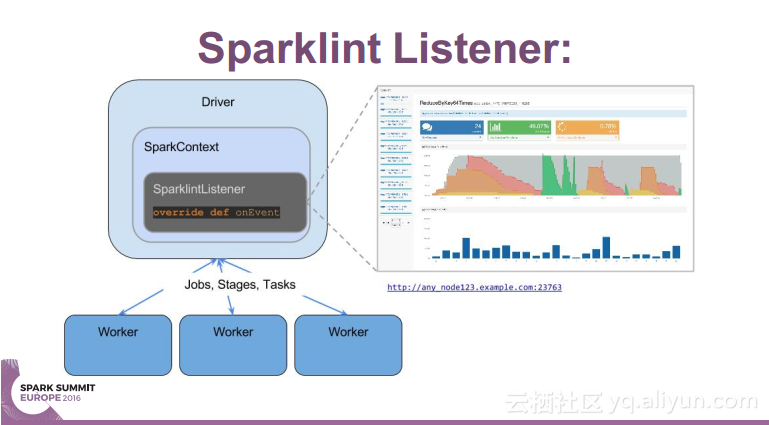
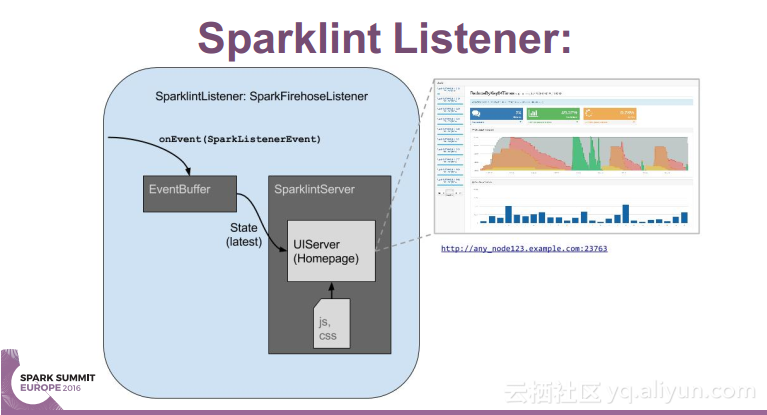
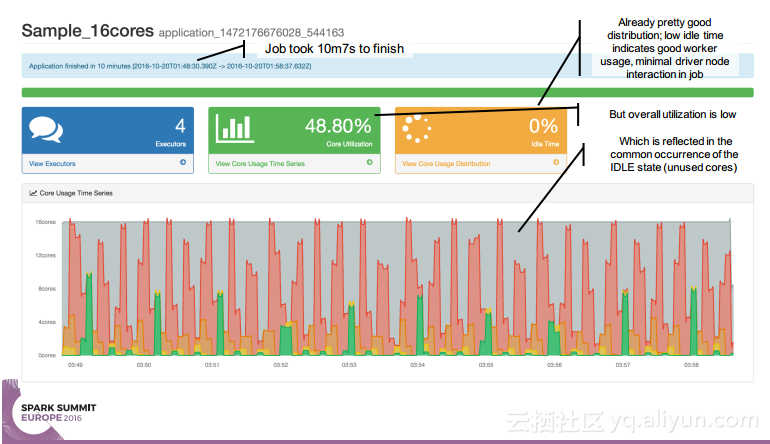
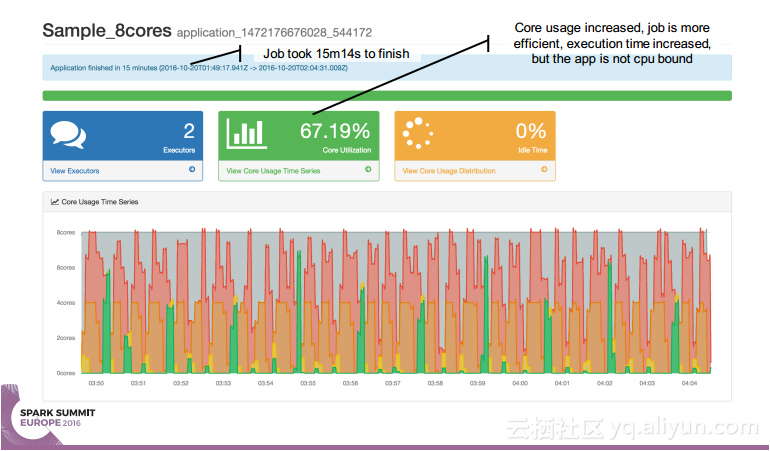
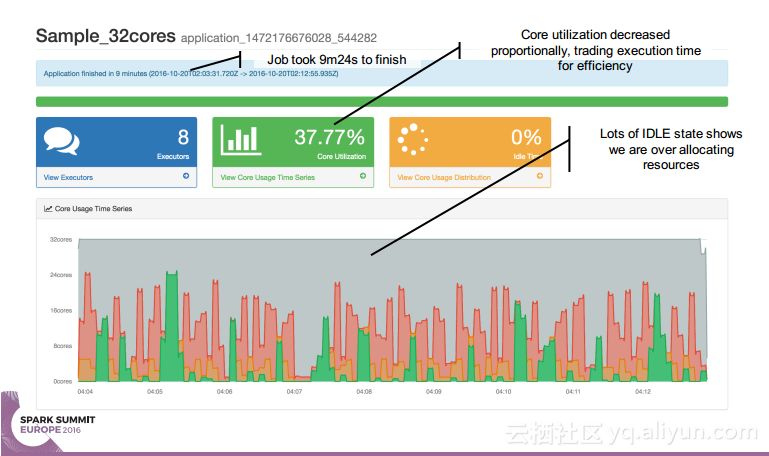
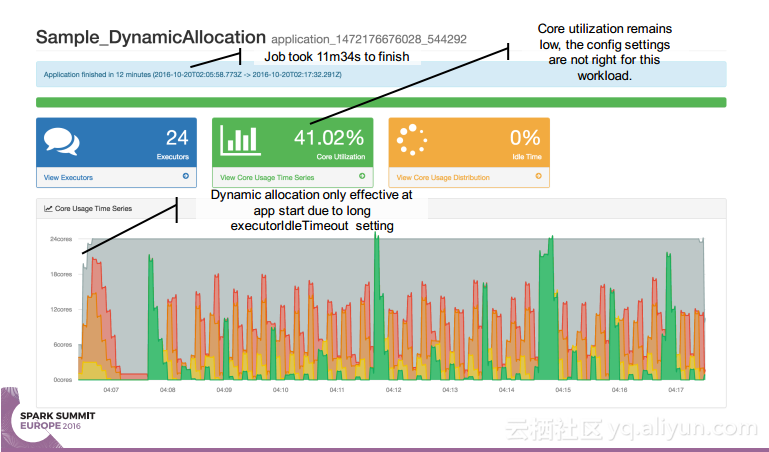
