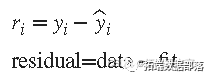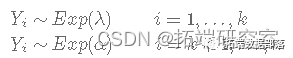热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
python|闲谈2048小游戏和数组的旋转及翻转和转置
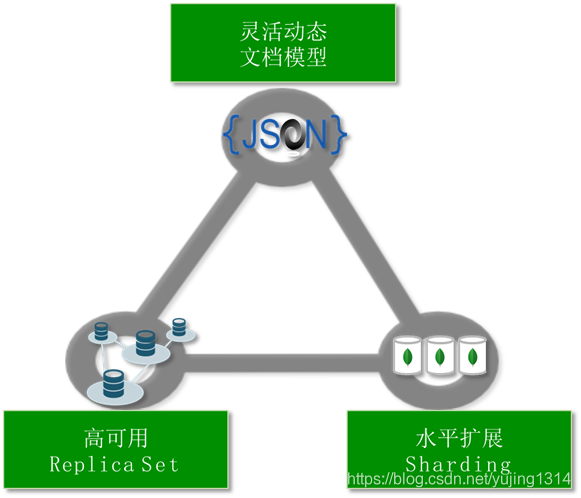
MongoDB的简介和安装(在服务器上)
ECS使用体验
JavaScrip基础(三)
阿里云ECS的使用心得
计算思维学习总结(一)
JavaScrip基础(二)
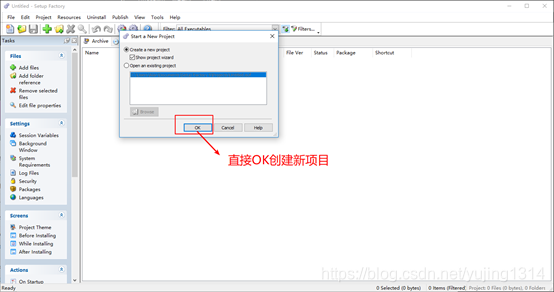
setup facatory9.0打包详细教程(含静默安装和卸载)
python 和shell 变量互相传递
VulnHub 靶场--super-Mario-Host超级马里奥主机渗透测试过程
