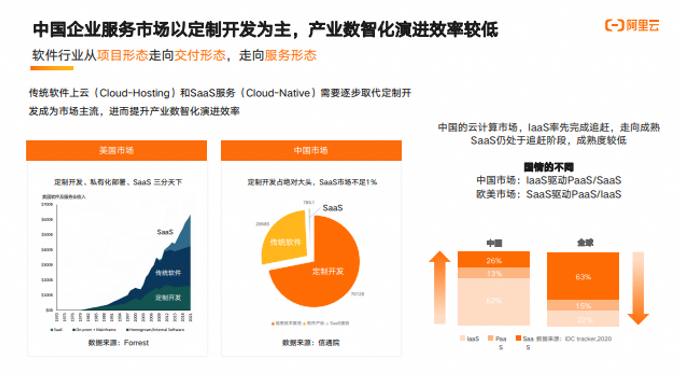
热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
基于深度学习的图像识别技术在自动驾驶系统中的应用
深入理解PHP的命名空间和自动加载机制
Golang深入浅出之-互斥锁(sync.Mutex)与读写锁(sync.RWMutex)
探索机器学习中的维度诅咒与特征工程
构建高效Android应用:Kotlin的协程与Flow
计算巢开发者活动:(一)计算巢产品介绍
探索区块链技术在供应链管理中的应用
Golang深入浅出之-Select语句在Go并发编程中的应用
网络安全与信息安全:保护数字世界的钥匙
深入探索软件自动化测试框架的设计与实现
利用机器学习优化数据中心冷却系统
构建高效Android应用:Kotlin协程的实践之路
万字详述RAG的5步流程和12个优化策略
未来技术纵横谈:区块链、物联网与虚拟现实的融合与创新
Kubernetes 集群的持续性能优化实践
