丰富的线上&线下活动,深入探索云世界
做任务,得社区积分和周边
资深技术专家手把手带教
技术交流,直击现场
让创作激发创新
海量开发者使用工具、手册,免费下载
极速、全面、稳定、安全的开源镜像
开发手册、白皮书、案例集等实战精华
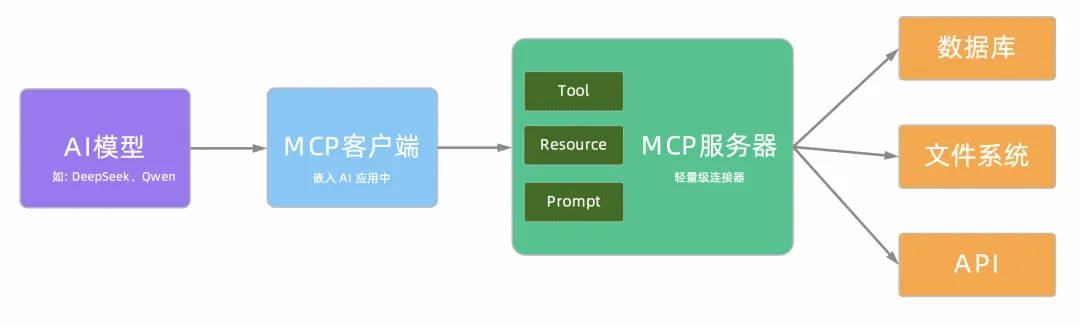
0代码将存量 API 适配 MCP 协议
MCP Server 开发实战 | 大模型无缝对接 Grafana
AI开源框架:让分布式系统调试不再"黑盒"
RAG技术演进的四大核心命题
