更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
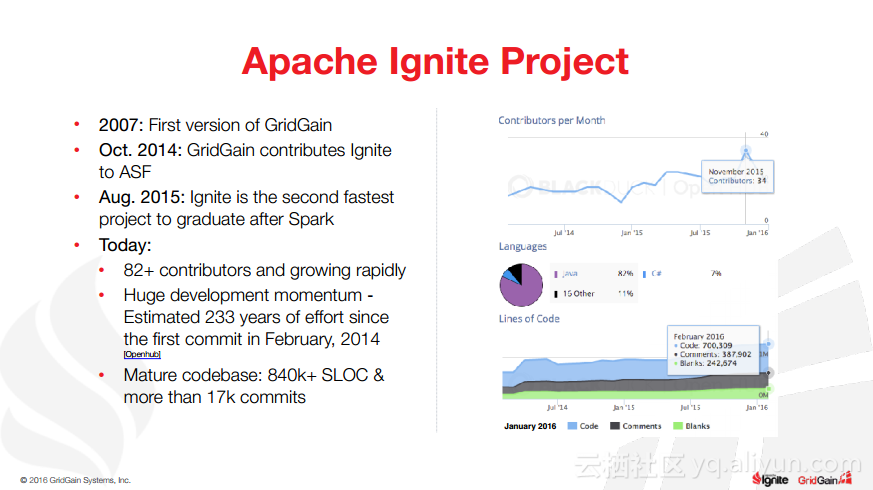
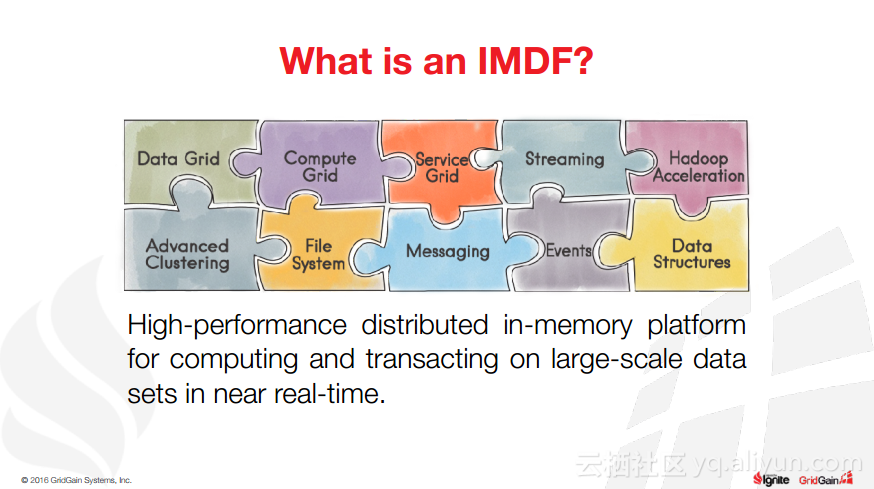
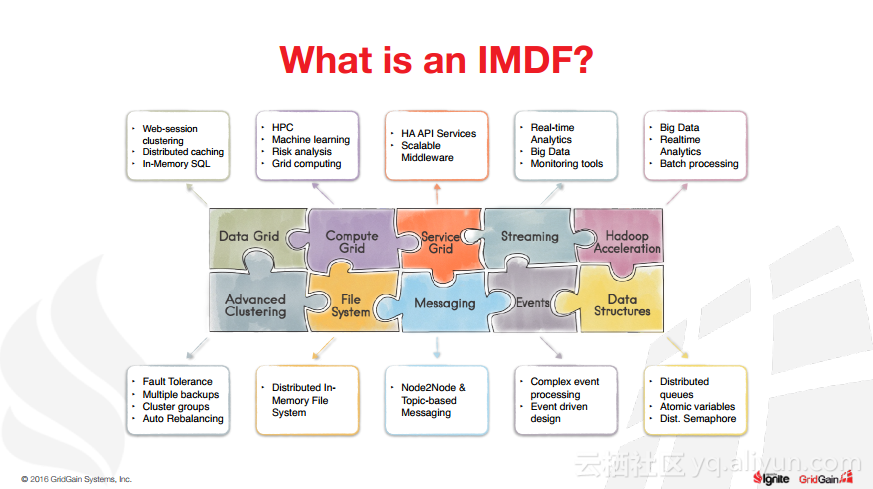
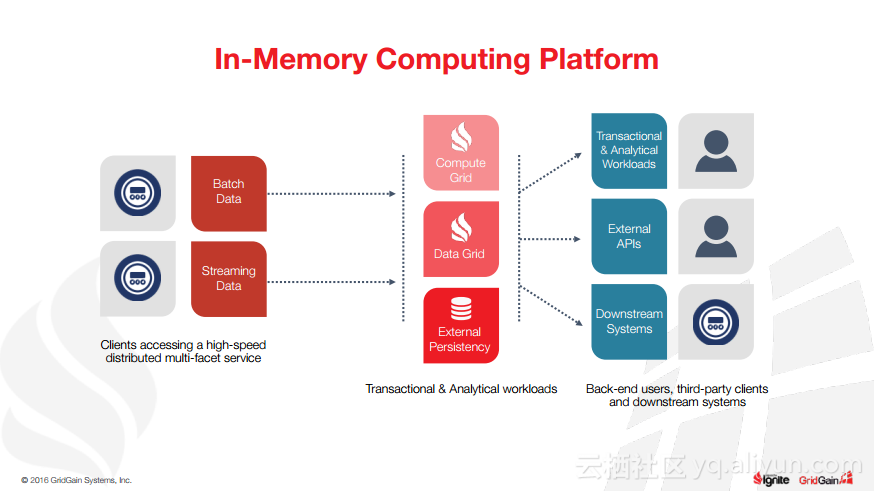