webgl canvas系列——animation中基本旋转、平移、缩放(模拟冒泡排序过程)
固态硬盘分区详细指南
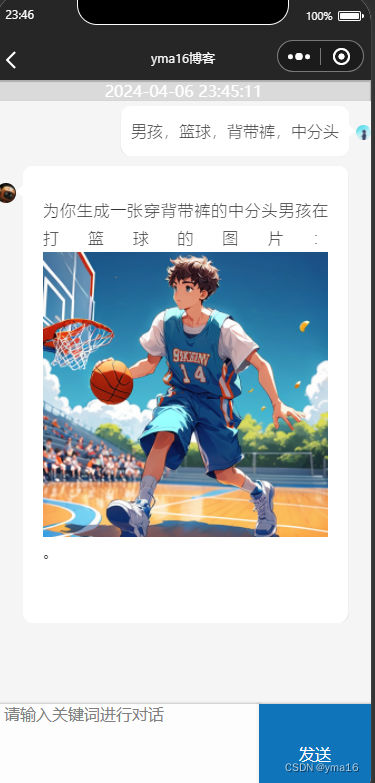
微信小程序——实现对话模式(调用大模型图片生成)
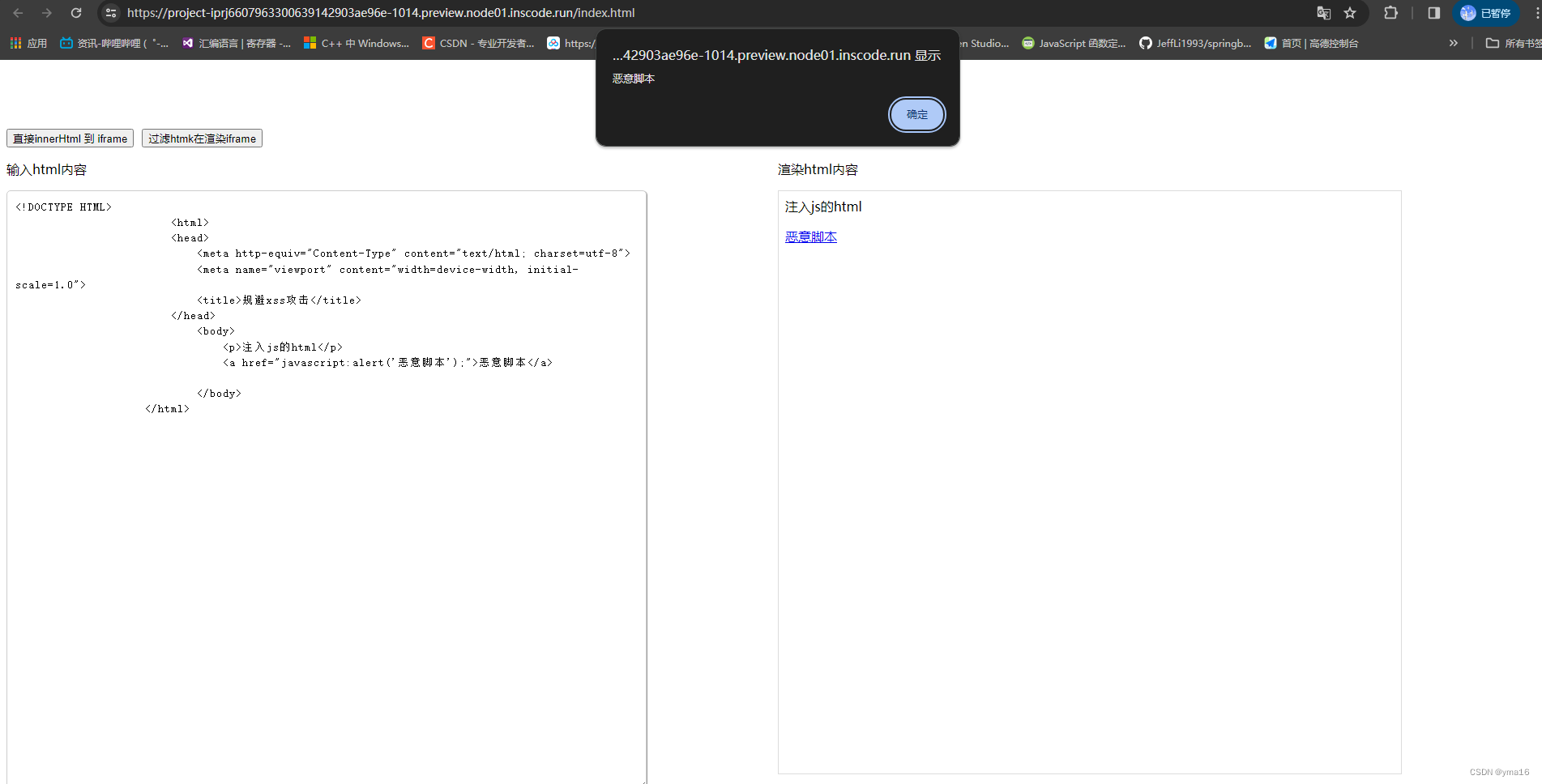
前端xss攻击——规避innerHtml过滤标签节点及属性
webgl canvas系列——快速加背景、抠图、加水印并下载图片
每天解析一个脚本(53)