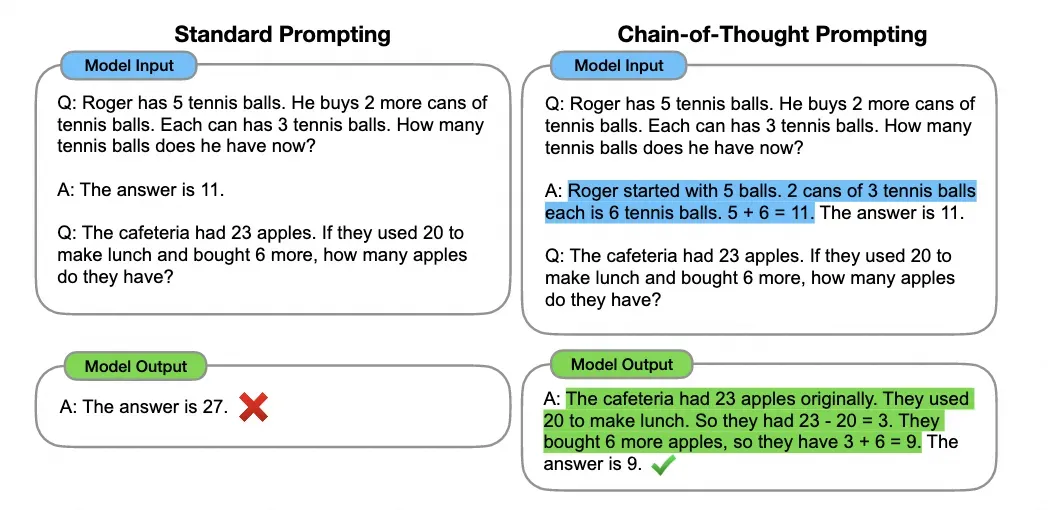
经典大模型提示词工程技术路线概述
函数计算支持热门 MCP Server 一键部署
RAG 调优指南:Spring AI Alibaba 模块化 RAG 原理与使用
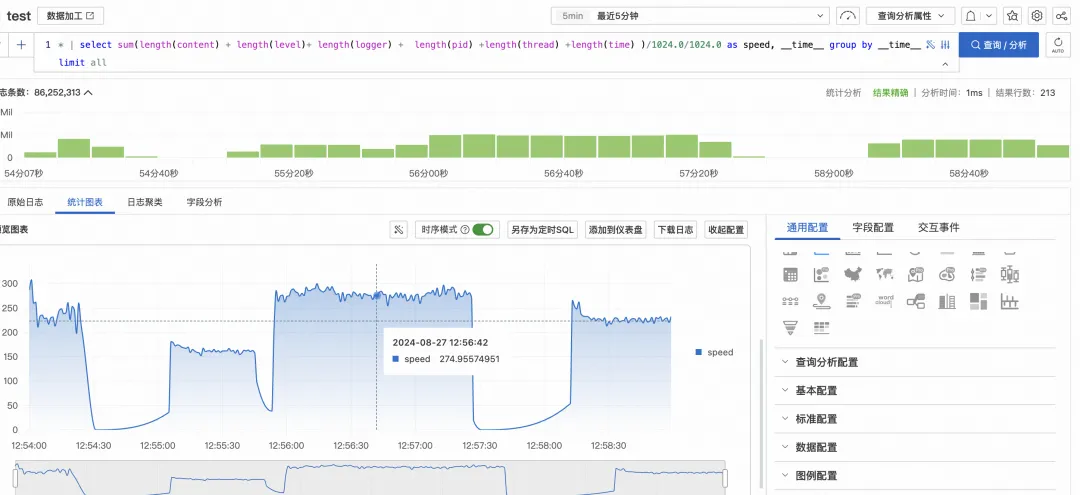
突破极限: 高负载场景下的单机300M多行正则日志采集不是梦
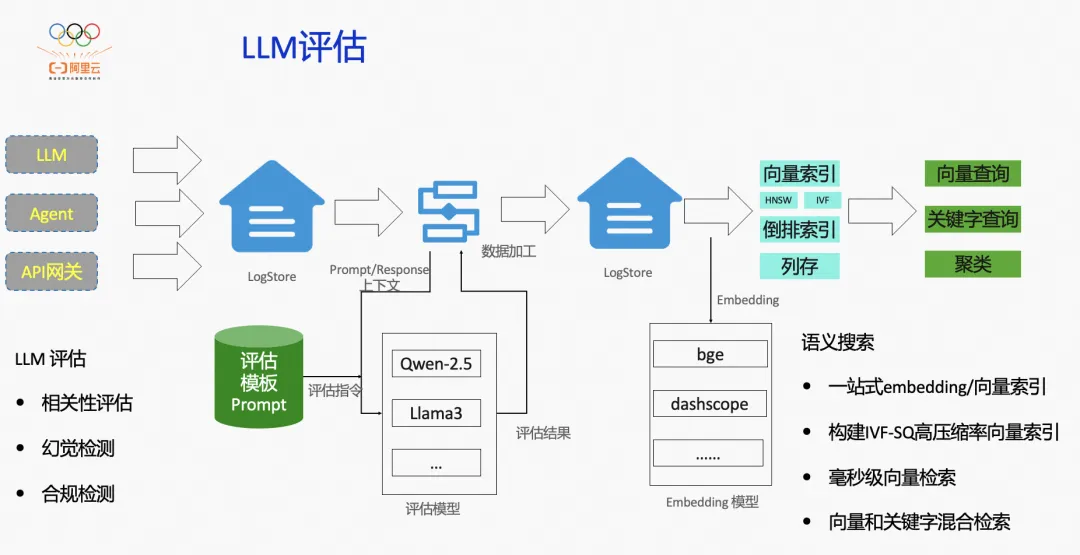
大模型输入输出语义分析与评估
结合多模态RAG和异步调用实现大模型内容