基于Vulnhub—DC8靶场渗透测试过程
MySQL字段的时间类型该如何选择?千万数据下性能提升10%~30%🚀
外贸企业邮箱解析:通向全球市场的邮件之路
C# 如何使用倒计时
基于Vulnhub靶场—DC4渗透测试过程
JavaScrip基础(一)
【SpringBoot系列】微服务集成Flyway
Windows环境下安装nc工具
为什么要用SOCKS5代理?有什么优势?
:“You have an error in your SQL syntax; check the manual that corresponds to your MySQL server versi
【机房合作】之单例模式的实现
nc简单反弹shell
SOCKS/SOCKS5代理协议是什么
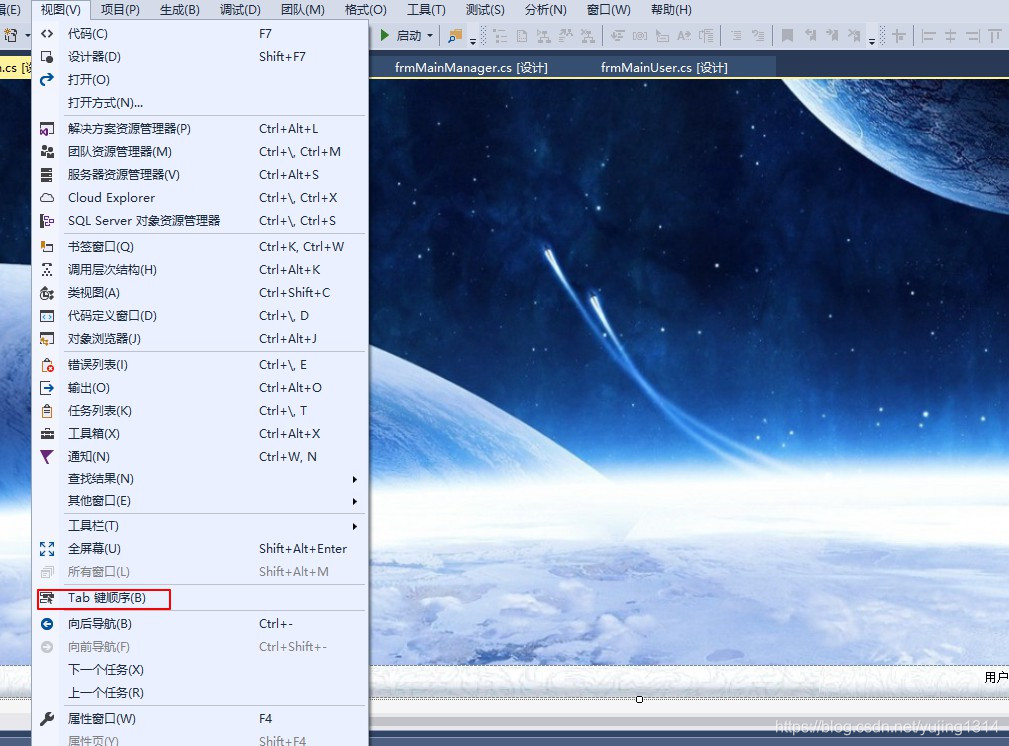