web canvas系列——快速入门上手绘制二维空间点、线、面
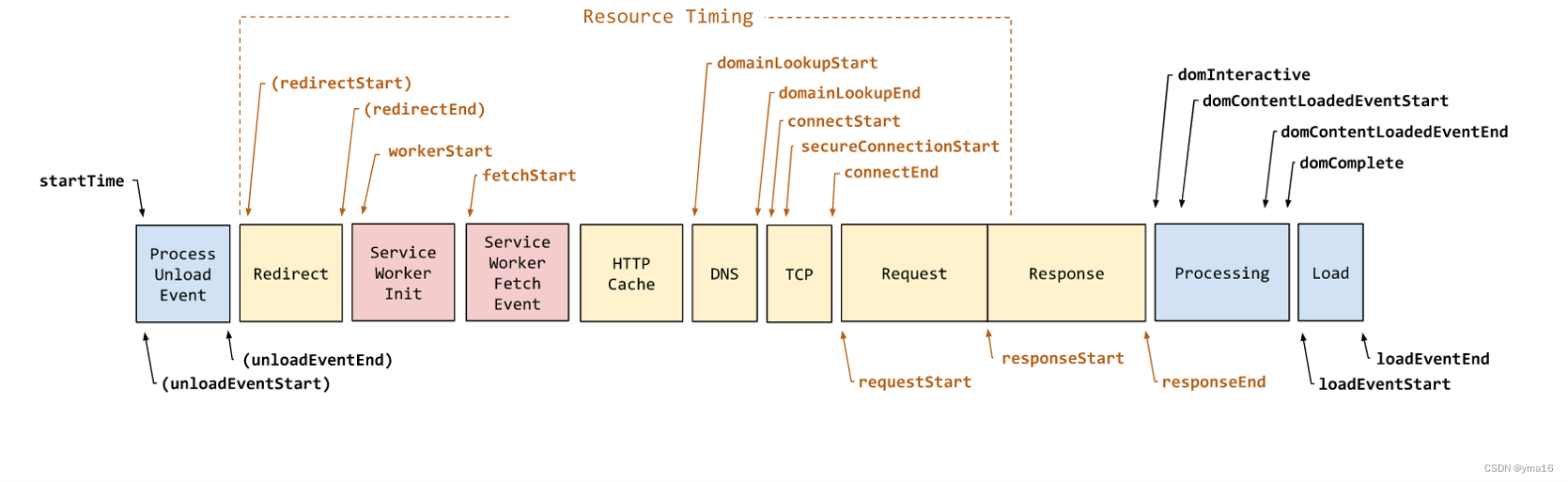
前端vite+vue3——可视化页面性能耗时指标(fmp、fp)
知识图谱算法有哪些
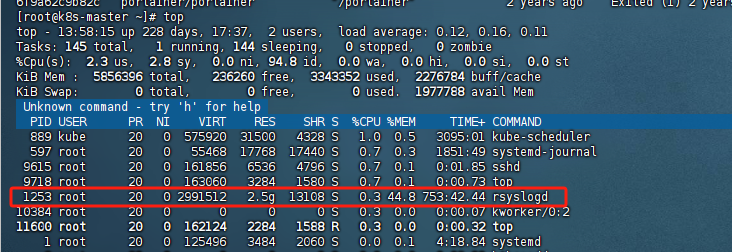
Linux rsyslog占用内存CPU过高解决办法
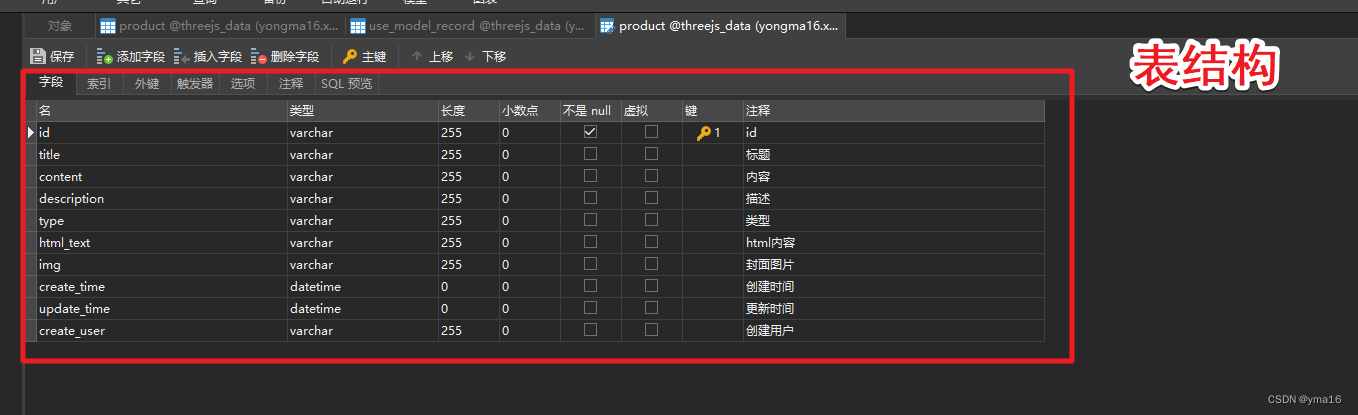
