Redis集群管理
1.简介
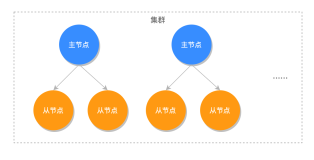
Redis在生产环境中一般是通过集群的方式进行运行,Redis集群包括主从复制集群和数据分片集群两种类型。
*主从复制集群提供高可用性,而数据分片集群提供负载均衡。
*数据分片集群中能实现主从复制集群的功能。
2.Redis主从复制集群
主从复制集群中由Master节点提供读写服务,Slave节点负责同步Master节点中的数据,当Master节点发生故障时,由Slave节点充当Master对外提供服务。
主从复制集群中可以使用一主一从模式,亦可以使用一主多从模式,在一主多从模式中主节点需要将修改同步给各个从节点从而增加了主节点的压力(带宽)
*在主从复制集群中Slave节点能够进行读取(不建议),但如果没有开启TCP的NO_DELAY功能,那么读取的数据可能是脏数据,在Slave节点进行写入时,会提示Slave节点不能进行写入。
关于读写分离
应用对于数据库而言都是读多写少的,即数据库的读取压力要比写入的压力大(即100个请求95个都是读的),由于受数据库自身性能影响,因此一般都会搭建主从数据库,由多个从数据库提供读取服务,分担压力,实现读写分离。
读写分离是相对于有磁盘IO操作的数据库而言的,对于基于内存的NoSQL来说不存在此问题,其读取和写入的性能都很快,每秒能处理几万个请求,因此没有必要进行读写分离,Redis中应用主从复制集群是为了保障集群的高可用性,当Master节点发生故障时,由Slave节点充当Master对外提供服务。
主从数据库实现读写分离的根本原因是数据库自身性能低下。
2.1 搭建主从复制集群
Slave节点同步Master节点中的数据
slaveof
Slave节点修改为只读模式
slave-read-only=yes
*当Master节点启动后再启动所有的Slave节点。
*当主从复制集群搭建后可以通过info replication命令查看集群间的信息。
2.2 主从复制集群中的数据同步
主从复制集群中的数据同步使用PSYNC命令进行完成,PSYNC命令包含全量复制以及部分复制。
1.全量复制:首次加入集群的Slave节点会同步Master节点中的所有数据。
2.部分复制:再次与Master节点建立连接的Slave节点同步Master节点中的部分数据。
*Redis提供了repl-disable-tcp-nodelay命令,表示是否启用TCP的NO_DELAY功能,当该命令为yes时,表示禁用TCP的NO_DELAY功能,那么Master节点在同步修改给各个Slave节点时会合并小的TCP包从而节省带宽,但此方式会增加同步延时(40ms左右),造成主从数据不一致的问题。当该命令为no时,表示启用TCP的NO_DELAY功能,那么Master节点会实时同步修改给各个Slave节点。
2.3 主从复制集群中的故障转移
当Master节点发生故障时,可以通过手动或者自动的方式进行故障转移
手动故障转移
1.将其中一个Slave节点断开与Master节点的连接,并使其成为新的Master节点。
2.将其他的Slave节点与该新的Master节点建立连接。
3.修改各个节点的redis.conf配置文件,更新主从映射关系,保证下次重启时使用最新的主从关系启动,避免主从数据不一致问题。
Slave节点断开与Master节点的连接
slaveof no one
自动故障转移(哨兵机制)
Redis中提供了Sentinel哨兵机制,由多个哨兵组成一个哨兵集群,负责保障Redis集群的高可用性,当Master节点发生故障时,自动的将其中一个Slave节点断开与Master节点的连接并使其成为新的Master节点,并将其他的Slave节点与新的Master节点建立连接,最后修改各个节点的redis.conf配置文件,更新主从映射关系。
1.每个哨兵节点每隔10s会向Master发送info replication命令,获取当前集群最新的拓扑结构,此时每个哨兵就能获取到各个Slave的连接信息。
2.每个哨兵每隔1s会向集群中的Master和各个Slave节点发送心跳,根据心跳来判断节点是否存活,若在一定时间段内节点没有回复,那么该哨兵认为该节点已经故障了。
3.每个哨兵每隔2s会向Redis中的指定频道发布其对Master节点的判断,同时每个哨兵会订阅该频道,因此每个哨兵都能知道其他哨兵对Master节点的判断。
4.当其中一个哨兵发现Master节点故障后,会查看其他哨兵对Master节点的判断,若超过指定个数个哨兵都认为该节点故障,那么由该哨兵充当哨兵集群的Leader进行故障转移,故障转移的步骤与手动转移的一致,挑选其中一个Slave节点断开与Master节点的连接,并使其成为新的Master节点,然后其他Slave节点与该新的Master节点建立联系,最后修改各个节点的redis.conf配置文件,更新主从映射关系,保证当集群重启时以最新的主从映射关系运行,避免主从数据不一致的问题。
在Redis的源码目录中存在sentinal.conf配置文件,该文件是哨兵的配置文件。
复制代码
监听Master节点的信息
sentinel monitor
*其中quorum表示当哨兵集群中有quorum个哨兵都认为Master节点不可用时则哨兵集群认为该节点已经故障.
