前提知识
在oracle数据库中,每一行记录都有一个该记录的唯一标识rowid,rowid一旦确定不会随意变动。rowid由10个字节存储,在数据库查询中显示为18位的字符串,在其内部存储以下信息:1.对象编号。2.记录所在数据文件。3.记录所在文件上块的编号。4.记录所在块的行编号。
在两表的关联更新时,一般都会在表上建立索引。在表上建立索引时,oracle会根据索引字段的内容(key)和该行的rowid(value)建立一个B-tree,一般为三层,达到4层时会影响索引性能。当执行查询时,先根据关键字段找到对应的rowid,再根据rowid到磁盘中找到记录的位置将记录查询出来。
大表关联更新的瓶颈
执行两表关联更新时,oracle一般采用类似nested_loop的更新方式。当依据关联关系将表B的值更新到A表的字段中时,先遍历A表的,对A表的每行记录查询B表的索引,得到b表的结果后再更新到A表。由于存在查询索引的操作,更新每条记录都会至少执行两次io操作。第一次查询索引、第二次根据索引的rowid查询数据。当执行大规模数据更新时,速度会很慢。
性能瓶颈突破思路
所谓“成也萧何败萧何”,既然在大规模的数据更新中索引存在性能瓶颈,那就想办法在大规模数据更新时避免索引的使用。由于rowid是记录的唯一标识且根据rowid去更新时会自动定位记录所在位置(比通过索引更快),可以考虑将rowid和要更新的结果批量查询出来再批量去更新。批量查询时,oracle一般会采用hash关联的方式。在两表数据量比较大时,hash关联比通过索引nested_loop关联快很多倍。
测试结果及源码
有了以上思路,可以通过存储过程代替update语句实现更新。在存储过程中可以暂时保存批量查询的结果,依据批量查询的结果执行更新。后面的测试结果是我在虚拟机上跑出来的,性能差异不明显。如果是物理机性能差距会更大。
首先建两张表并造一些测试数据
drop table test_user purge;
create table test_user
( user_id number(11),
user_name varchar2(64),
user_acct number(11)
) tablespace tbs_all_in_one;
drop table test_relations purge;
create table test_relations
(
user_id number(11),
user_acct number(11),
start_date date,
end_date date
)tablespace tbs_all_in_one;
insert into test_user values (NULL,NULL,NULL);
commit;
--造200w条A表数据
set serveroutput on;
begin
for i in 1..21 loop
insert into test_user select * from test_user;
commit;
dbms_output.put_line('insert loop: '||i);
end loop;
end;
/
select count(*) from test_user;
--根据rownum更新A表的user_id
update test_user a
set a.user_id=rownum+100000000,
a.user_name='user_name'||to_char(rownum+100000000),
a.user_acct = 0;
commit;
--造400w条B表数据
insert into test_relations
select user_id,user_id+200000000,sysdate-365,sysdate-30-1/86400
from test_user;
commit;
insert into test_relations
select user_id,user_id+200000000,sysdate-30, sysdate+365
from test_user;
commit;
然后建立索引,并执行oracle的统计命令,统计两个表的信息
create index indx_test_user on test_user(user_id) tablespace tbs_all_in_one;
create index indx_test_relations on test_relations(user_id) tablespace tbs_all_in_one;
exec dbms_stats.gather_table_stats(OWNNAME=>'luhao',tabname=>'test_user',cascade=>true);
exec dbms_stats.gather_table_stats(OWNNAME=>'luhao',tabname=>'test_relations',cascade=>true);
普通更新语句的执行计划和时间
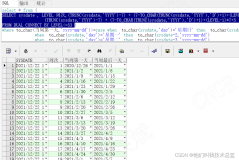
存储过程更新方法
分析上图的源码截图,先通过大表关联得到A表中的rowid和要更新的结果。将数据放到数组中,再通过forall语法根据rowid批量更新。
存储过程更新时间
存储过程源码
create or replace procedure p_test_update
as
iv_sql VARCHAR2(4000) ;
TYPE tab_acct IS TABLE OF NUMBER(11) INDEX BY binary_integer;
TYPE ref_cur IS REF CURSOR;
rowid_arry dbms_sql.urowid_table;
acct_array tab_acct;
iv_cur ref_cur;
start_time date;
finish_time date;
begin
select sysdate into start_time from dual;
iv_sql := 'select a.rowid, b.user_acct from test_user a, test_relations b
where a.user_id = b.user_id and sysdate between b.start_date and b.end_date';
open iv_cur for iv_sql;
loop
fetch iv_cur bulk collect into rowid_arry,acct_array limit 10000;
exit when rowid_arry.count = 0;
--更新acct
forall i in 1..rowid_arry.count
update test_user a
set a.user_acct = acct_array(i)
where rowid = rowid_arry(i);
end loop;
close iv_cur;
commit;
select sysdate into finish_time from dual;
dbms_output.put_line('cost seconds:'||(finish_time-start_time)*86400);
end;
限制
只能更新静态数据,不能支持事务。
https://promotion.aliyun.com/ntms/yunparter/invite.html?userCode=0dxlx7ji