【VS2017】怎么调整Tab键的顺序和回车直接登录
渗透测试常用名词术语介绍
:“DELETE 语句与 REFERENCE 约束"FK_news_category"冲突
System.InvalidOperationException: WebForms UnobtrusiveValidationMode 需要“jquery”ScriptResourceMappin
Kali Linux配置阿里源
如何检测本地网络是否稳定
NP19 列表的长度
MATLAB最小二乘法:线性最小二乘、加权线性最小二乘、稳健最小二乘、非线性最小二乘与剔除异常值效果比较
C# 文本框限制大全
潜力与限制:低代码开发平台优缺点全面分析
【牛客网算法】NP18 生成数字列表(语法)
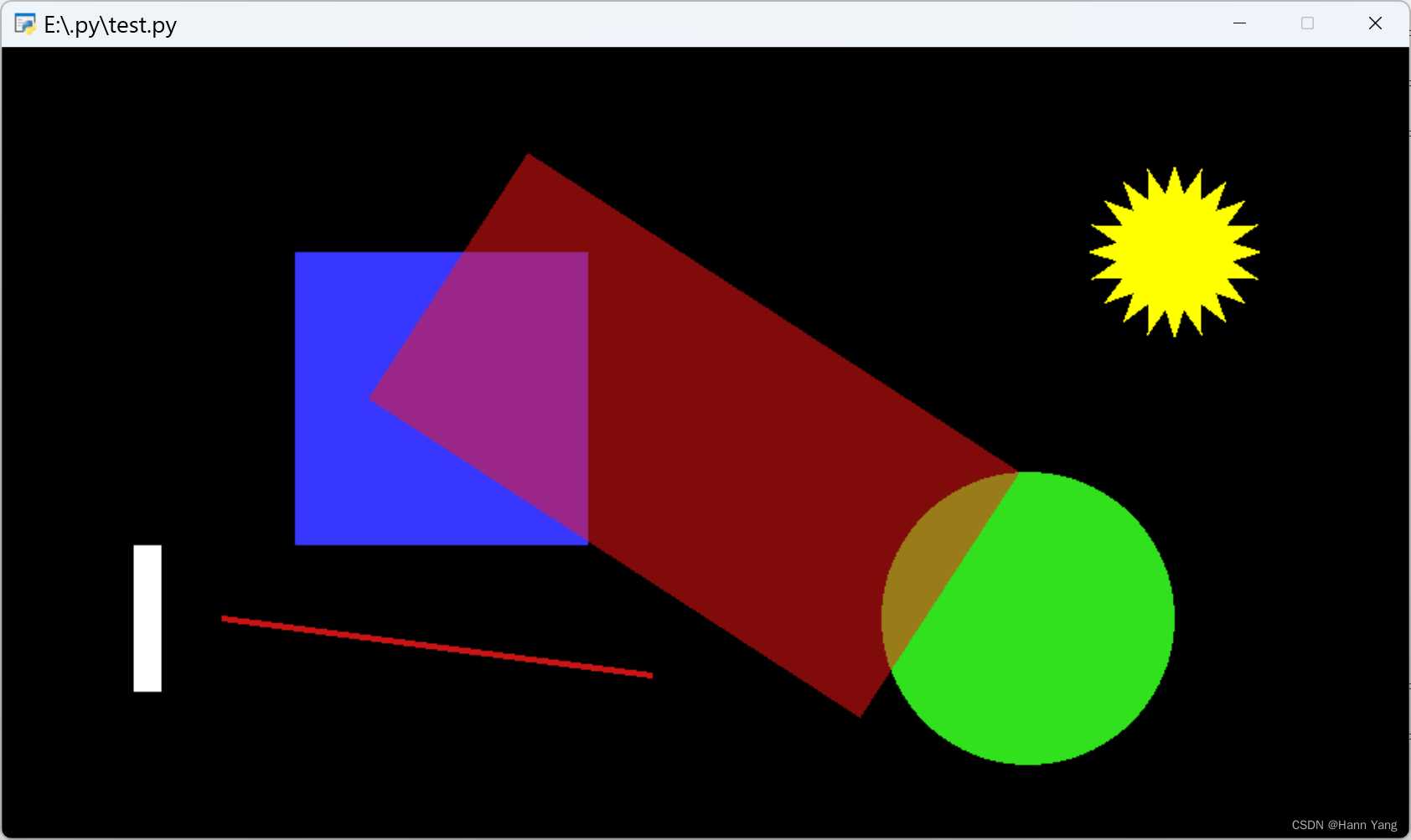
Pyglet shaps形状控件的种类和用法(共12种)
Kubernetes 集群的监控与维护策略