心跳超时时间
sentinel down-after-milliseconds
故障转移超时时间
sentinel failover-timeout
允许同时有多少个从节点同步新节点的数据
sentinel parallel-syncs
复制代码
*一个哨兵集群可以监控多个Redis主从复制集群。
分别启动Redis各个节点,然后通过redis-sentinel分别启动各个哨兵,由于每个哨兵都关联同一个Master,因此这多个哨兵自动成为集群关系。
*在主从复制集群中,一般都会使用自动故障转移方案(哨兵机制)
3.Redis数据分片集群
Redis在3.0版本后推出了RedisCluster用于搭建数据分片集群。
*其中每个Master节点负责指定槽范围内的数据,并提供读写服务,Slave节点只负责同步Master节点中的数据,不支持进行读取。
*使用RedisCluster时,Master节点的个数至少需要三个,每个Master可以有任意个Slave节点。
*RedisCluster使用虚拟槽的方式进行数据分片,Redis中虚拟槽的范围为0~16383(共16384个槽),每个Master节点负责指定范围的槽。
*所有Key在进行读取和写入操作时,都需要根据H(K) = CRC16[K] & 16383散列函数计算出Key所坐落的槽,然后找到其对应处理的Master节点,最后自动跳转到该节点进行操作。
由于使用了RedisCluster,数据将分散到各个节点中,因此有些操作是不允许的
1.涉及多个Key的操作,比如mset、sinter等。
2.事务不能跨节点。
3.不支持多数据库,每个Master节点只能有一个数据库。
关于数据分片的路由策略
数据分片的路由策略一般有三种,分别是除留余数法、一致性Hash、虚拟槽,RedisCluster使用虚拟槽的方式实现数据分片。
除留余数法:以元素被某个整数M整除后所得到的余数找对其对应处理的节点( H(K) = K % M,M等于节点的个数)
*当增加或减少节点时,数据的路由将发生变化,伸缩性很差。
一致性Hash:以元素通过某个散列函数H(K)所得到的散列值坐落在Hash环上的位置,找到其对应处理的节点。
1.首先将集群中的节点IP通过散列函数H(K)计算出散列值并使其坐落在Hash环上,每个节点负责Hash环上特定范围的请求。
2.将元素通过相同的散列函数H(K)计算出散列值,以该散列值坐落在Hash环上的位置找对其对应的处理节点。
*使用此方式很难保证客户端的请求平均分配到各个节点中,不能很好的实现负载均衡。
虚拟槽:以元素通过某个散列函数H(K)所得到的槽位,找到其对应处理的节点。
1.每个节点负责指定槽范围内的请求。
2.将元素通过散列函数H(K)计算出槽位,找到其对应处理的节点。
3.1 搭建数据分片集群
可以通过手动或者自动的方式搭建数据分片集群。
手动搭建数据分片集群
1.准备配置文件
复制代码
开启RedisCluster模式
cluster-enabled yes
RedisCluster集群配置文件,存放集群间节点的信息。
cluster-config-file nodes-6379.conf
节点超时时间(ms)
cluster-node-timeout 15000
复制代码
2.分别启动各个Redis节点
*当启动Redis节点后,会生成nodes.conf文件,该文件记录着集群间节点的关系(此时只有本节点信息)
*每个节点都有一个ClusterID,且角色默认都是Master。
3.握手(使各个节点建立关系)
*连接任意一个节点,然后分别对剩余的节点进行握手。
*当握手成功后,在node.conf文件中能看到集群间完整的节点信息。
4.分配槽
5.主从映射
*分别连接要作为Slave的节点,然后通过ClusterID与Master进行关联。
6.使用集群的模式连接RedisCluster
*其中cluster nodes命令能够查看集群间节点的信息,其读取的是node.conf文件中信息,cluster info命令能够查看集群的状态信息。
*当节点分配槽完成后,此时集群将处于上线状态,当集群中任意一个Master节点故障后,如果没有对应的Slave节点,那么集群将处于下线状态,当集群处于下线状态时,不能对外提供服务。
*当集群搭建完成后,可以进行关闭以及重启,当重启集群时,会自动读取node.conf文件中的信息恢复集群间的关系,并读取dump.rdb文件进行数据的恢复。
*当需要重新构建集群关系时,需要删除每个节点的node.conf以及rdb文件,否则集群搭建不成功。
*当使用集群的模式连接RedisCluster后,当进行读取和写入操作时,会通过H(K)散列函数计算出Key所在的槽,然后找到其对应处理的Master节点,最后自动跳转到该节点进行操作。
*不管是读取还是写入操作,都会统一跳转到对应处理的Master节点,slave-read-only=yes配置只适用于主从复制集群模式。
自动搭建数据分片集群
RedisCluster使用ruby来自动搭建数据分片集群。
1.环境准备