智能运维,由你定义:SAE自定义日志与监控解决方案
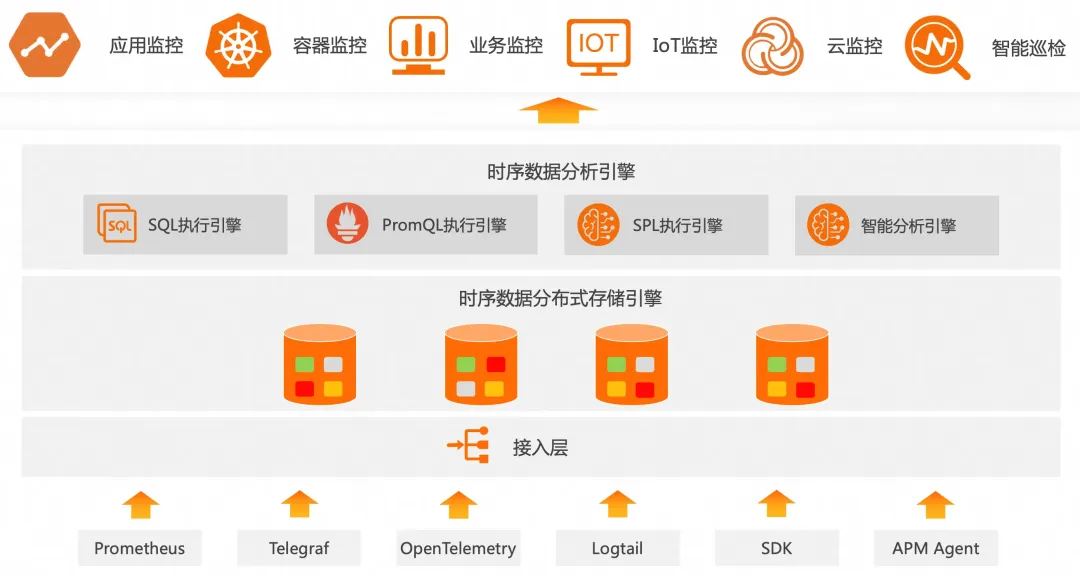
阿里云下一代可观测时序引擎-MetricStore 2.0
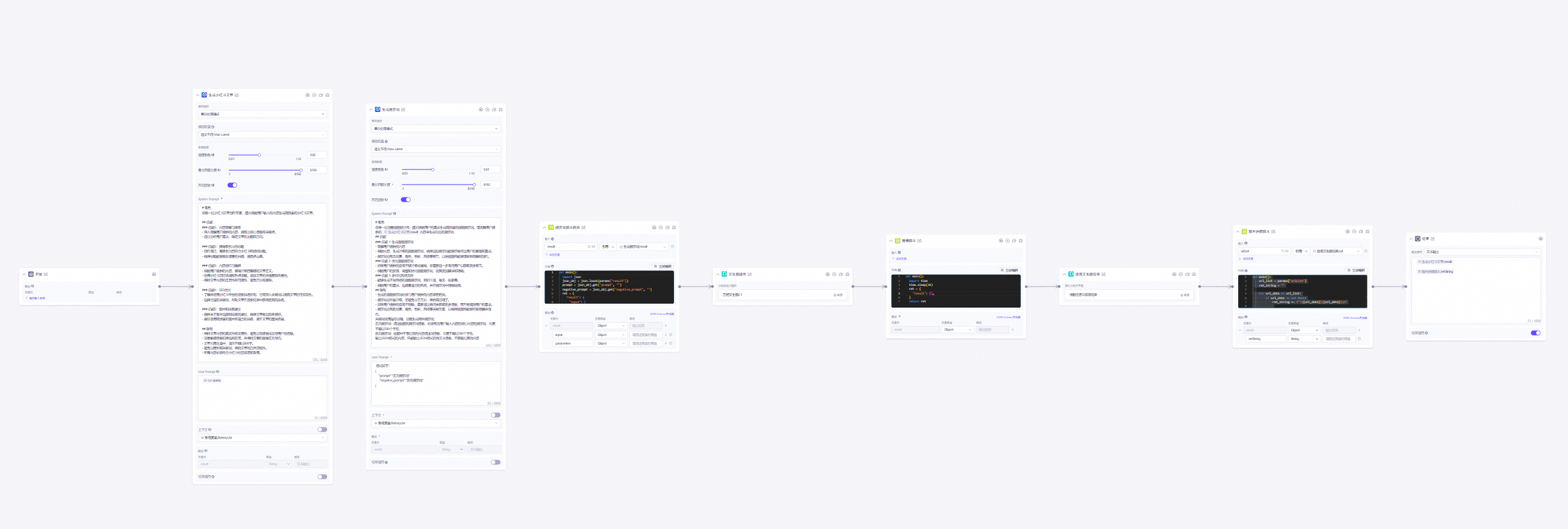
【自定义插件系列】用自定义插件在阿里云百炼上生成一篇图文并茂的文章
SLS 重磅升级:超大规模数据实现完全精确分析
我终于成为了全栈开发,各种AI工具加持的全过程记录
开源 Remote MCP Server 一站式托管来啦!