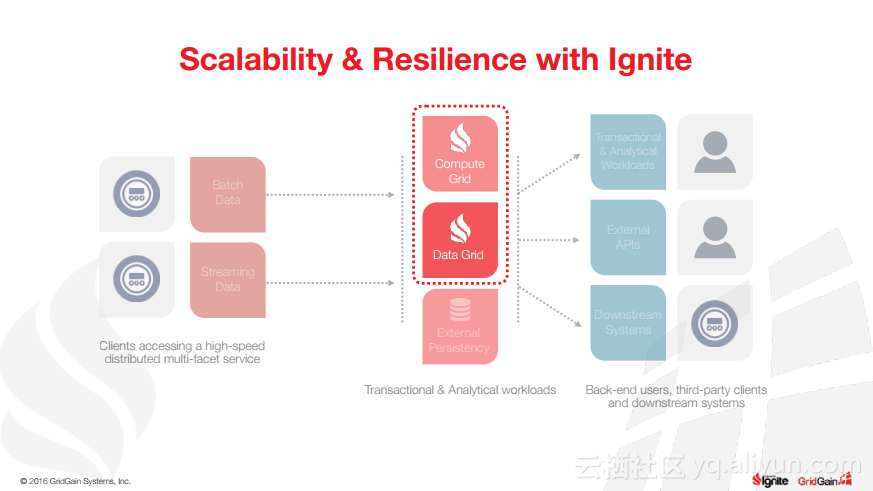
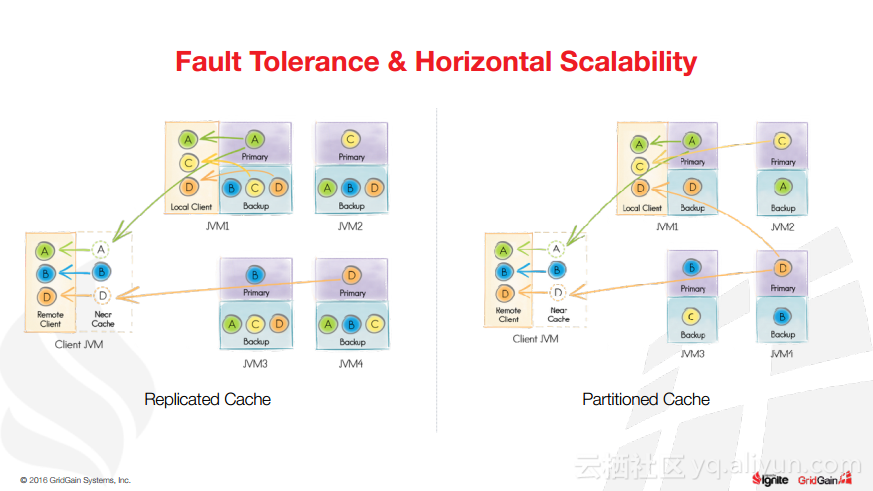
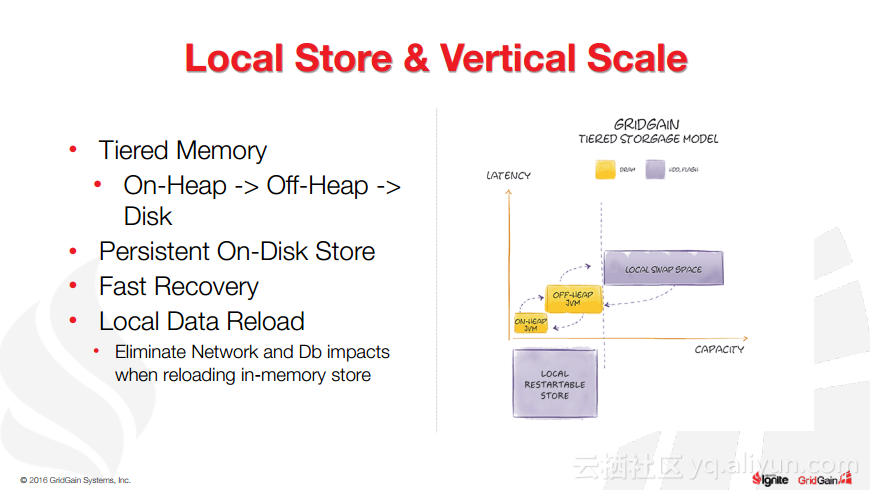
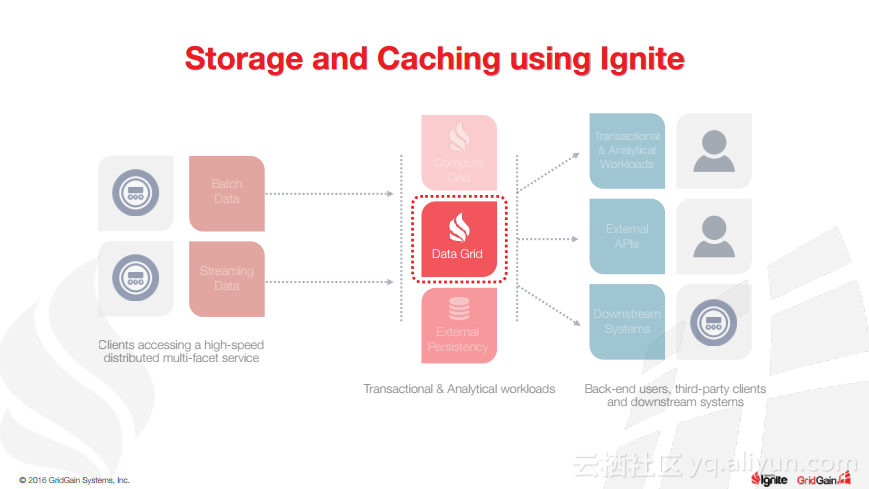
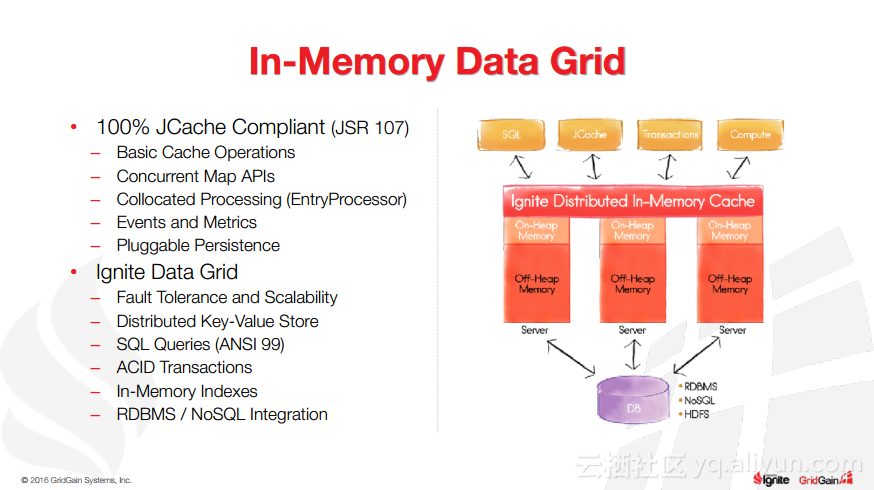