node+vue3+mysql前后分离开发范式——实现视频文件上传并渲染
每天解析一个脚本(52)
node+vue3+mysql前后分离开发范式——实现对数据库表的增删改查
Java Exception打印及输出到日志
前端vite+vue3结合后端node+koa——实现代码模板展示平台(支持模糊搜索+分页查询)
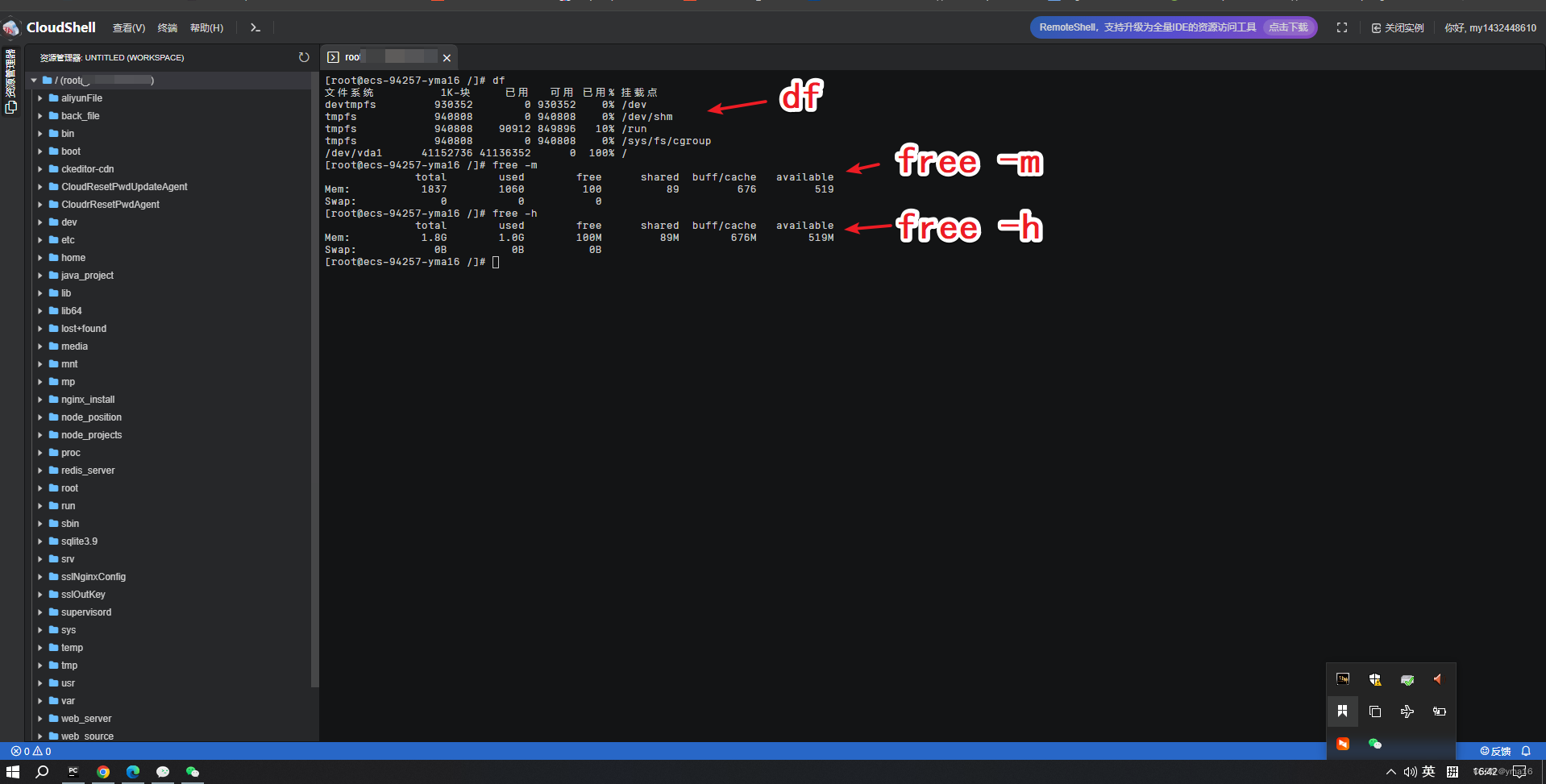
linux优化空间&完全卸载mysql——centos7.9