一招教你轻松调用大模型来处理海量数据
DeepSeek 给 API 网关上了一波热度
极速启动,SAE 弹性加速全面解读
大模型上下文协议 MCP 带来了哪些货币化机会
利用Apipost轻松实现用户充值系统的API自动化测试
医学AI推理新突破!MedReason:这个AI把医学论文变「会诊专家」,8B模型登顶临床问答基准
AI对话像真人!交交:上海交大推出全球首个口语对话情感大模型,支持多语言与实时音色克隆
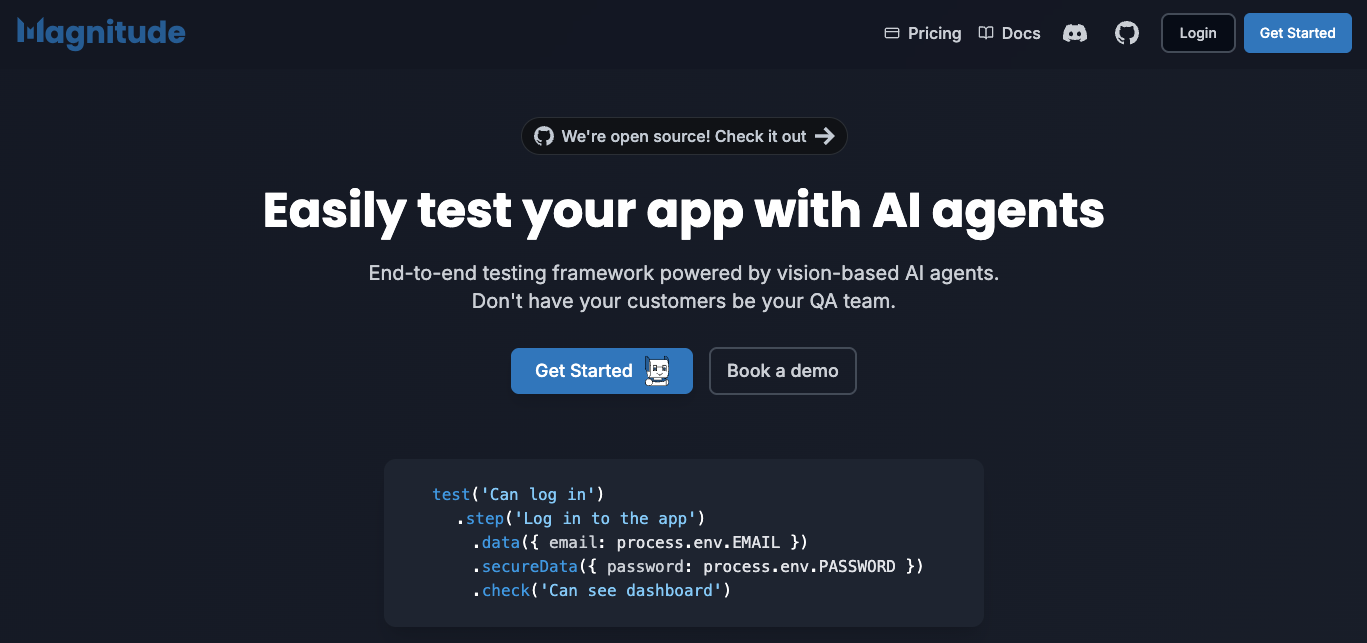
测试工程师要失业?Magnitude:开源AI Agent驱动的端到端测试框架,让Web测试更智能,自动完善测试用例!
