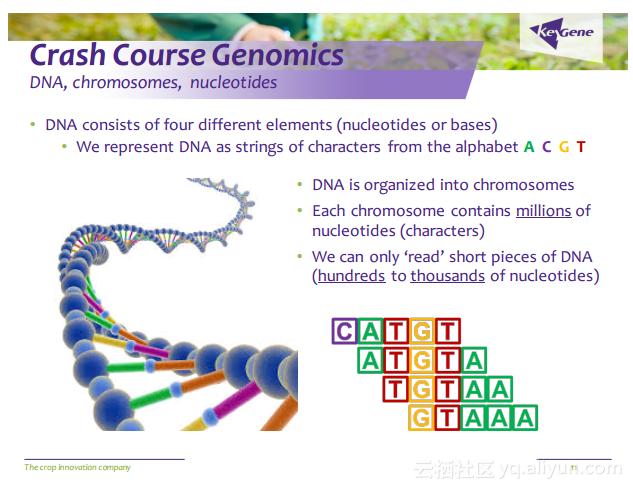
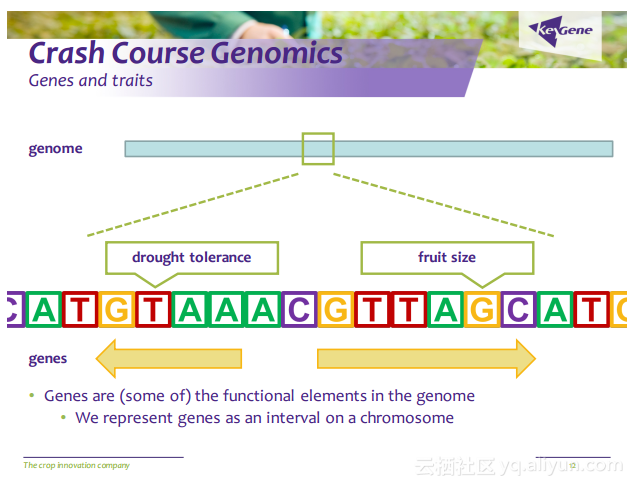
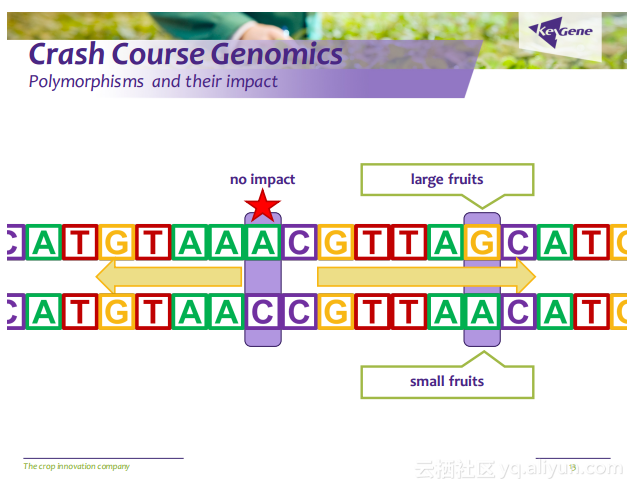
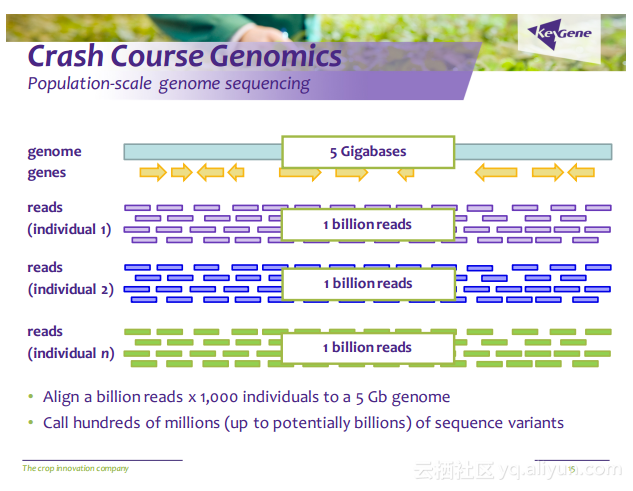
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
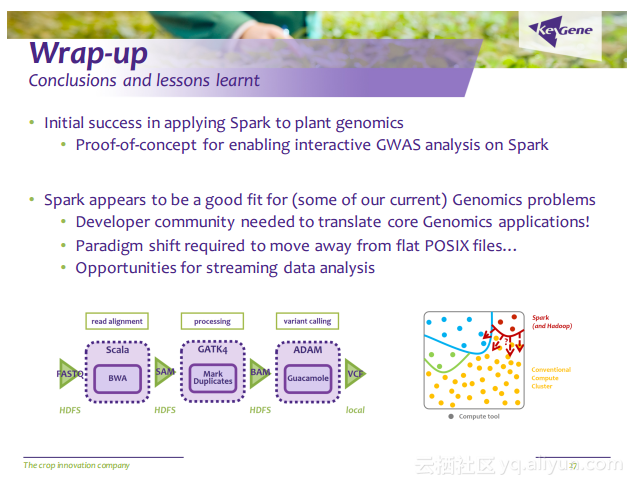
本讲义出自Erwin Datema与Roeland van Ham在Spark Summit EU 2016上的演讲,主要介绍了面对世界人口剧增所带来了粮食危机的巨大挑战,KeyGene公司希望通过基因变异改变农作物的基因来提升农作物的产量,而这一过程需要大数据技术以及高性能计算能力作为支撑,本讲义介绍了如何使用Spark和大数据分析获取农作物的高产量的基因组。