万字综述:2023年多模态检索增强生成技术(mRAG)最新进展与趋势-图片、代码、图谱、视频、声音、文本
每天解析一个脚本(51)
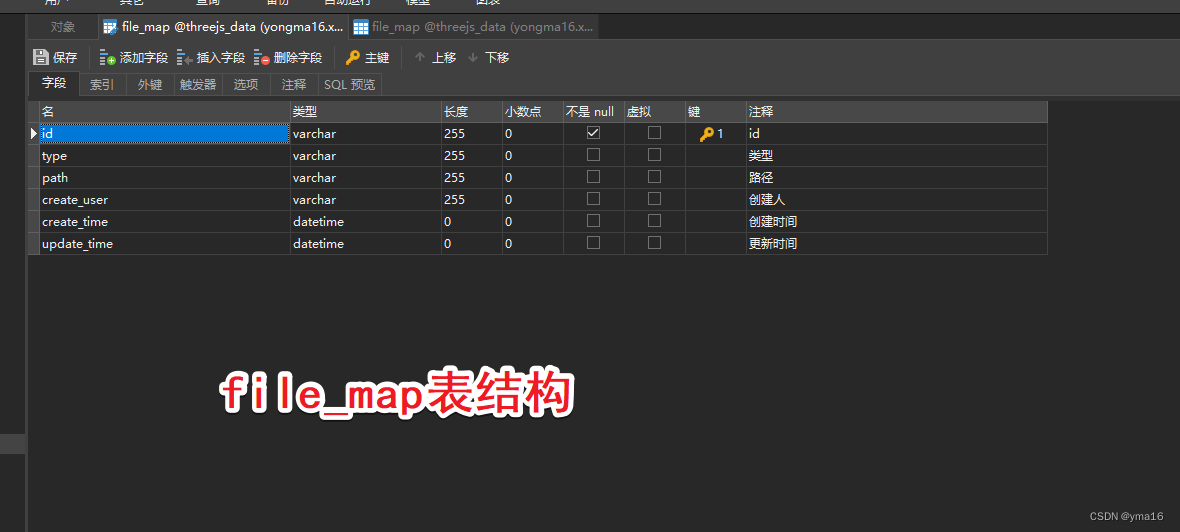
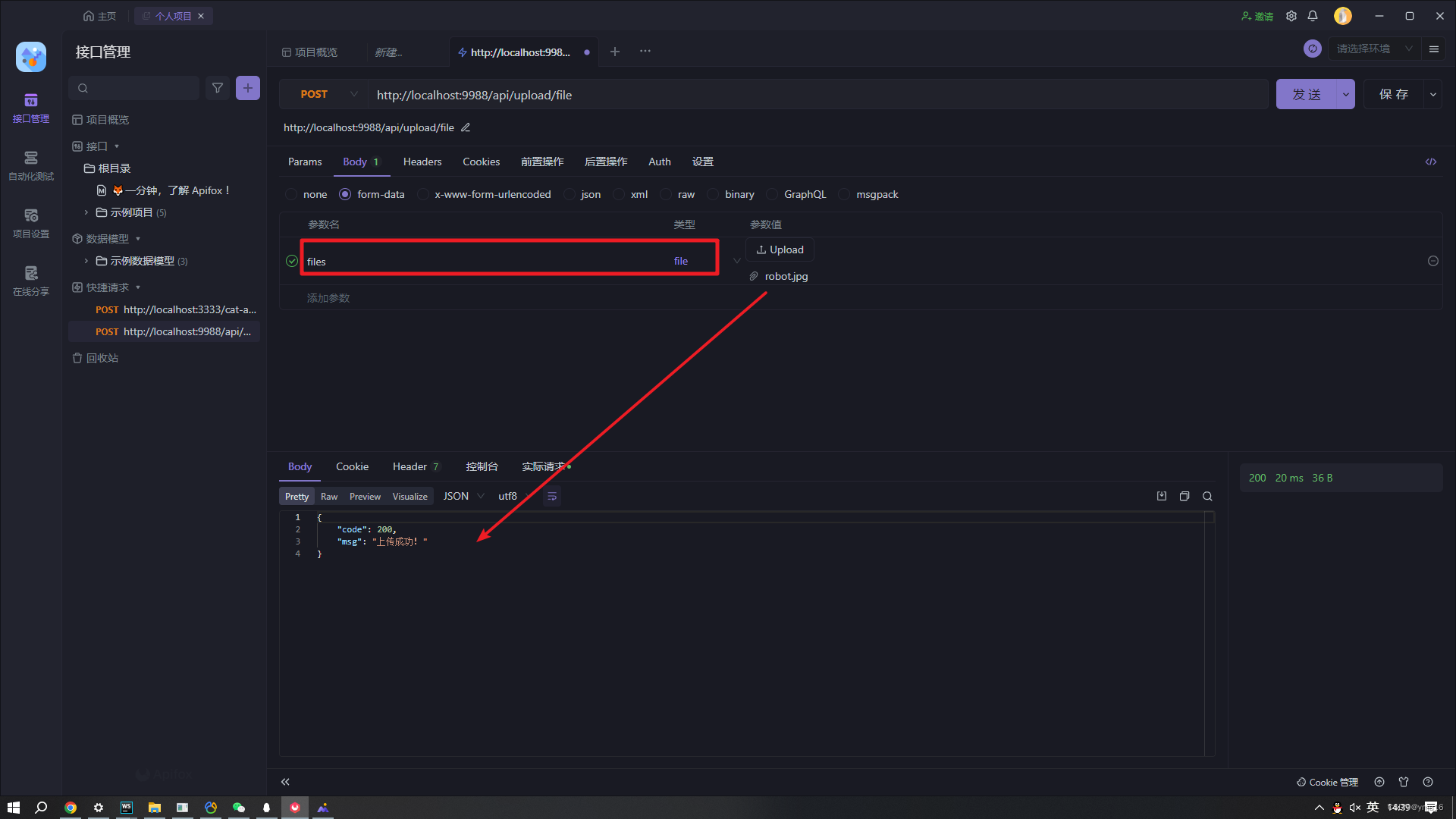
vue3+threejs+koa可视化项目——模型文件上传(第四步)
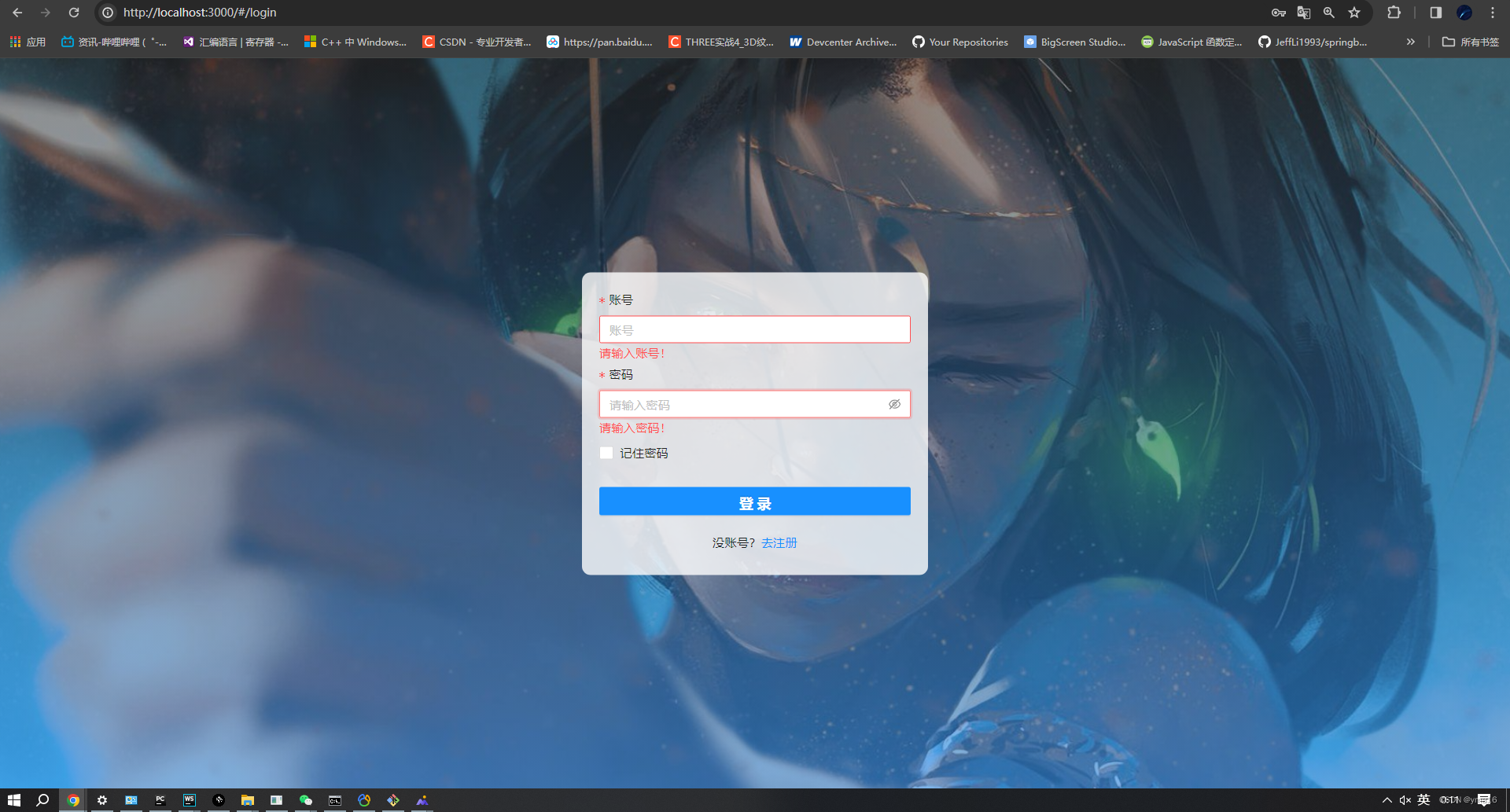
vue3+threejs+koa可视化项目——实现登录注册(第三步)
