
作者 | 阿里云智能事业群技术专家 莫源
[](https://www.atatech.org/articles/136659#1)Spark Operator的内部实现
在深入解析Spark Operator之前,我们先补充一些关于kubernetes operator的知识。2018年可以说是kubernetes operator泛滥的一年,各种operator如雨后春笋般出现。operator是扩展kubernetes以及与kubernetes集成的最佳方式之一。在kubernetes的设计理念中,有很重要的一条就是进行了抽象,比如对存储进行抽象、对应用负载进行抽象、对接入层进行抽象等等。每个抽象又对应了各自生命周期管理的controller,开发者提交的Yaml实际上是对抽象终态的描述,而controller会监听抽象的变化、解析并进行处理,最终尝试将状态修正到终态。
那么对于在kubernetes中未定义的抽象该如何处理呢,答案就是operator。一个标准operator通常包含如下几个部分:1. CRD抽象的定义,负责描述抽象所能包含的功能。 2.CRD Controller ,负责解析CRD定义的内容以及生命周期的管理。3.clent-go的SDK,负责提供代码集成时使用的SDK。
有了这个知识储备,那么我们回过头来看Spark Operator的代码,结构基本就比较明晰了。核心的代码逻辑都在pkg下,其中apis下面主要是定义了不同版本的API;client目录下主要是自动生成的client-go的SDK;crd目录下主要是定义的两个自定义资源sparkapplication和scheduledsparkapplication的结构。controller目录下主要定义的就是这个operator的生命周期管理的逻辑;config目录下主要处理spark config的转换。了解一个Operator能力最快捷的方式,就是查看CRD的定义。在Spark Operator中定义了sparkapplication和scheduledsparkapplication两个CRD,他们之间有什么区别呢?
sparkapplication 是对常规spark任务的抽象,作业是单次运行的,作业运行完毕后,所有的Pod会进入Succeed或者Failed的状态。而scheduledsparkapplication是对离线定时任务的一种抽象,开发者可以在scheduledsparkapplication中定义类似crontab的任务,实现spark离线任务的周期性定时调度。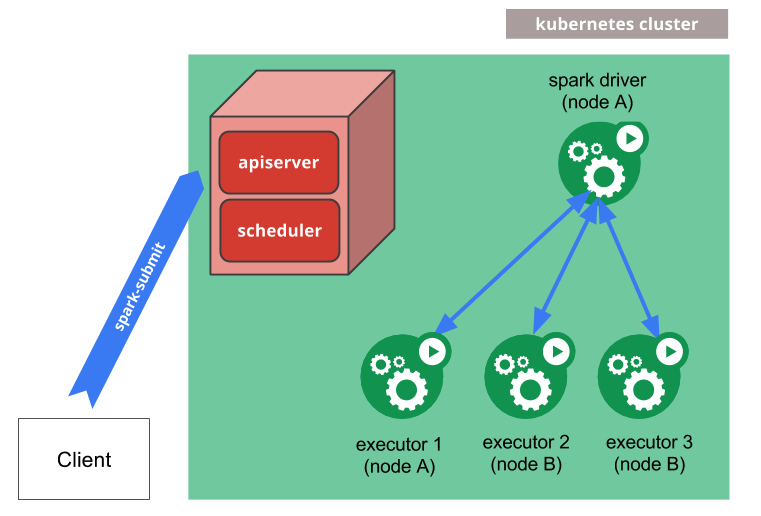
上面这张图是Spark中kubernetes的集成图,也就是说当我们通过spark-submit提交作业的时候,会自动生成driver pod与exector pods。那么引入了Spark Operator后,这个流程变成了什么呢?
func (c *Controller) submitSparkApplication(app *v1beta1.SparkApplication) *v1beta1.SparkApplication {
// prometheus的监控指标的暴露
appToSubmit := app.DeepCopy()
if appToSubmit.Spec.Monitoring != nil && appToSubmit.Spec.Monitoring.Prometheus != nil {
if err := configPrometheusMonitoring(appToSubmit, c.kubeClient); err != nil {
glog.Error(err)
}
}
// 将CRD中的定义转变为spark-submit的命令
submissionCmdArgs, err := buildSubmissionCommandArgs(appToSubmit)
if err != nil {
app.Status = v1beta1.SparkApplicationStatus{
AppState: v1beta1.ApplicationState{
State: v1beta1.FailedSubmissionState,
ErrorMessage: err.Error(),
},
SubmissionAttempts: app.Status.SubmissionAttempts + 1,
LastSubmissionAttemptTime: metav1.Now(),
}
return app
}
// 在operator容器内通过spark-submit提交作业
submitted, err := runSparkSubmit(newSubmission(submissionCmdArgs, appToSubmit))
if err != nil {
app.Status = v1beta1.SparkApplicationStatus{
AppState: v1beta1.ApplicationState{
State: v1beta1.FailedSubmissionState,
ErrorMessage: err.Error(),
},
SubmissionAttempts: app.Status.SubmissionAttempts + 1,
LastSubmissionAttemptTime: metav1.Now(),
}
c.recordSparkApplicationEvent(app)
glog.Errorf("failed to run spark-submit for SparkApplication %s/%s: %v", app.Namespace, app.Name, err)
return app
}
// 因为Pod的状态也会被Spark Operator进行观测,因此driver pod宕掉会被重新拉起
// 这是和直接跑spark-submit的一大区别,提供了故障恢复的能力。
if !submitted {
// The application may not have been submitted even if err == nil, e.g., when some
// state update caused an attempt to re-submit the application, in which case no
// error gets returned from runSparkSubmit. If this is the case, we simply return.
