热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
深入比较Input、Change和Blur事件:Vue与React中的行为差异解析
内存
局部变量:
Linux权限管理
局部变量和成员变量
springboot @EnableResourceServer的概念与作用
PYTHON链家租房数据分析:岭回归、LASSO、随机森林、XGBOOST、KERAS神经网络、KMEANS聚类、地理可视化
诚邀您参加MongoDB线下技术沙龙-杭州站
Vue中的数据变化监控与响应——深入理解Watchers
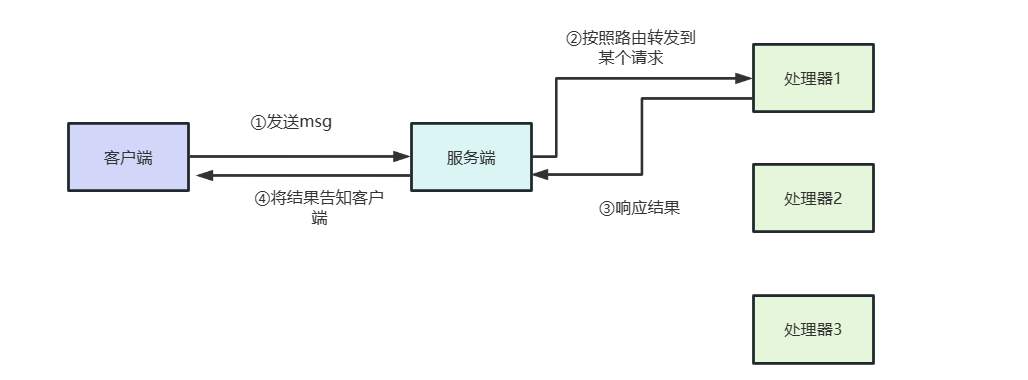
来聊聊Netty使用不当导致的并发波动问题