深入学习Synchronized各种使用方法
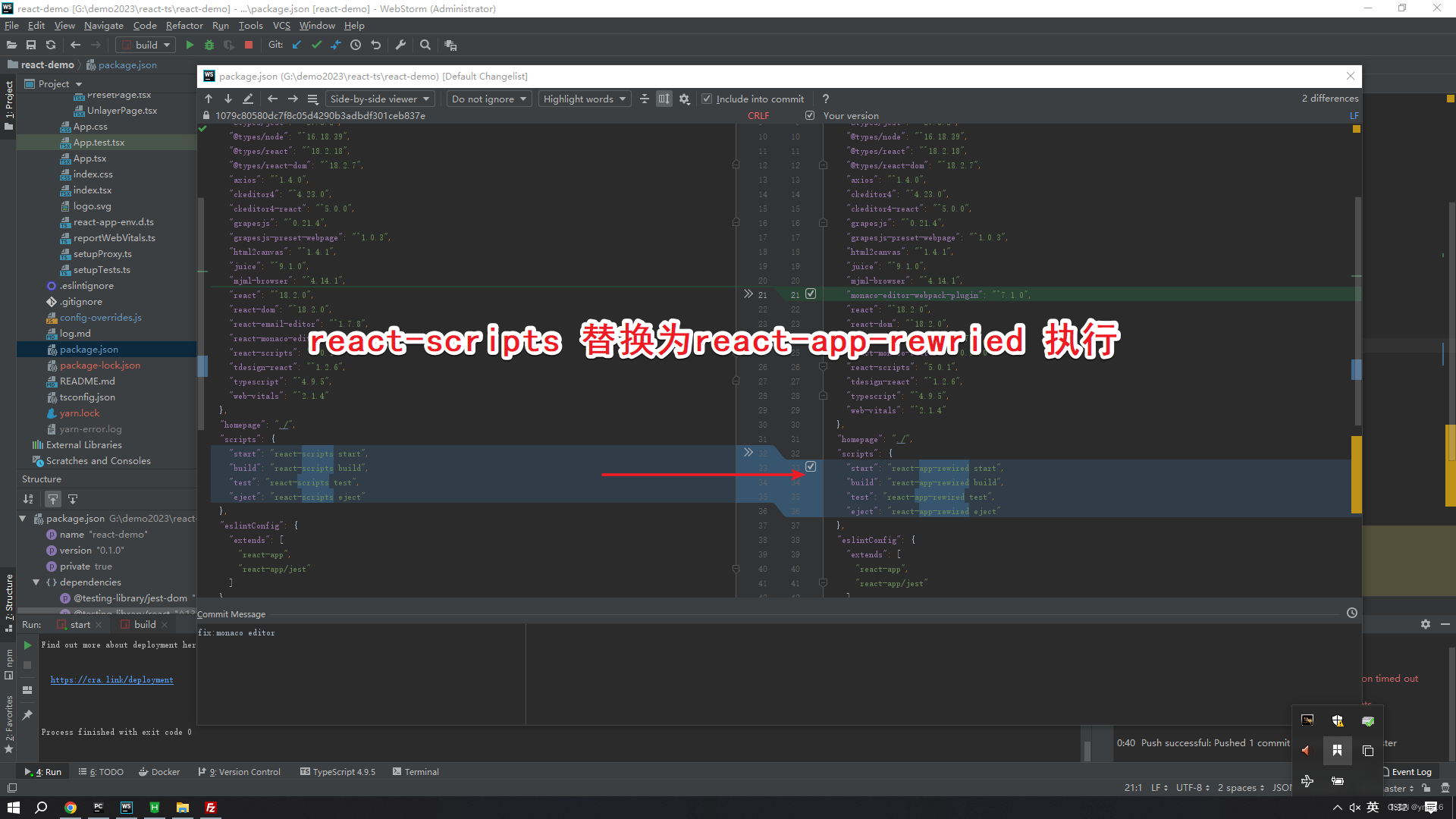
react-app框架——使用monaco editor实现online编辑html代码编辑器
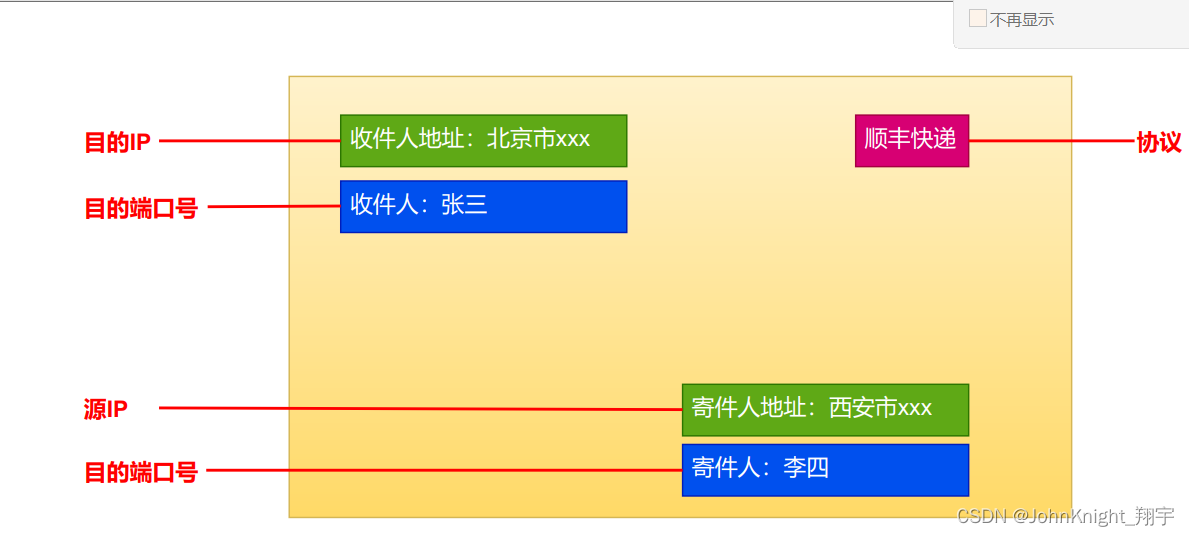
TCP/IP五层(或四层)模型,IP和TCP到底在哪层?
ISO 专家解读 | 什么是 GQL 国际标准图查询语言
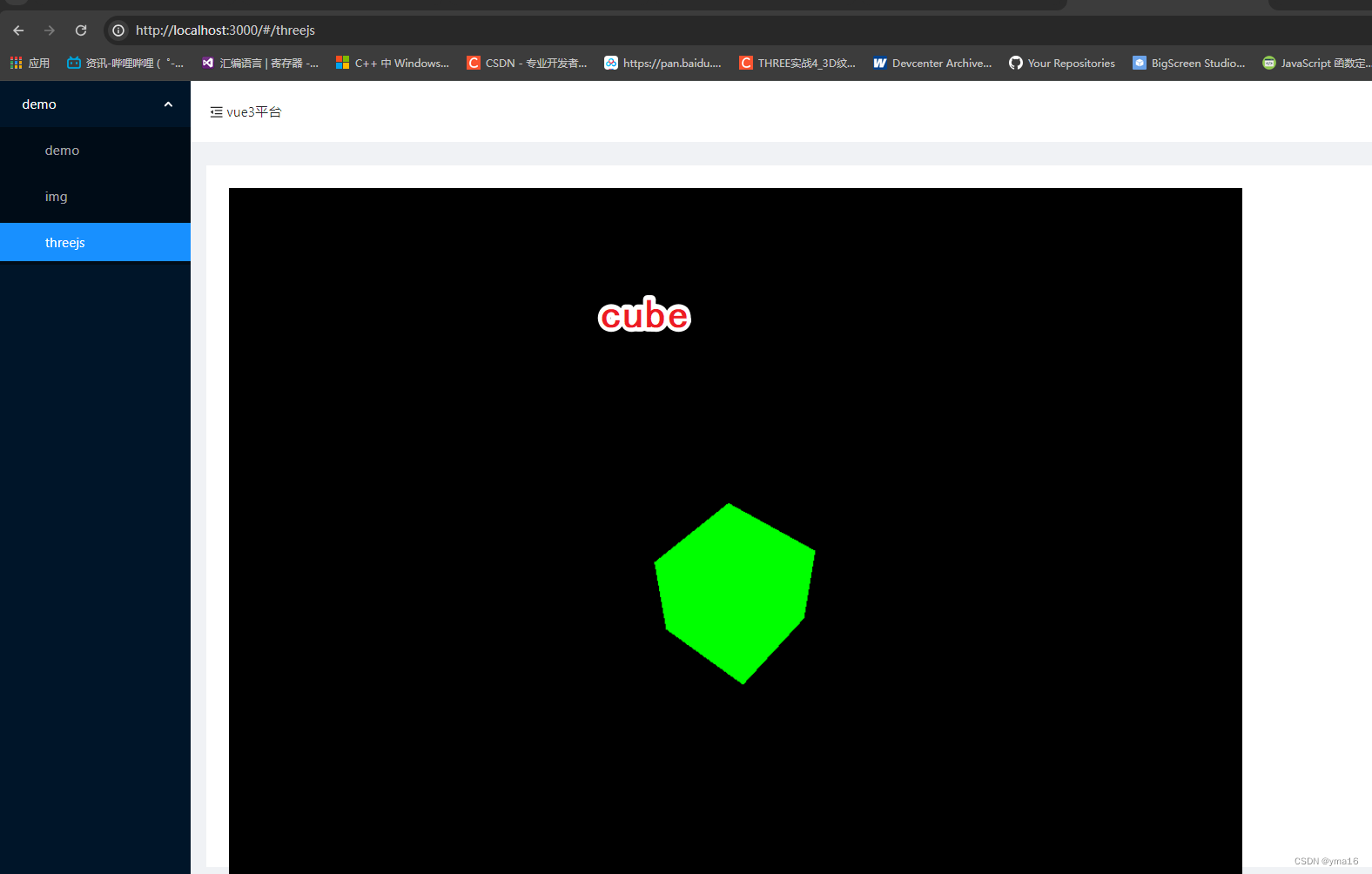