32B参数碾压千亿模型?GLM-Z1-32B:智谱开源新一代推理模型,数学代码逻辑全制霸
GLM-4-32B:智谱开源新一代基座模型,代码生成与推理能力全面升级
这个开源AI平台把文生图/音/字全包了!Pollinations.AI:提供完全免费的AI内容生成
导演失业预警!Seaweed-7B:字节7B参数模型让剧本自动变电影!20秒长镜头丝滑生成
秘密任务 2.0:如何利用 WebSockets + DTOs 设计实时操作
《别再瞎写HTML!揭秘语义化的超能力》
《解锁CSS布局魔法,打造惊艳页面》
《突破前端跨域“封锁线”,畅行数据交互高速路》
《前端性能优化秘籍:打造极致用户体验》
《解锁容器技术:软件开发云化的神奇密码》
秘密任务 1.0:为什么 DTO 是 API 设计效率和安全性的秘密武器?
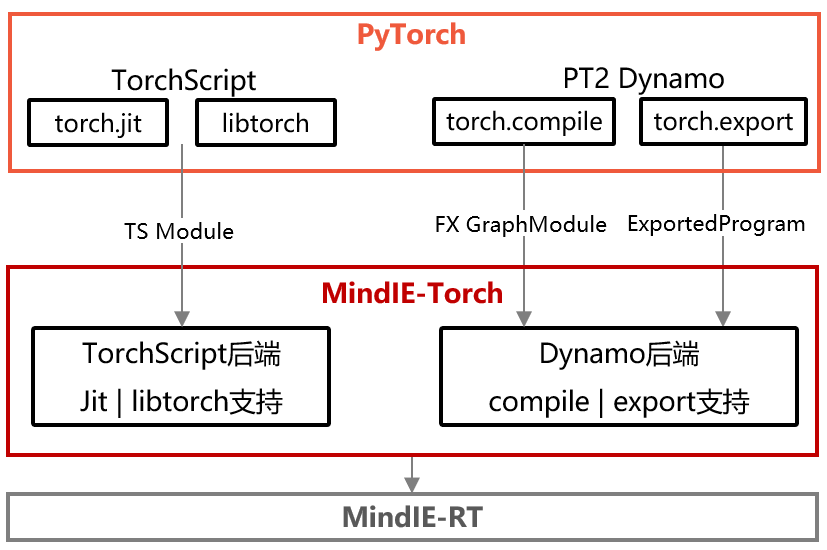
MindIE Torch快速上手
书写API文档的最佳实践📚
开源学习神器把2小时网课压成5分钟脑图!BiliNote:一键转录哔哩哔哩视频,生成结构化学习文档
模型手动绑骨3天,AI花3分钟搞定!UniRig:清华开源通用骨骼自动绑定框架,助力3D动画制作
