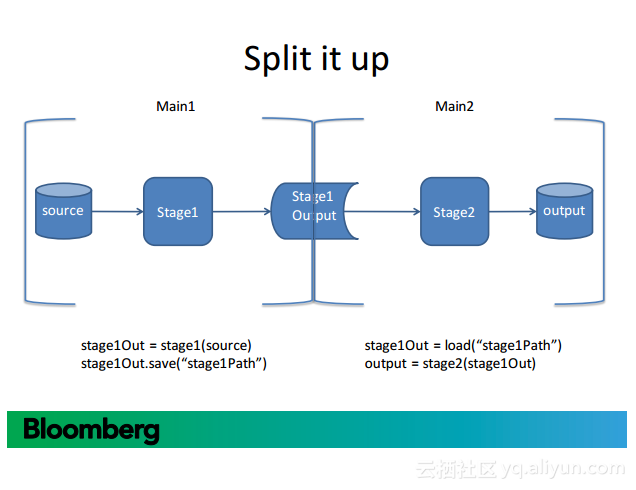
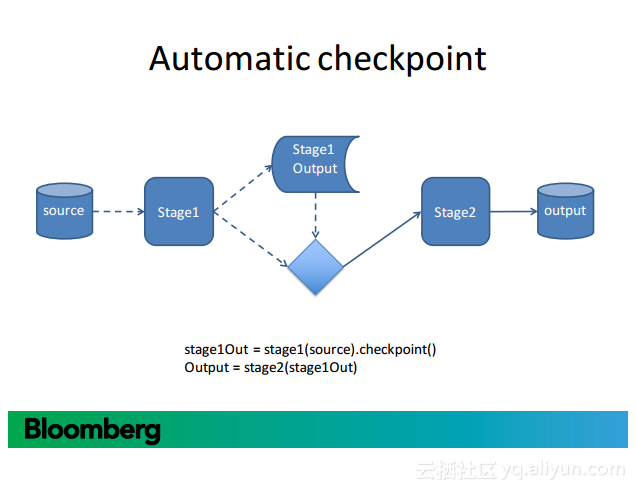
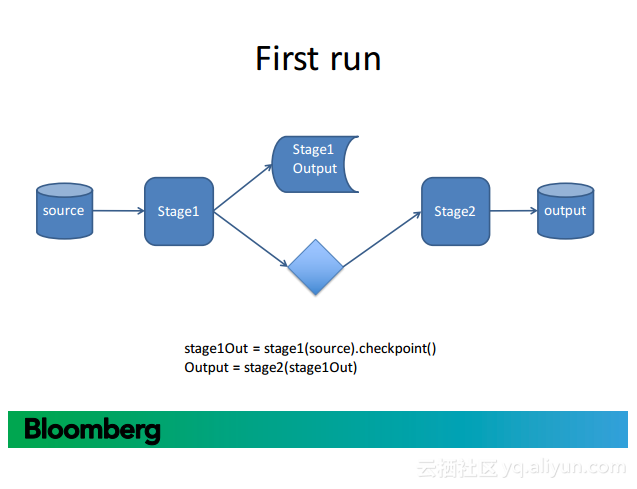
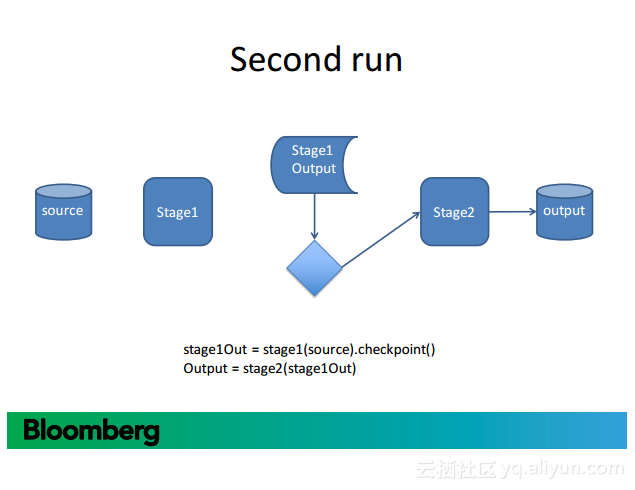
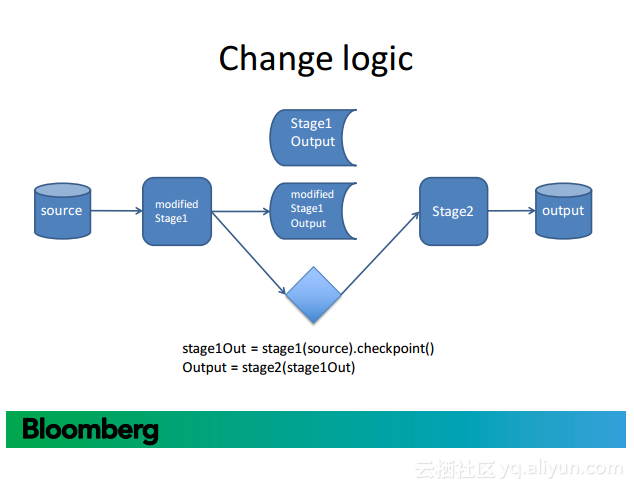
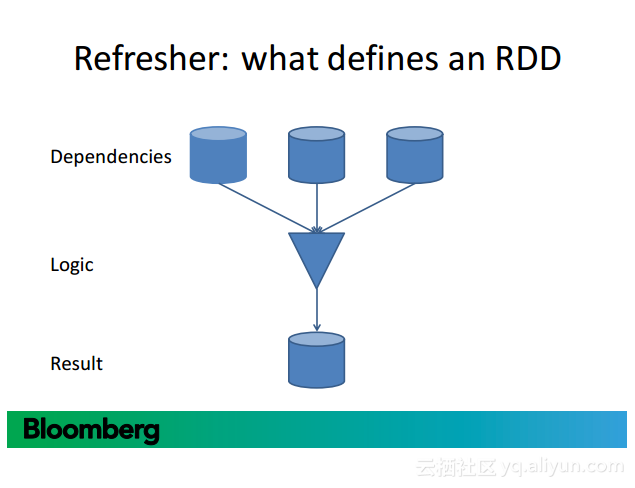
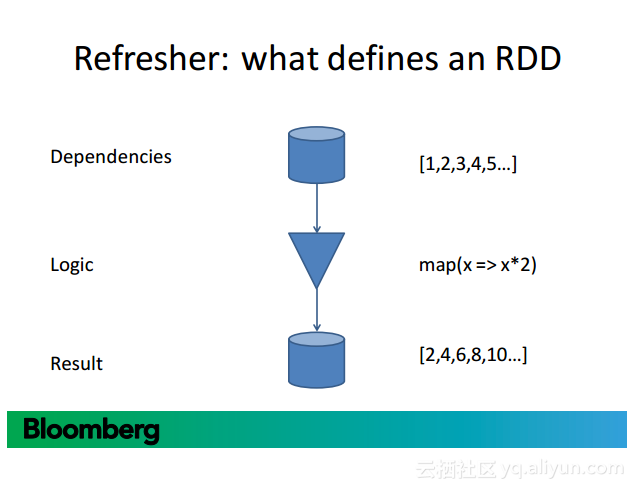