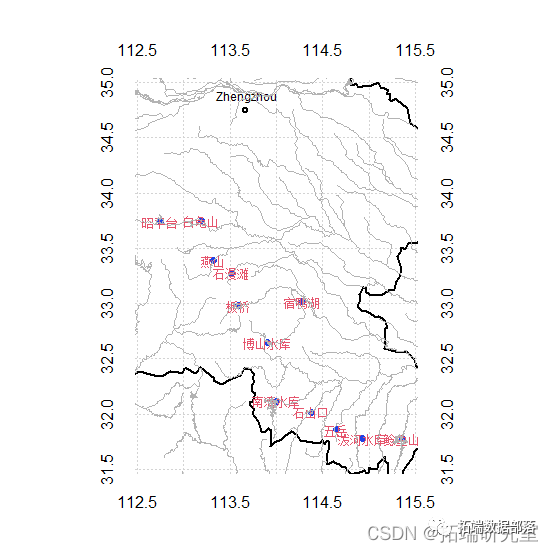
R语言淮河流域水库水质数据相关性分析、地理可视化、广义相加模型GAM调查报告(上)
Vue与React数据流设计比较:响应式与单向数据流
探索灵活性与可维护性的利器:策略(Strategy)模式详解
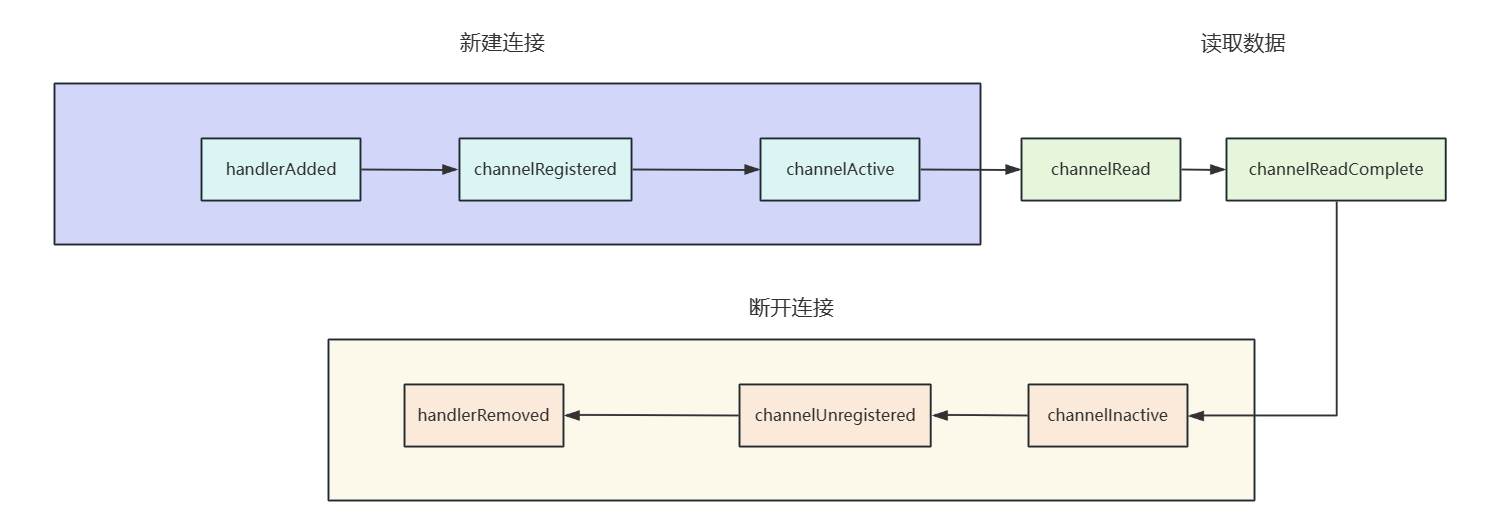
来聊聊ChannelHandler
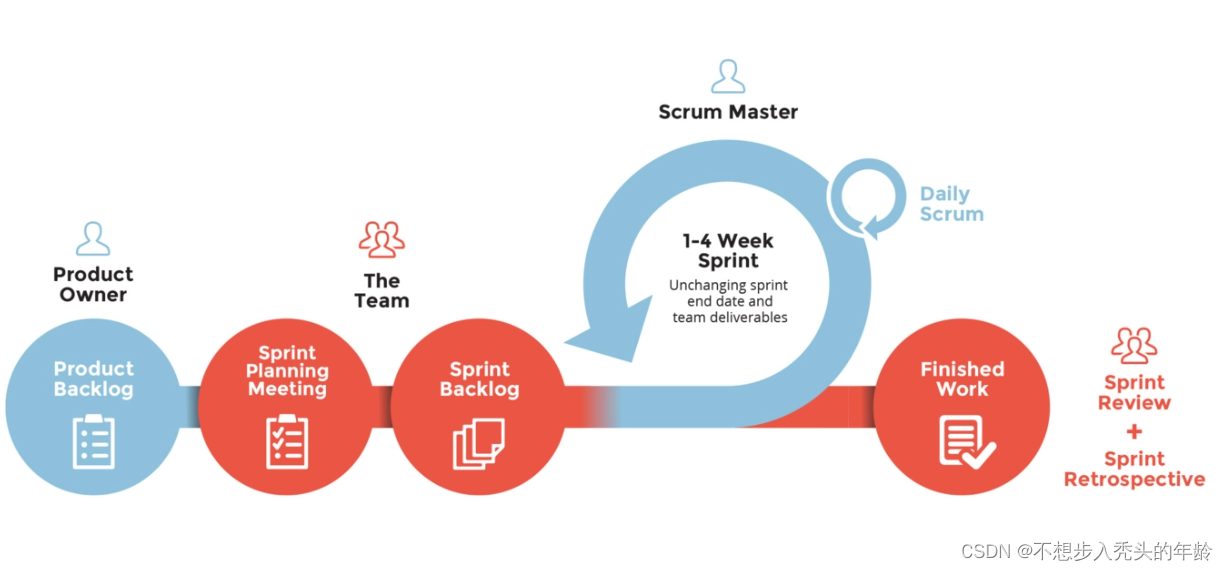
深入探讨敏捷开发项目管理流程与Scrum工具:构建高效团队与卓越产品的秘诀
数据存储成本飙升?莫慌!RDS数据归档功能来了
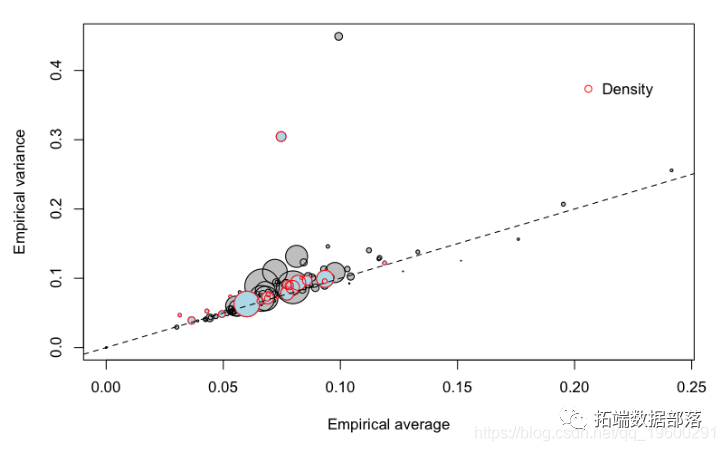