需要安装ruby,并且安装redis.gem
2.准备配置文件
复制代码
开启RedisCluster模式
cluster-enabled yes
RedisCluster集群配置文件,存放集群间节点的信息。
cluster-config-file nodes-6379.conf
节点超时时间(ms)
cluster-node-timeout 15000
复制代码
3.分别启动各个Redis节点
4.使用redis-trib.rb命令自动完成握手、分配槽、主从映射
redis-trib.rb create --replicas
*其中slaveNum为每个Master节点的Slave个数,可以为0。
*只能使用ip地址,不能使用主机名。
3.2 数据分片集群中的状态同步
RedisCluster是基于Gossip协议的PING/PONG通讯来保证数据分片集群中的数据一致性。
Gossip协议
Gossip协议主要用在分布式系统中各个节点的数据同步。
Gossip协议由种子节点发起请求(种子节点即状态发生改变的节点),当一个种子节点有状态需要更新到网络中的其他节点时,它会随机选择周围几个节点进行散播消息,收到消息的节点也会重复此过程,直至网络中的所有节点都收到消息,这个过程需要一定的时间,因此Gossip是一个最终一致性协议。
Gossip协议中提供了三种通讯类型:
1.PUSH类型:A节点将数据发送给B节点,B节点更新A节点比自己新的数据。
2.PULL类型:A节点将数据发送给B节点,B节点返回比A节点新的数据,A节点再更新自己。
3.PULL/PUSH类型:A节点将数据发送给B节点,B节点返回比A节点新的数据,A节点再更新自己,然后A节点将数据发送给B节点,B节点更新A节点比自己新的数据。
*PUSH类型发送一次请求,目的是让其他节点更新。
*PULL类型发送两次请求,目的是更新自身节点的信息。
*每个消息都有一个时间戳,用来区分新老信息。
RedisCluster中的PING/PONG通讯
PING:发送集群中节点的信息、角色、集群ID、时间戳。
PONG:响应PING的请求。
*PING请求即Gossip协议中的PUSH,目的是让其他节点进行更新。
RedisCluster中的每个节点都会定期的向其他节点发送PING请求(包括Slave节点),用于集群间状态的同步以及检测节点的可用性。
当集群中有新节点加入时(经过Meet操作),该节点会向其他节点发送PING请求,同时其他节点也会向其发送PING请求,最终达到数据一致性。
*RedisCluster中的节点故障是通过Master投票决定的,当有半数的Master认为该节点故障时,那么集群认为该节点故障,如果故障的节点是Master,那么会将其Slave节点切换为Master。
*当RedisCluster中有一半的Master同时失效,那么整个集群将不可用,因为已经没有足够的Master进行投票。
4.JAVA中使用Redis集群
4.1 使用主从复制集群
*Jedis中通过JedisSentinelPool实例来使用主从复制集群,连接主从复制集群中所有哨兵的地址,并指定哨兵配置文件中Master的名称。
复制代码
/**
- @Auther: ZHUANGHAOTANG
- @Date: 2019/4/2 17:11
- @Description:
*/
public class RedisUtils {
private static final String masterName = "mymaster";
private static JedisSentinelPool jedisSentinelPool = null;
static {
//连接主从复制集群中所有哨兵地址
Set<String> connectionMes = new HashSet<>();
connectionMes.add("192.168.2.90:26379");
connectionMes.add("192.168.2.91:26379");
connectionMes.add("192.168.2.92:26379");
//连接池配置
JedisPoolConfig poolConfig = new JedisPoolConfig();
//最大连接数
poolConfig.setMaxTotal(10);
//最大空闲连接数
poolConfig.setMaxIdle(5);
jedisSentinelPool = new JedisSentinelPool(masterName, connectionMes, poolConfig);
}
public static Jedis getConnection() {
return jedisSentinelPool.getResource();
}
}
复制代码
4.2 使用数据分片集群
*Jedis中通过JedisCluster实例使用数据分片集群,连接数据分片集群中所有节点(可以直接创建JedisCluster实例,也可以添加连接池进行管理)
复制代码
/**
