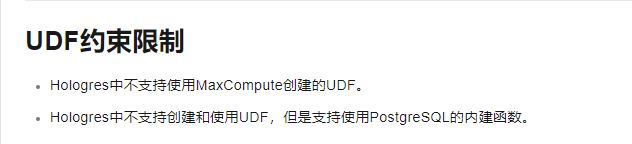
实时数仓 Hologres产品使用合集之可以直接接入接口吗
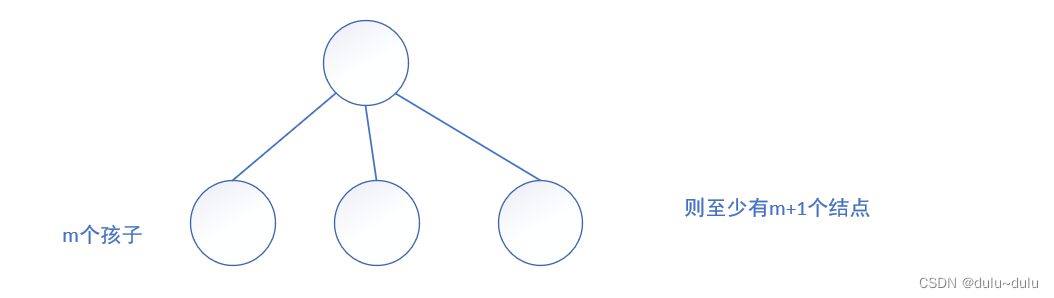
数据结构-----树的易错点
第五十七练 归并排序实现
Vue3中的Suspense组件有什么用?
数据结构---串(赋值,求子串,比较,定位)
第五十六练 基数排序实现
在CentOS上安装和配置Redis
实时数仓 Hologres产品使用合集之报错:ORCA failed to produce a plan : PlStmt Translation: Group by key is type of imprecise not supported如何解决
移动应用开发的未来:跨平台框架与原生系统协同进化
char *str,char &str,char *& str和char str的区别
构建未来应用:云原生技术在企业转型中的关键作用
Android应用性能优化实战
构建高效可靠的微服务架构:后端开发的现代实践
探索微服务架构下的服务治理策略
安装基于docker的php运行环境