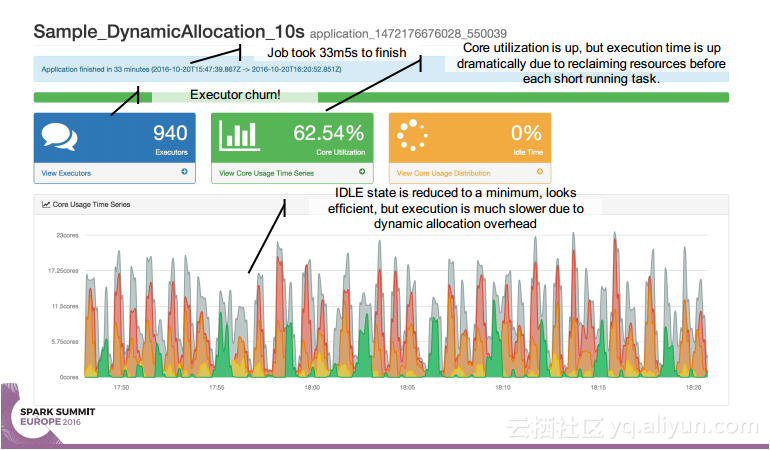
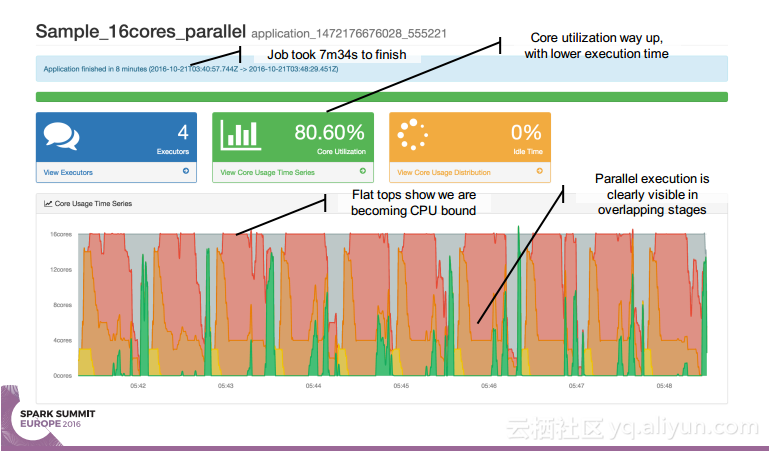
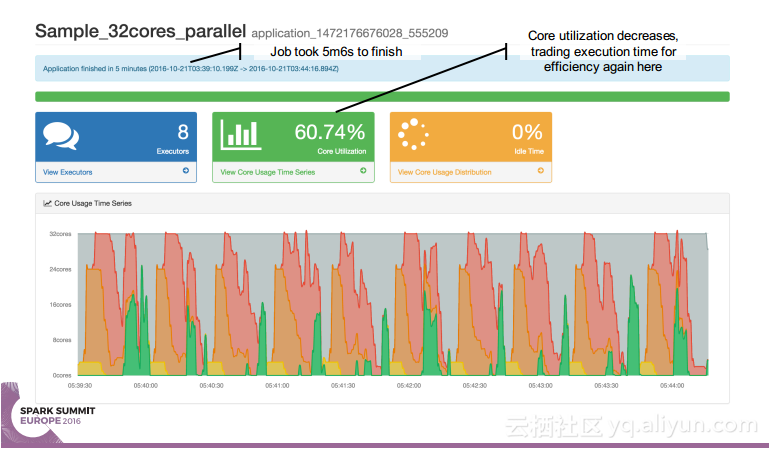
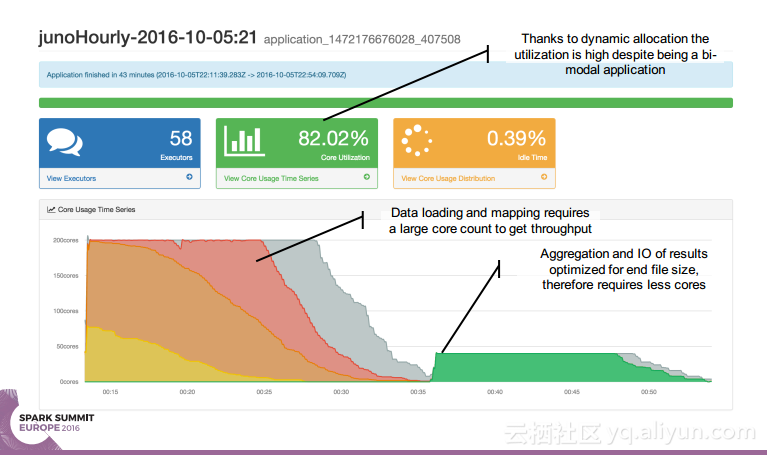
简介:本讲义出自Simon Whitear在Spark Summit EU 2016上的演讲,主要介绍了用于监控,识别并优化低效Spark的工具Sparklint。由于成功的Spark集群的规模往往会迅速扩张,往往会出现能力与任务不匹配的情况并造成资源竞争,为了使得Spark集群的效率得到提升,所以需要Sparklint这样的监控优化工具。
本讲义出自
Simon Whitear在Spark Summit EU 2016上的演讲,主要介绍了用于监控,识别并优化低效Spark的工具Sparklint。由于成功的Spark集群的规模往往会迅速扩张,往往会出现能力与任务不匹配的情况并造成资源竞争,为了使得Spark集群的效率得到提升,所以需要Sparklint这样的监控优化工具。