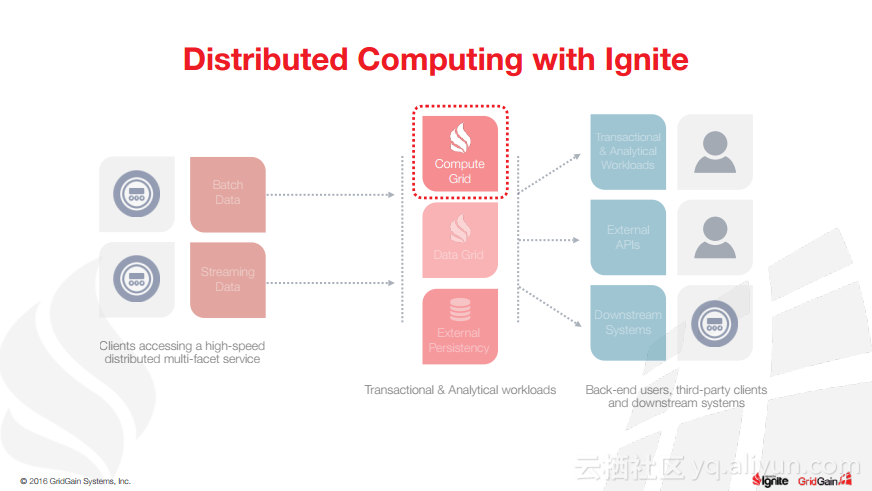
本讲义出自Christos Erotocritou在Spark Summit EU 2016上的演讲,主要介绍了Apache的通用数据库缓存系统——Ignite项目,Apache Ignite允许用户将常用的热数据储存在内存中,它支持分片和复制两种方式,让开发者可以均匀地将数据分布式到整个集群的主机上。