vue3+threejs可视化项目——引入threejs加载钢铁侠模型(第二步)
网络初识:局域网广域网&网络通信基础
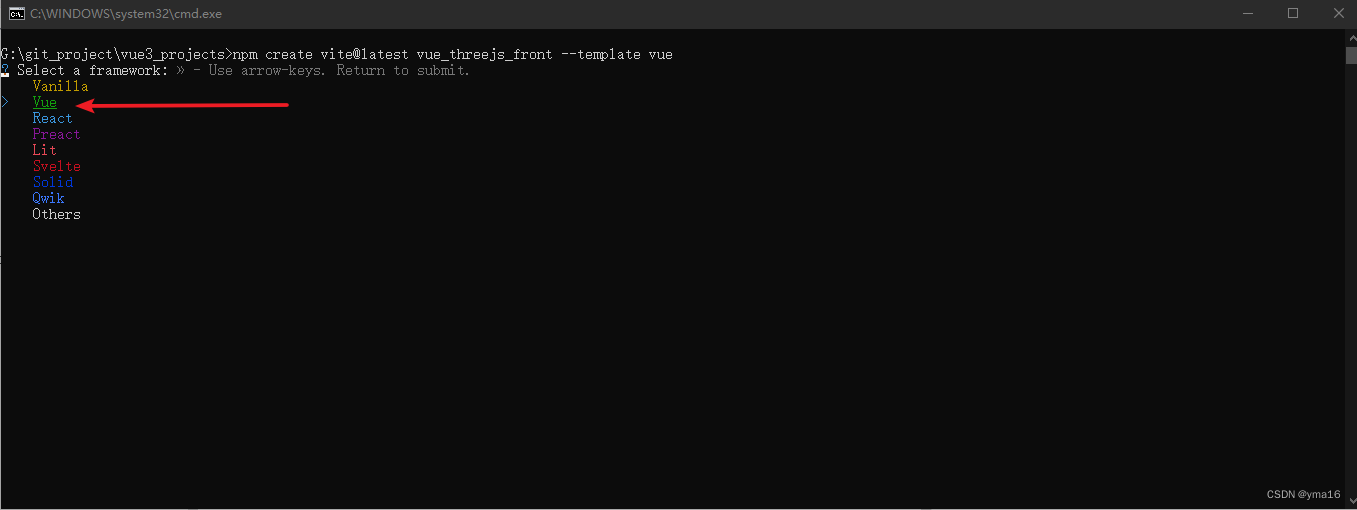
vue3+threejs可视化项目——搭建vue3+ts+antd路由布局(第一步)
前端舞台上的优雅独舞:代码规范的奥秘
SpringBoot:SpringMVC(上)
前端宝藏图:寻找技术之旅的星辰大海
VueX解耦:前端开发的音乐大师