- @Auther: ZHUANGHAOTANG
- @Date: 2019/4/2 17:11
- @Description:
*/
public class RedisUtils {
private static JedisCluster jedisCluster = null;
static {
//连接RedisCluster中的所有节点
Set<HostAndPort> connectionMes = new HashSet<>();
connectionMes.add(new HostAndPort("192.168.2.90", 6379));
connectionMes.add(new HostAndPort("192.168.2.90", 6380));
connectionMes.add(new HostAndPort("192.168.2.91", 6379));
connectionMes.add(new HostAndPort("192.168.2.91", 6380));
connectionMes.add(new HostAndPort("192.168.2.92", 6379));
connectionMes.add(new HostAndPort("192.168.2.92", 6380));
//连接池配置
JedisPoolConfig poolConfig = new JedisPoolConfig();
//最大连接数
poolConfig.setMaxTotal(10);
//最大空闲连接数
poolConfig.setMaxIdle(5);
jedisCluster = new JedisCluster(connectionMes, poolConfig);
}
}
复制代码
*当使用集群的模式连接RedisCluster时,当进行读取和写入操作时,会随机连接集群中的一个节点,然后根据H(K)散列函数计算出Key所坐落的槽,然后找到该槽所对应处理的Master节点,最后自动跳转到该节点中进行操作。
5.Redis集群数据迁移方案
5.1 主从复制集群的数据迁移
当需要将当前主从复制集群中的数据迁移到一个新的主从复制集群时
1.搭建新的主从复制集群,然后关闭集群,先关闭所有Slave节点,再关闭Master节点,避免发生主从切换。
2.将旧集群中的Master节点的RDB文件复制到新集群中的Master节点。
3.重启新集群,自动进行数据的恢复。
*先关闭新集群再进行RDB文件的迁移,是因为当节点进行shutdown操作时,会自动触发bgsave命令,避免RDB文件被替换。
*关闭集群时先关闭所有Slave节点再关闭Master节点,是为了避免发生主从切换,当重启集群时,导致主从数据不一致的问题。
5.2 数据分片集群的数据迁移
当需要将当前数据分片集群中的数据迁移到一个新的数据分片集群时
1.使用与旧集群相同的Master节点个数以及相同的槽范围搭建新的数据分片集群(手动/自动搭建)
2.依次关闭新集群中的各个节点,先关闭所有Slave节点,再关闭所有Master节点,避免发生主从切换。
3.根据旧集群的node.conf文件查看Master节点的相关信息,再查看新集群的node.conf文件中Master节点的相关信息,然后将旧集群中的Master节点的RDB文件复制到新集群对应槽范围的Master节点中,最后重启新集群,自动进行数据恢复。
*根据两个集群的node.conf文件来确定不同槽范围的Master节点的映射关系。
*不管是主从复制集群还是数据分片集群,新集群中的Slave节点的个数都不需要和旧集群的一致。
6.Redis集群扩容
Redis集群扩容是相对于数据分片集群来说的,在现有集群的架构下,通过增加多个Master节点来提高Redis集群的负载能力。
6.1 准备要加入到集群的节点
*根据实际的业务情况决定要增加的Master节点个数,以及对应Slave节点的个数。
6.2 分别进行握手,使其加入到集群中
6.3 进行槽位和数据的迁移
*使用redis-trib.rb reshared --timeout :命令进行槽位和数据的迁移,其中timeout指定每个槽迁移时最大的超时时间,ip和端口指定接收槽和数据的目标节点。
*需要指定在当前集群中移动多少个槽位到目标节点中,值可以选1~16384,并且需要指定目标节点在集群中的ID。
*可以选择all和done两种迁移模式,其中all表示将集群中的所有节点作为槽的源节点(平均分配),done表示指定集群中的某个节点作为槽的源节点。
*在槽和数据迁移的过程中,用户的请求会有相应的延时,整个迁移过程所需要的时间与Redis集群中的数据量成正比(线上试过平均2.5s迁移一个槽,迁移6000个槽耗费了4小时)
*在槽和数据迁移的过程中,如果某个槽位在迁移时报错,那么Redis会停止迁移,在它之前迁移的槽和数据仍会生效,当再次迁移时需要执行fix命令(会有提示),删除迁移失败的槽位的数据。
*使用了all模式,可见迁移后的槽从之前的Master中分别平均抽取1364/1365个槽。
6.4 主从映射