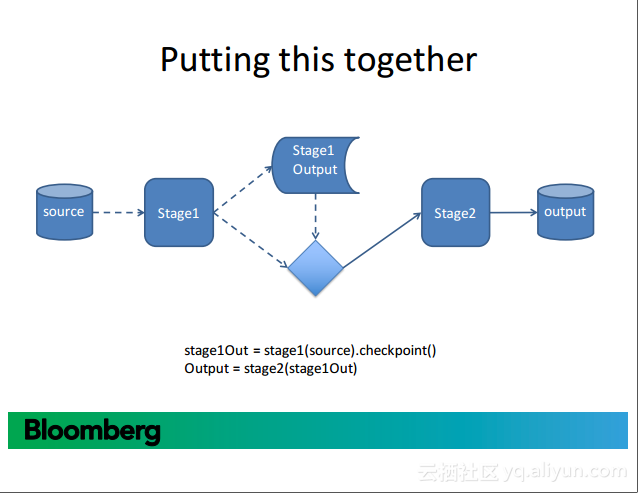
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
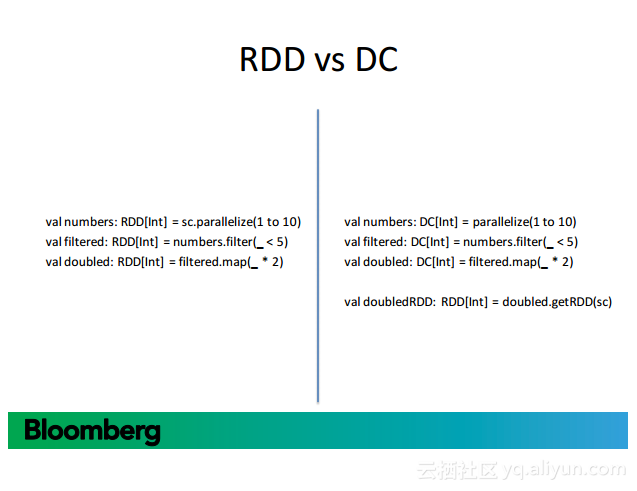
本讲义出自Nimbus Goehausen在Spark Summit EU 2016上的演讲,主要介绍了面对需要自动保证Spark的数据来源以及存储路径正确,并且在对于需要保存的数据进行保存而对于需要改变的数据进行改变,所以需要在Spark工作流中使用自动检查点来对以上要求进行保障,本讲义就主要介绍了Spark中自动检查点的设计动机、工作原理以及使用方法。