利用HttpClient库下载蚂蜂窝图片
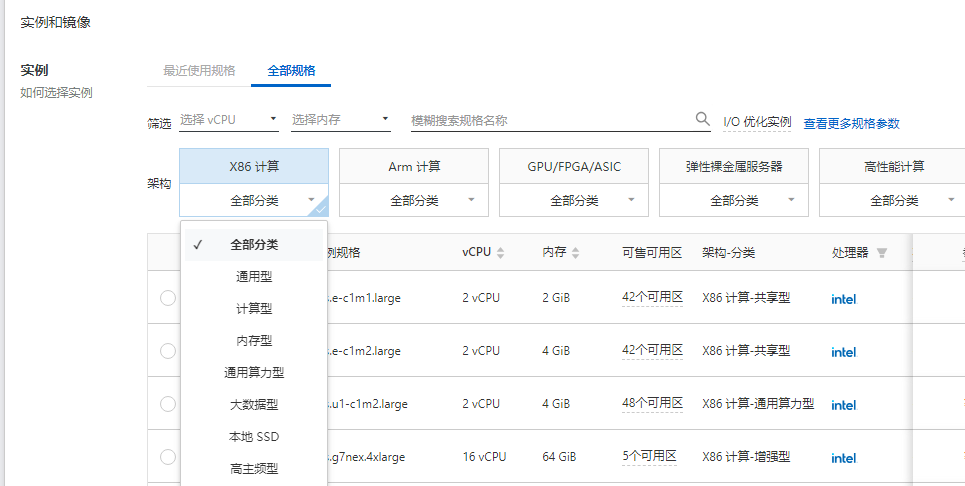
阿里云企业级云服务器实例、云盘、带宽、镜像选择参考
R语言贝叶斯METROPOLIS-HASTINGS GIBBS 吉布斯采样器估计变点指数分布分析泊松过程车站等待时间
Pyglet控件的批处理参数batch和分组参数group简析
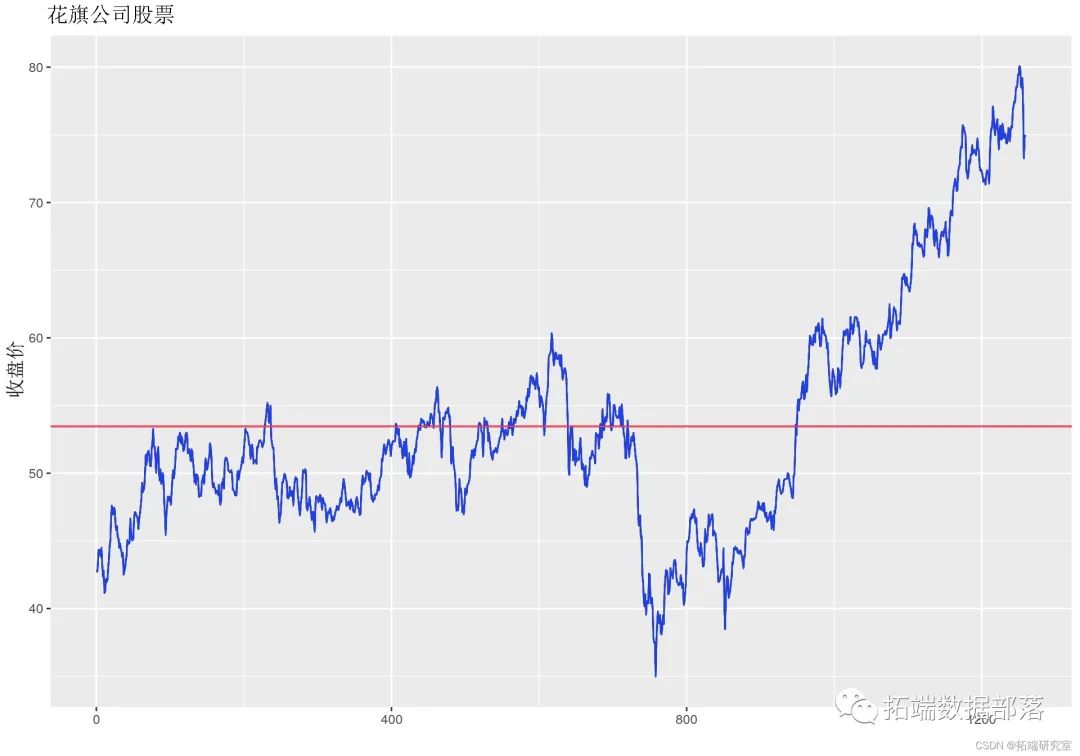
R语言风险价值:ARIMA,GARCH,Delta-normal法滚动估计VaR(Value at Risk)和回测分析股票数据
TypeScript基础知识点
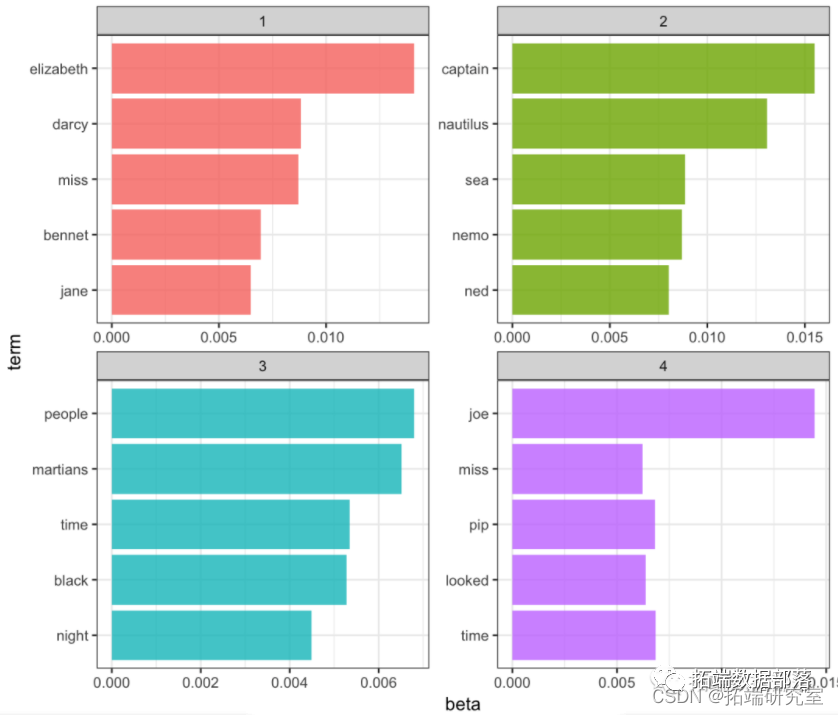
R语言之文本分析:主题建模LDA
Spring5深入浅出篇:Spring切入点详解
解放生产力:项目管理软件的神奇作用大揭秘!