同时,Ignite还支撑任何底层存储平台,不管是RDBMS、NoSQL,又或是HDFS。
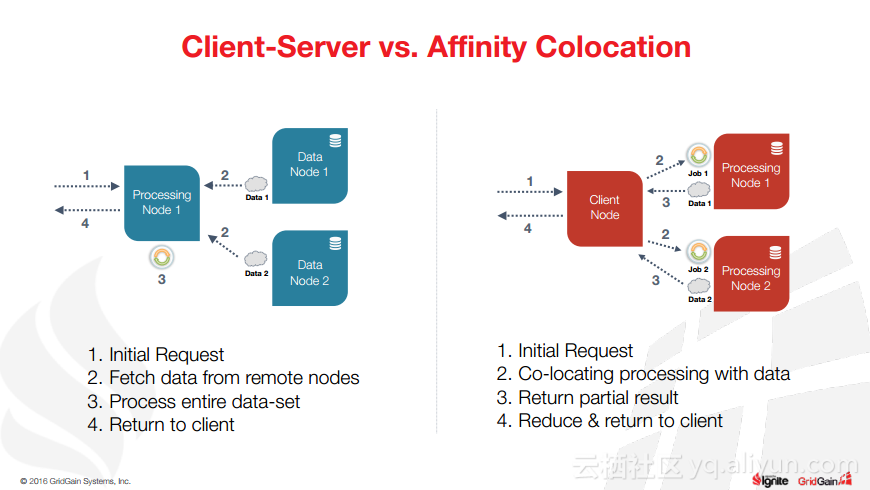
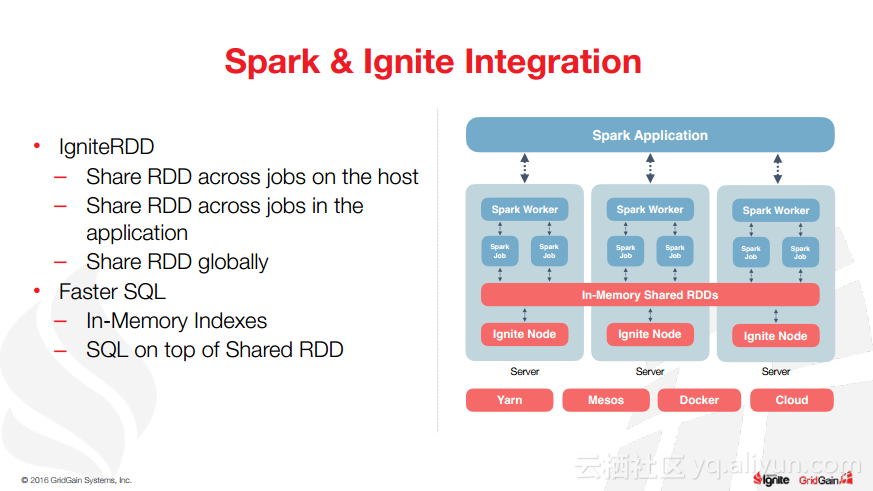
除此之外,Christos Erotocritou还介绍了Hadoop与Spark进行集成以及Spark与Ignite集成,以及内存文件系统等相关内容。