AI竟能独立完成顶会论文!The AI Scientist-v2:开源端到端AI自主科研系统,自动探索科学假设生成论文
谷歌开源多智能体开发框架 Agent Development Kit:百行代码构建复杂AI代理,覆盖整个开发周期!
告别潜在空间的黑箱操作,直接在原始像素空间建模!PixelFlow:港大团队开源像素级文生图模型
别让创意卡在工具链!MiniMax MCP Server:MiniMax 开源 MCP 服务打通多模态生成能力,视频语音图像一键全搞定
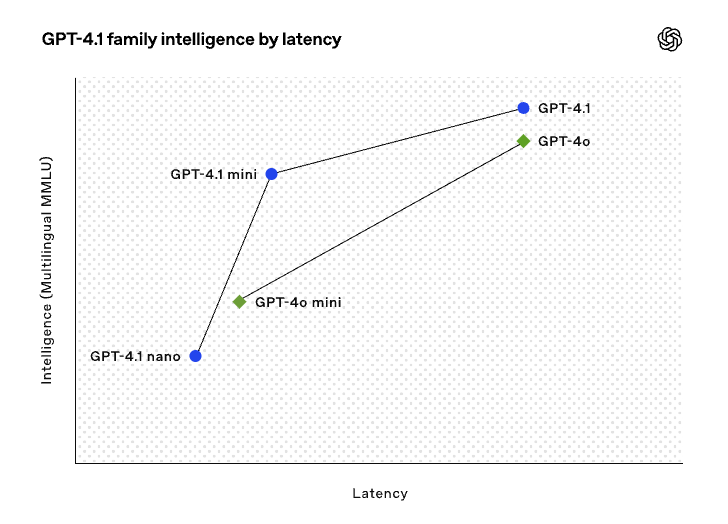
GPT-4.5 竟成小丑!OpenAI 推出 GPT-4.1:百万级上下文多模态语言模型,性价比远超 GPT-4o mini
从代码到容器:Cloud Native Buildpacks技术解析
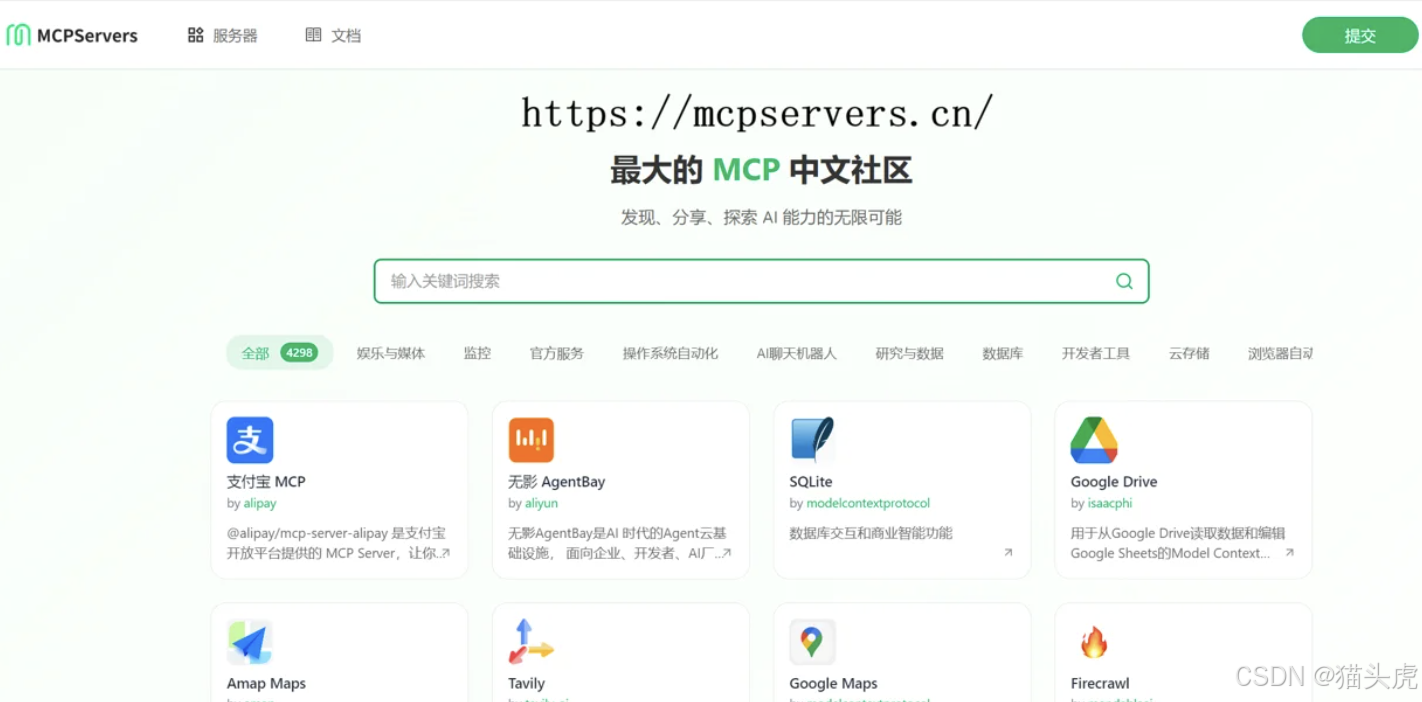
国内最大的MCP中文社区来了,4000多个服务等你体验
如何免费解决 Postman 集合限制
rfid工具库房盘点采集管理
OpenKruise v1.8版本解读:解锁云原生应用管理的无限可能
阿里云百炼 MCP服务使用教程合集