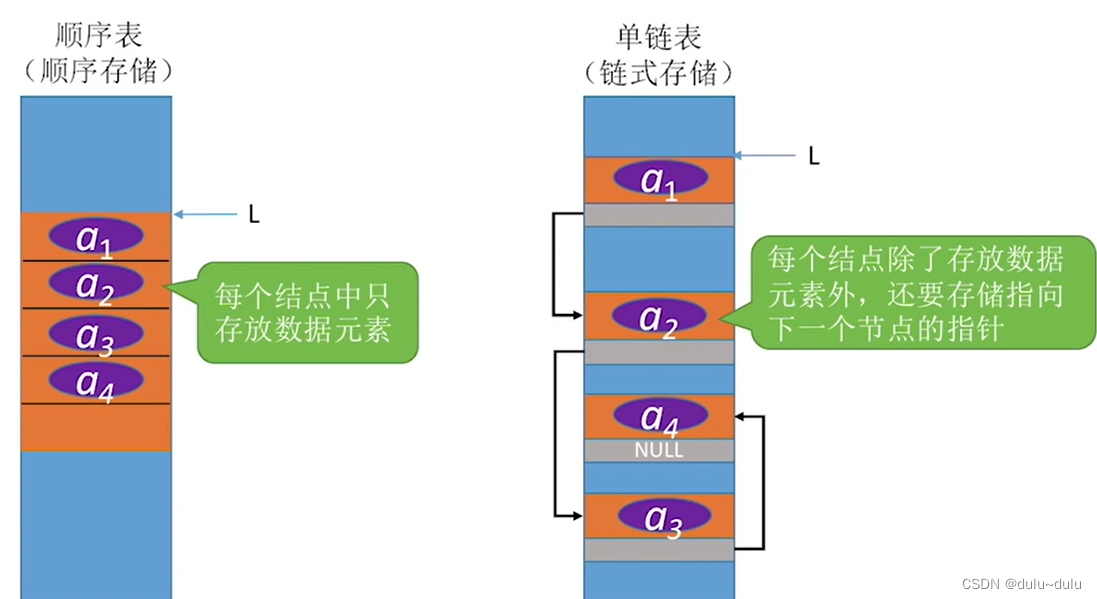
序表和链表的区别(通俗易懂)
特殊链表(循环单链表,循环双链表,静态链表)
实时数仓 Hologres产品使用合集之在执行SQL语句时,在插入语句后面直接跟上了insert,insert操作就会报错如何解决
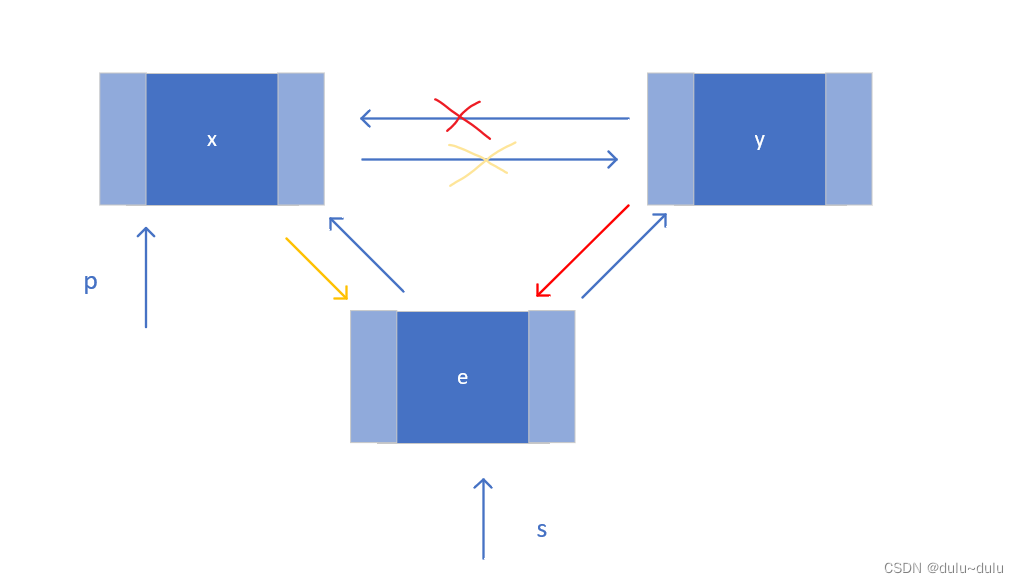
双链表的插入,删除以及遍历
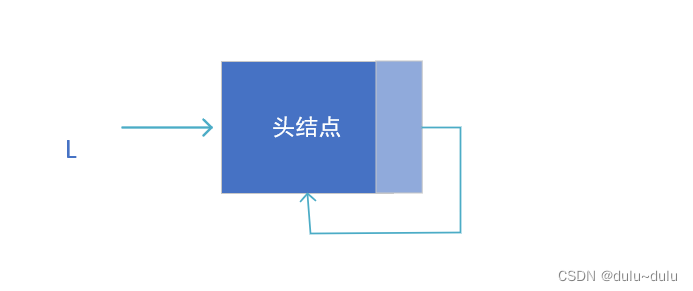
单链表相关操作(头插法和尾插法)
实时数仓 Hologres产品使用合集之ologres holostudio为什么不支持max_pt('table')取最大分区这个方法
单链表相关操作(插入,删除,查找)
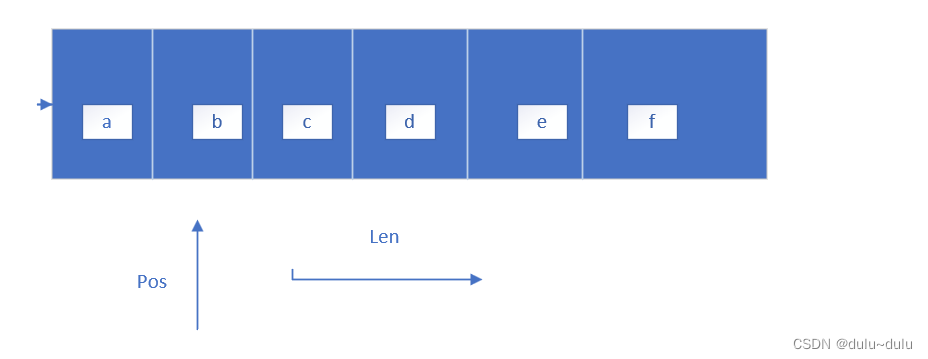
顺序表的插入,删除,修改和查找(详细解析)
实时数仓 Hologres产品使用合集之建表字符串默认都是bitmap索引,如果字符串的是高基数的,会不会有影响
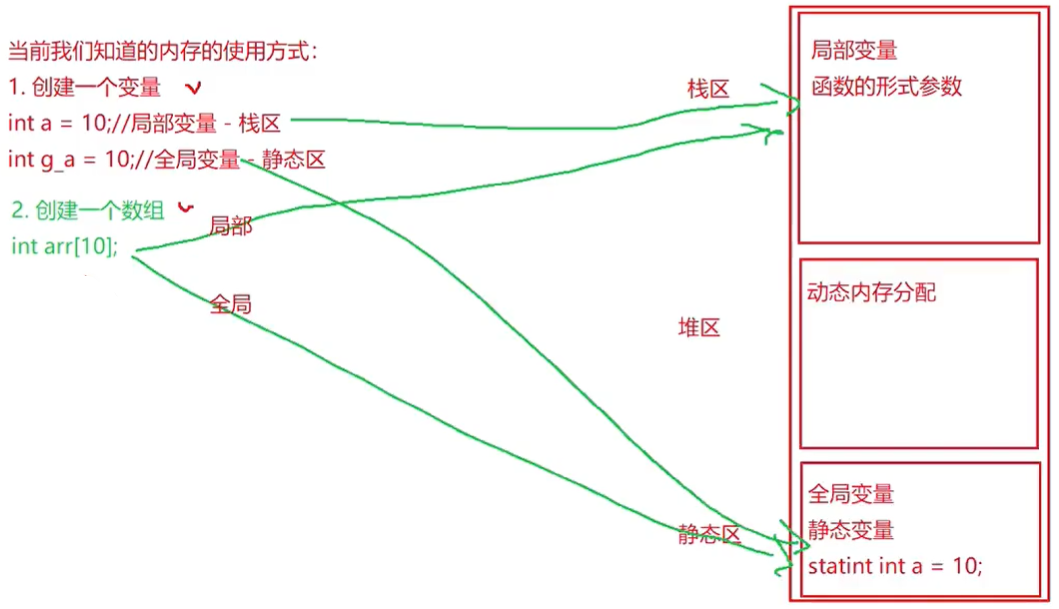