R语言广义线性模型索赔频率预测:过度分散、风险暴露数和树状图可视化
JVM的类的生命周期
【视频】检测异常值的4种方法和R语言时间序列分解异常检测
JVM类加载器的分类以及双亲委派机制
什么是SFP?SFP的主要特点
如何用潜类别混合效应模型(Latent Class Mixed Model ,LCMM)分析老年痴呆年龄数据
Linux(Centos6.5)下kvm环境搭建
电力与数据同行:深入探索PoE与PoE+技术
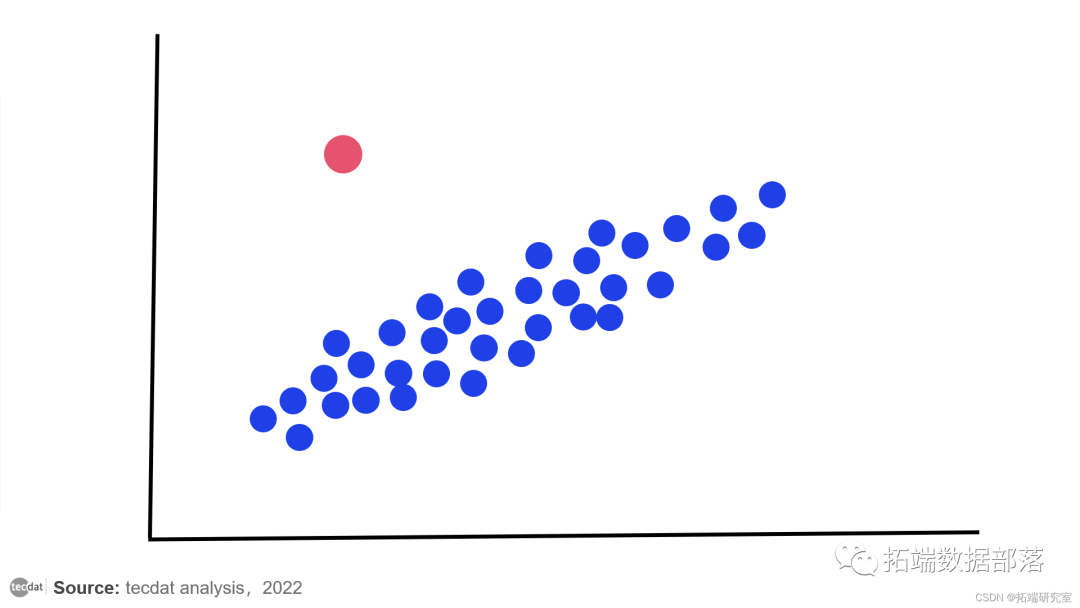
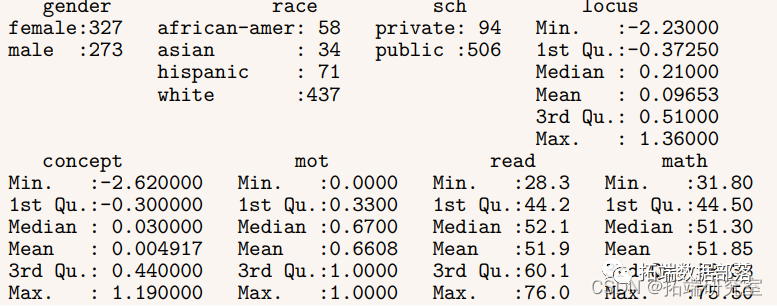
数据分享|R语言回归模型诊断、离群值分析学生考试成绩、病人医护质量满意度、婴儿死亡率和人均收入、针叶树荫面积数据
I0类传感器