return app
}
glog.Infof("SparkApplication %s/%s has been submitted", app.Namespace, app.Name)
app.Status = v1beta1.SparkApplicationStatus{
AppState: v1beta1.ApplicationState{
State: v1beta1.SubmittedState,
},
SubmissionAttempts: app.Status.SubmissionAttempts + 1,
ExecutionAttempts: app.Status.ExecutionAttempts + 1,
LastSubmissionAttemptTime: metav1.Now(),
}
c.recordSparkApplicationEvent(app)
// 通过service暴露spark-ui
service, err := createSparkUIService(app, c.kubeClient)
if err != nil {
glog.Errorf("failed to create UI service for SparkApplication %s/%s: %v", app.Namespace, app.Name, err)
} else {
app.Status.DriverInfo.WebUIServiceName = service.serviceName
app.Status.DriverInfo.WebUIPort = service.nodePort
// Create UI Ingress if ingress-format is set.
if c.ingressURLFormat != "" {
ingress, err := createSparkUIIngress(app, *service, c.ingressURLFormat, c.kubeClient)
if err != nil {
glog.Errorf("failed to create UI Ingress for SparkApplication %s/%s: %v", app.Namespace, app.Name, err)
} else {
app.Status.DriverInfo.WebUIIngressAddress = ingress.ingressURL
app.Status.DriverInfo.WebUIIngressName = ingress.ingressName
}
}
}
return app
}
AI 代码解读
其实到此,我们就已经基本了解Spark Operator做的事情了,首先定义了两种不同的CRD对象,分别对应普通的计算任务与定时周期性的计算任务,然后解析CRD的配置文件,拼装成为spark-submit的命令,通过prometheus暴露监控数据采集接口,创建Service提供spark-ui的访问。然后通过监听Pod的状态,不断回写更新CRD对象,实现了spark作业任务的生命周期管理。
[](https://www.atatech.org/articles/136659#2)Spark Operator的任务状态机
当我们了解了Spark Operator的设计思路和基本流程后,还需要深入了解的就是sparkapplication的状态都包含哪些,他们之间是如何进行转换的,因为这是Spark Operator对于生命周期管理增强最重要的部分。
一个Spark的作业任务可以通过上述的状态机转换图进行表示,一个正常的作业任务经历如下几个状态:
New -> Submitted -> Running -> Succeeding -> Completed
AI 代码解读
而当任务失败的时候会进行重试,若重试超过最大重试次数则会失败。也就是说如果在任务的执行过程中,由于资源、调度等因素造成Pod被驱逐或者移除,Spark Operator都会通过自身的状态机状态转换进行重试。
[](https://www.atatech.org/articles/136659#3)Spark Operator的状态排查
我们已经知道了Spark Operator最核心的功能就是将CRD的配置转换为spark-submit的命令,那么当一个作业运行不预期的时候,我们该如何判断是哪一层出现的问题呢?首先我们要判断的就是spark-submit时所生成的参数是否是预期的,因为CRD的Yaml配置虽然可以增强表达能力,但是提高了配置的难度与出错的可能性。
func runSparkSubmit(submission *submission) (bool, error) {
sparkHome, present := os.LookupEnv(sparkHomeEnvVar)
if !present {
glog.Error("SPARK_HOME is not specified")
}
var command = filepath.Join(sparkHome, "/bin/spark-submit")
cmd := execCommand(command, submission.args...)
glog.V(2).Infof("spark-submit arguments: %v", cmd.Args)
if _, err := cmd.Output(); err != nil {
var errorMsg string
if exitErr, ok := err.(*exec.ExitError); ok {
errorMsg = string(exitErr.Stderr)
}
// The driver pod of the application already exists.
if strings.Contains(errorMsg, podAlreadyExistsErrorCode) {
glog.Warningf("trying to resubmit an already submitted SparkApplication %s/%s", submission.namespace, submission.name)
return false, nil
}
if errorMsg != "" {
return false, fmt.Errorf("failed to run spark-submit for SparkApplication %s/%s: %s", submission.namespace, submission.name, errorMsg)
}
return false, fmt.Errorf("failed to run spark-submit for SparkApplication %s/%s: %v", submission.namespace, submission.name, err)
}
return true, nil
}
AI 代码解读
默认情况下Spark Operator会通过glog level=2等级对外输出每次作业提交后转换的提交命令。而默认情况下,glog的level即为2,因此通过检查Spark Operator的Pod日志可以协助开发者快速排查问题。此外在sparkapplication上面也会通过event的方式进行状态的记录,上述状态机之间的转换都会通过event的方式体现在sparkapplication的对象上。掌握这两种方式进行问题排查,可以节省大量排错时间。
[](https://www.atatech.org/articles/136659#4)最后
使用Spark Operator是在kubernetes上实践spark的最佳方式,和传统的spark-submit相比提供了更多的故障恢复与可靠性保障,并且提供了监控、日志、UI等能力的集成与支持。在下一篇中,会为大家介绍在kubernetes集群中,提交spark作业时的如何使用外部存储存储的最佳实践。