C语言----动态内存分配(malloc calloc relloc free)超全知识点
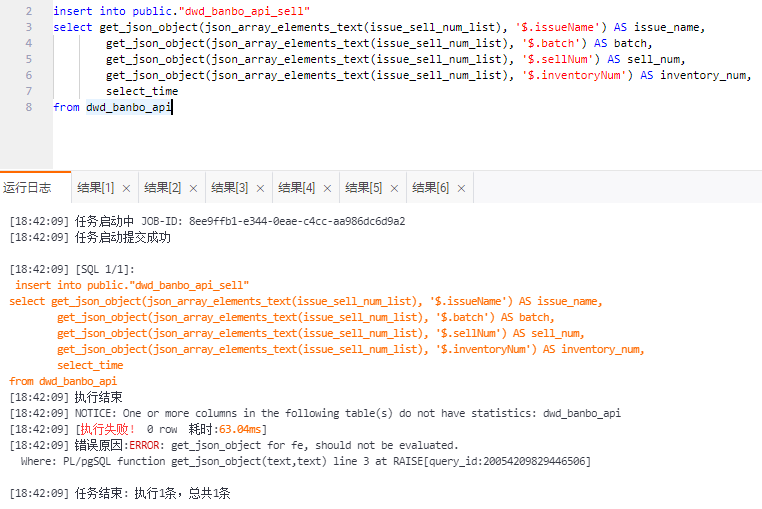
实时数仓 Hologres产品使用合集之查询数据的入库时间该怎么操作
结构体,枚举,联合大小的计算规则
基于肤色模型的人脸识别FPGA实现,包含tb测试文件和MATLAB辅助验证
Angular 视图数据模型变化导致重新计算模板中的表达式的技术原理
实时数仓 Hologres产品使用合集之有没有MySQL那样的AUTOINCREMENT字段来实现自增ID功能
Angular 中的结构指令运行时的工作原理
指针习题笔记(较难,可用于思维锻炼)
SAP 产品 data archive 数据归档的重要性
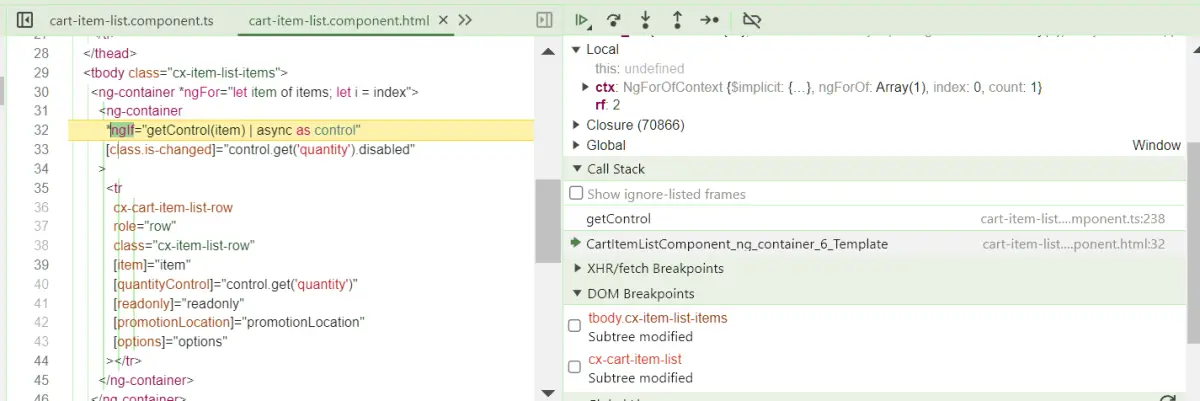
关于 Angular template 文件在 Chrome 开发者工具调试器里的断点问题
SAP S4HANA 数据归档的实施方法
什么是 SAP Commerce Cloud SmartEdit Product Carousel Component Editor