R语言分布滞后线性和非线性模型DLM和DLNM建模应用| 系列文章
global
OpenCV
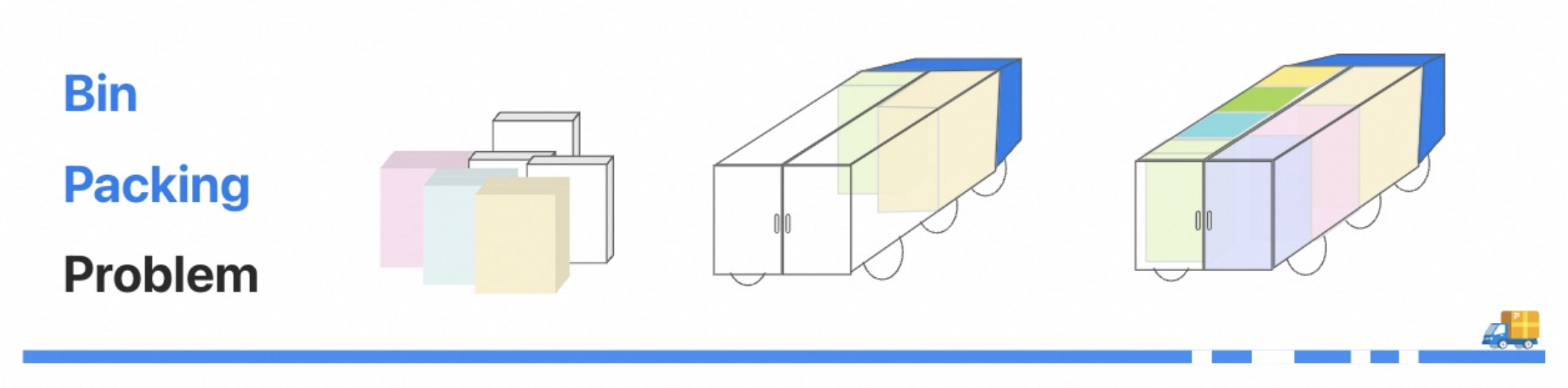
智能解决装箱问题:使用优化算法实现高效包装
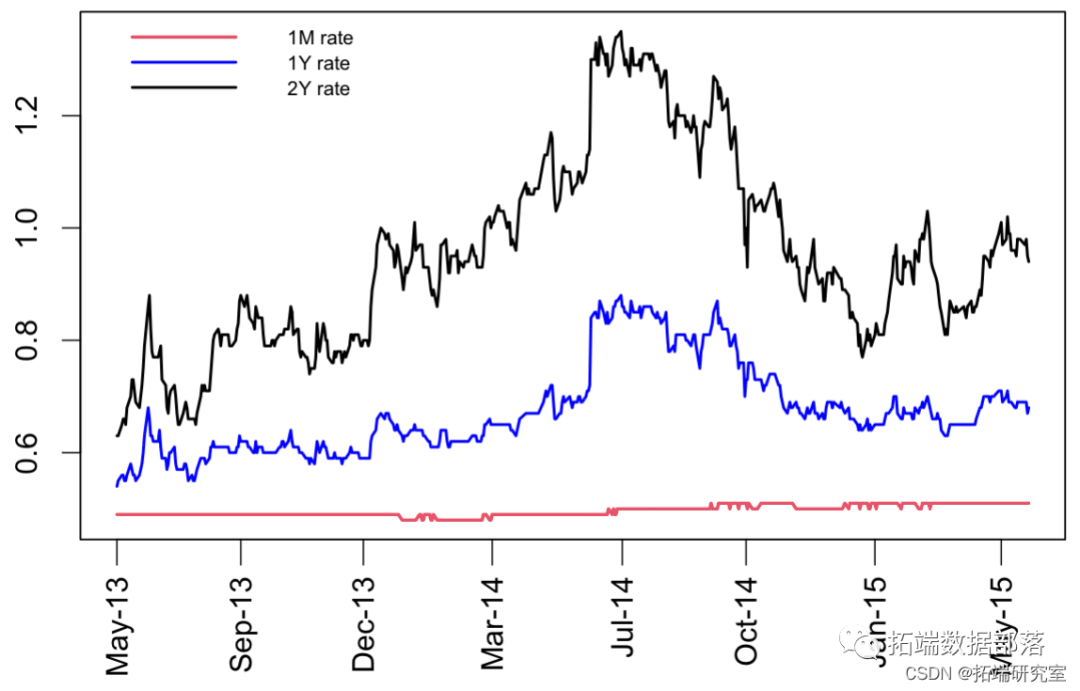
R语言ECM误差修正模型、均衡修正模型、受限VECM、协整检验、单位根检验即期利率市场数据
【LLMOps】AIGC使用场景解决方案
socks5代理是什么意思?它跟http代理有什么不同点?它有什么应用场景?
阿里云服务器实例哪些属于入门级,哪些是企业级?有何区别?
HTTP代理,什么是HTTP代理?HTTP代理如何设置?HTTP代理的用途?
SFP 端口:连接世界的通用接口
SFP与GBIC详解:探索两者的细微差别
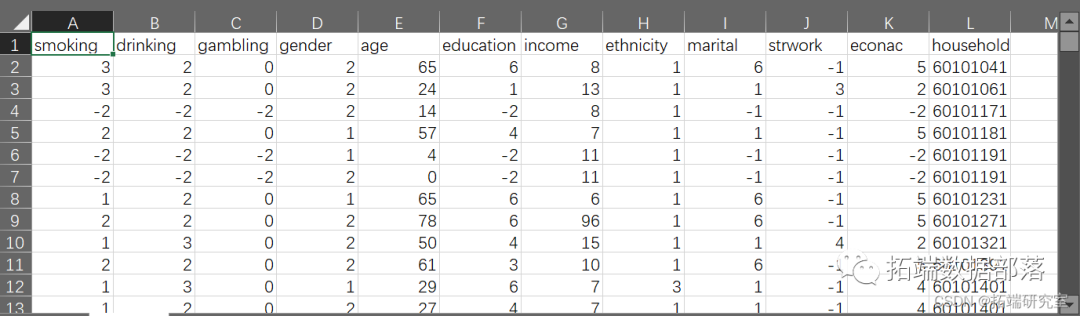
R语言MCMC的lme4二元对数Logistic逻辑回归混合效应模型分析吸烟、喝酒和赌博影响数据
SFP与SFP+深入比较:探索下一代模块的优势
【AIGC】人工智能在教育领域的场景应用
深入了解SFP收发器:探索多种类型与应用领域
QSFP与SFP详解:探索下一代模块的显著差异
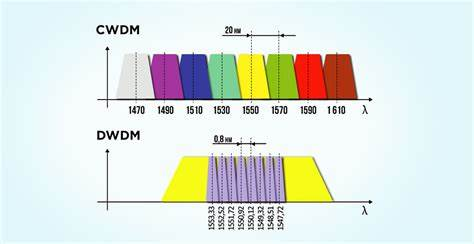
DWDM和CWDM光学技术的区别
【视频】逆变换抽样将数据标准化和R语言结构化转换:BOX-COX、凸规则变换方法
R语言动态图可视化:如何、创建具有精美动画图
R语言广义线性模型GLM、多项式回归和广义可加模型GAM预测泰坦尼克号幸存者